文章情感的分析方法和裝置與流程
本發明涉及信息處理技術領域,特別是涉及文章情感的分析方法和裝置。
背景技術:
隨著互聯網的迅猛發展,互聯網上出現的文章數量也是越來越多。人們在工作的過程中有時候需要一篇或多篇文章的情感傾向,面對浩瀚的網絡文章,依靠人工評判難以做到及時響應,通過計算機來實現文章情感分析的技術也應運而生。
傳統的情感分析的方法,通常都是對每個詞語設置了固定的情感數值,情感數值體現出了該詞語的情感色彩,比如為負面情感或正面情感。然后根據組成一篇文章的每個詞語的情感數值進行簡單的疊加,即得到了該文章所表達的情感。然而由于語言的復雜性,同樣的詞語用在不同的語言環境或與不同的詞語的組合,所表達的情感也不盡相同。因此,傳統的文章情感分析的方法所分析出的文章所表達的情感的準確性不高。
技術實現要素:
基于此,有必要針對上述技術問題,提供一種能夠提高文章的情感分析的準確性的文章情感的分析方法和裝置。
一種文章情感的分析方法,所述方法包括以下步驟:
獲取待分析的文章;
對所述文章中的內容進行詞句切分,生成對應數量的詞句;
根據所述詞句確定所述文章描述的主體;
獲取每個詞句的特征向量;
根據每個詞句的特征向量計算所述文章對所述主體的描述的情感強度。
在其中一個實施例中,所述獲取每個詞句的特征向量的步驟,包括:
對切分后的詞句進行篩選,獲取篩選后的詞句的特征向量;
所述根據每個詞句的特征向量計算所述文章對所述主體的描述的情感強度的步驟,包括:
根據篩選后的詞句的特征向量計算所述文章對所述主體的描述的情感強度。
在其中一個實施例中,所述獲取每個詞句的特征向量的步驟,包括:
當獲取不到所述詞句的特征向量時,檢測預設的詞庫中是否存在與所述詞句相近的詞句,若是,則獲取該相近詞句的特征向量,將其作為該詞句的特征向量,若否,則將預設的默認特征向量作為所述詞句的特征向量。
在其中一個實施例中,所述根據每個詞句的特征向量計算所述文章對所述主體的描述的情感強度的步驟,包括:
根據每個詞句的特征向量計算對應文章的特征向量;
根據所述文章的特征向量計算出所述文章的情感數值;
根據所述文章的感情數值確定所述文章對所述主體的描述的情感強度。
在其中一個實施例中,所述根據所述文章的特征向量計算出所述文章的情感數值的步驟,包括:
重復預設次數,從文章的特征向量中隨機選取第一數量的參數,構成對應的第二數量的子向量;
計算每個子向量對應的子情感數值,根據每個子情感數值計算所述文章的情感數值。
在其中一個實施例中,所述方法還包括:
獲取主體相同的文章的情感強度,計算相同主體的綜合情感強度。
一種文章情感的分析裝置,所述裝置包括:
文章獲取模塊,用于獲取待分析的文章;
詞句切分模塊,用于對所述文章中的內容進行詞句切分,生成對應數量的詞句;
主體確定模塊,用于根據所述詞句確定所述文章描述的主體;
特征向量獲取模塊,用于獲取每個詞句的特征向量;
情感強度計算模塊,用于根據每個詞句的特征向量計算所述文章對所述主體的描述的情感強度。
在其中一個實施例中,所述情感強度計算模塊還用于根據每個詞句的特征向量計算對應文章的特征向量;根據所述文章的特征向量計算出所述文章的情感數值,根據所述文章的感情數值確定所述文章對所述主體的描述的情感強度。
在其中一個實施例中,所述情感強度計算模塊還包括:
子向量構建單元,用于重復預設次數,從文章的特征向量中隨機選取第一數量的參數,構成對應的第二數量的子向量;
情感數值計算單元,用于計算每個子向量對應的子情感數值,根據每個子情感數值計算所述文章的情感數值。
在其中一個實施例中,所述裝置還包括:
綜合情感強度計算模塊,用于獲取主體相同的文章的情感強度,計算相同主體的綜合情感強度。
上述文章情感的分析方法和裝置,通過預先設置每個詞句的特征向量,并對文章進行詞句切分,以確定文章的描述主體,然后根據所切分的詞句的特征向量,計算出該文章對主體的描述的情感強度。相比于傳統的通過每個詞語對應的固定數值來計算文章的情感強度,本實施例所提供的文章情感的分析方法,所計算出的文章所表達的情感強度的準確性更高。
附圖說明
圖1為一個實施例中用于執行文章情感的分析方法的服務器或終端的內部結構示意圖;
圖2為一個實施例中文章情感的分析方法的流程圖;
圖3為一個實施例中根據每個詞句的特征向量計算文章對主體的描述的情感強度的步驟的流程圖;
圖4為一個實施例中根據文章的特征向量計算出文章的情感數值的步驟的流程圖;
圖5為另一個實施例中文章情感的分析方法的流程圖;
圖6為一個實施例中文章情感的分析裝置的結構框圖;
圖7為一個實施例中情感強度計算模塊的結構框圖;
圖8為另一個實施例中文章情感的分析裝置的結構框圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
在一個實施例中,如圖1所示,為一個終端或服務器或終端的內部結構示意圖。該服務器或終端包括通過系統總線連接的處理器、非易失性存儲介質和內存儲器。其中,服務器的非易失性存儲介質存儲有操作系統和數據庫,還包括一種文章情感的分析裝置。數據庫用于存儲于實現一種文章情感的分析方法相關的數據,包括存儲預先建立的詞句的語義數據等,文章情感的分析裝置用于實現一種文章情感的分析方法。該處理器用于提供計算和控制能力,支撐整個服務器的運行。服務器中的內存儲器為非易失性存儲介質中的文章情感的分析裝置的運行提供環境,該內存儲器中可儲存有計算機可讀指令,該計算機可讀指令被處理器執行時,可使得處理器執行一種文章情感的分析方法。本領域技術人員可以理解,圖1中示出的結構,僅僅是與本申請方案相關的部分結構的框圖,并不構成對本申請方案所應用于其上的服務器的限定,具體的服務器可以包括比圖中所示更多或更少的部件,或者組合某些部件,或者具有不同的部件布置。
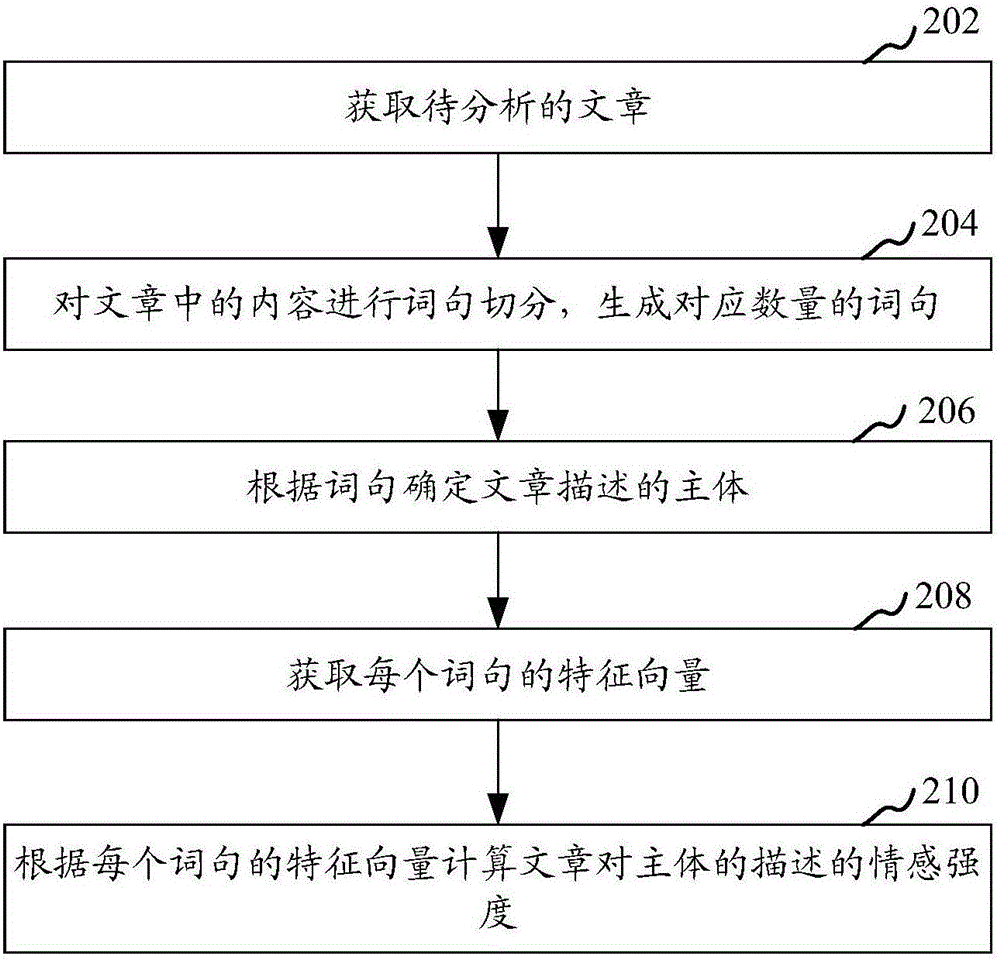
在一個實施例中,如圖2所示,提供了一種文章情感的分析方法,該方法可應用與如圖1所示的服務器或終端中,包括以下步驟:
步驟202,獲取待分析的文章。
本實施例中,可從預先設置好的一個或多個網站中獲取其所公布的文章,或者直接讀取預先準備好的文章,將所獲取到的準備分析其所表達的情感的文章。待分析的文章可以是中文文章,也可以是英文文章等。其中,待分析的文章包括文章標題與文章正文,還包括作者、發表時間以及章節以及文章等其中的一種或多種。文章所表達的情感包括正面情感、負面情感以及中立的情感。
步驟204,對文章中的內容進行詞句切分,生成對應數量的詞句。
本實施例中,預先建立了詞句的語義數據庫,該語義數據庫中包含了大量的詞句(即詞語和句子)。終端或服務器可根據文章所屬語言,按照相應的語法樹的規則,并結合語義數據庫中所記錄的句子,將文章中的每個句子切分成相應數量的詞句。并確定每個詞語在該句子中的詞性以及在文章中所處的位置,比如確定某個詞語為名詞,并為該句子中的主語。詞句在文章中所處的位置包括處于標題、處于文章正文中、處于章節的題目中、文章作者、發表時間等。
在一個實施例中,在進行詞句切分的過程中,若一個句子中的連續排列在一塊的多個詞語,在數據庫中對應存在一個完整的詞語,則將該多個詞語組成一個詞語,使切割后的詞句保持一個整體。
舉例來說,比如存在一個句子如下“平安科技有限公司……”,則在進行詞句切分的時候,“平安”、“科技”、“公司”這些都可作為一個獨立的詞語,若數據庫中保存了一個獨立的詞語為“平安科技有限公司”,則將該句子中的“平安科技有限公司”保留為一個整體,使其不再進行進一步切分。
步驟206,根據詞句確定文章描述的主體。
本實施例中,可根據切分后的詞句的詞性以及在文章中所處的位置來確定該文章描述的主體。可直接對文章標題進行語法分析邏輯判斷,將標題的主語作為文章描述的主體。還可進一步根據語法分析邏輯分析每個句子的主語,統計具有相同含義的主語的詞語的出現次數,將統計出的出現的次數最多的具有相同含義的詞語所表示的含義作為文章描述的主體。
舉例來說,若一篇文章中,出現“平安科技”、“平安公司”以及“平安公司總裁”這三個主語,則可將上述的三個主語識別為表示具有相同含義的主語的詞語,其描述的主體均為“平安科技有限公司”。
步驟208,獲取每個詞句的特征向量。
本實施例中,語義數據庫中還進一步設置了每個詞句的實數特征向量,每個詞句的特征向量的維數相同(設為維向量),每一維度的參數表征了該詞句在對應一個方面上的語義。其中,維數越大,則該特征向量所能夠表示的一個詞句的語義也就越豐富。比如,該特征向量的第一個維度表示的是一個詞句屬于名詞的概率。在一個實施例中,每個詞句的特征向量為150維的實數向量。
具體的,可通過深度學習的思想,利用預先建立的語言模型,將數據庫中的每個詞句作為特征,將其射到K維向量空間進行訓練,獲取一個詞句向量空間上的表示,最終訓練得出的詞句具有唯一對應的一個特征向量。其中,可結合潛在語義分析(Latent Semantic Index,LSI)、潛在狄立克雷分配(Latent Dirichlet Allocation,LDA)或者Word2vec等來建立語言模型。其中,K值可為自定義的一個數值,比如為100、120、150、180、200等。
步驟210,根據每個詞句的特征向量計算文章對主體的描述的情感強度。
本實施例中,在獲取到每個詞句的特征向量后,可根據每個詞句的特征向量,進行向量運算,計算出文章對主體的情感強度。該情感強度可通過情感數值來體現。其中,情感數值為一個實數,具體可為處于一個實數范圍內的實數,比如為處于-1到1之間的實數。數字越小,所表達的負面情感越強烈;反之,則表達的正面情感越強烈;處于越中間的數值,則表示的情感越中立。
本實施例中,通過預先設置每個詞句的特征向量,并對文章進行詞句切分,以確定文章的描述主體,然后根據所切分的詞句的特征向量,根據該特征向量計算出文章對主體的描述的情感強度。相比于傳統的通過每個詞語對應的固定數值來計算文章的情感強度,本實施例所提供的文章情感的分析方法,所計算出的文章所表達的情感強度的準確性更高。
在一個實施例中,步驟208包括:對切分后的詞句進行篩選,獲取篩選后的詞句的特征向量。
步驟210包括:根據篩選后的詞句的特征向量計算文章對主體的描述的情感強度。
本實施例中,在完成對文章中的內容的詞句切分后,可根據所切分的詞句的詞性,進行篩選,以刪除對于文章的情感數值計算具有干擾或意義不大的詞句。具體的,可將詞性判斷為停用詞或助詞等詞性的詞句進行刪除。比如,停用詞為“the”、“is”、“at”、“that”、“是”、“的”等,助詞比如為“也”、“者”、“乎”等。并獲取刪除后的詞句的特征向量,根據刪除后的詞句的特征向量來計算該文章對主體所表達的情感強度。
本實施例中,通過進一步對所切分后的詞句的篩選,根據篩選后的詞句的特征向量計算文章的情感數值,既可減少情感數值的計算量,又可排除被刪除的詞句的干擾,提高了情感強度的計算的準確性。
在一個實施例中,步驟208包括:當獲取不到詞句的特征向量時,檢測預設的詞庫中是否存在與詞句相近的詞句,若是,則獲取該相近詞句的特征向量,將其作為該詞句的特征向量,若否,則將預設的默認特征向量作為詞句的特征向量。
本實施例中,數據庫中所存儲的詞句雖然眾多,但一般無法窮盡所有的詞句。因而待分析的文章中,可能使用了在數據庫中不存在的詞句。此時,可查詢數據庫中是否存在與該詞句的含義相同或相近的詞句,若存在,則將查詢出存在與該詞句含義最相近的詞句的特征向量作為該在數據庫中不存在的詞句的特征向量。若不存在,則將以預設的一個默認特征向量作為該詞句的特征向量,或者還可直接刪除該詞句。
本實施例中,含義越相同的詞句,其特征向量特越相近,甚至在多數維度上的數值相同,僅在個別維度上的數值有較小的差別。因此,當數據庫中不存在某一詞句的特征向量時,可將與其相近的詞句的特征向量作為該詞句的特征向量,若也不存在與其相近的詞句,則將一個默認的特征向量作為該詞句的特征向量。由于一篇文章中,存在這類的詞句的數量較少,采用上述的方法可保證最終所計算出的文章的情感強度的準確性。
在一個實施例中,如圖3所示,根據每個詞句的特征向量計算文章對主體的描述的情感強度的步驟,包括:
步驟302,根據每個詞句的特征向量計算對應文章的特征向量。
本實施例中,可將每個詞句的特征向量進行加權求和,將所得到的特征向量作為對應文章的特征向量。具體的,每個特征向量對應的權值可為一個默認的相同權值,還可結合每個詞句的詞性及其在文章中所處的位置,設置相對應的權值。比如,可將處于標題中的詞句設置相對較大的權值,而將文章正文部分的詞句設置相對較小的權值;將詞性為名詞的詞句設置相對較小的權值,而將形容詞設置相對較大的權值。
步驟304,根據文章的特征向量計算出文章的情感數值。
步驟306,根據文章的感情數值確定文章對主體的描述的情感強度。
本實施例中,在得到文章的特征向量后,可將其代入預先建立的情感數值計算模型中,計算出該文章的情感數值,然后根據該文章的情感數值確定文章對主體的描述的情感強度。
該情感數值計算模型為根據機器學習以及數據挖掘的初步模型,并經過樣本數據的訓練,最終得到的一個情感數值計算模型。其中,樣本數據為具有一定數量(比如10000篇)的樣本文章。每篇樣本文章均設置了人工打出的情感數值,將該情感數值作為文章的特征向量的一個維度。比如,待分析的文章的特征向量為150維,則樣本文章的特征向量即為151維,其中,第1維即為人工設置的情感數值。可將該樣本文章代入初步模型中進行訓練,根據訓練結果對模型中的相關參數進行修正,直到計算得到的每篇文章的情感數值與對應人工設置的情感數值相同或處于一定范圍的誤差之內為止。此時,所得到的模型即為最終的情感數值計算模型。
具體的,將該文章的特征向量代入所建立的情感數值計算模型中,該模型可按照決策樹的方法,將該特征向量進行分裂變量生成樹,按照所確定的參數進行計算,最終該樹的葉子節點輸出模型結果,該結果為一個數值,該數值即可作為該文章的情感數值。
本實施例中,通過根據詞句的特征向量計算出文章的特征向量,進而再根據文章的特征向量計算出對應文章的情感數值,根據文章的感情數值確定文章對主體的描述的情感強度,可進一步提高計算出的文章的情感數值的準確性。
在一個實施例中,如圖4所示,根據文章的特征向量計算出文章的情感數值的步驟,包括:
步驟402,重復預設次數,從文章的特征向量中隨機選取第一數量的參數,構成對應的第二數量的子向量。
本實施例中,預先設置了子向量的維度,該維度小于文章的特征向量(記為N維子向量)。服務器可從文章的特征向量中,隨機或按照一定的選取規則選取N個參數,構成一個N為子向量。并重復執行預設次數,得到第二數量的子向量,其中,每個子向量所包含的文章的特征向量的參數不完全相同。預設次數可為根據特征向量與子向量的維度所設置的一個合適的數值。比如,可設置第二數量為K-N+1,重復預設次數為K-N+1次。并依次從文章的K為特征向量中選取第1~N個參數、第2~N+1個參數…第K-N+1~K個參數,分別構成K-N+1個子向量。
在一個實施例中,可按照信息減少最快或信息下降最大的方向選擇文章的特征向量中的第一數量的參數,比如按照熵的計算方法,來進行參數的選擇。重復預設次數,生成第二數量的子向量。
步驟404,計算每個子向量對應的子情感數值,根據每個子情感數值計算文章的情感數值。
本實施例中,基于決策樹的方法,將每個子向量作為對應一顆數,利用隨機森林方法,得到每棵樹對應的數值,該數值即為子向量對應的子情感數值。將每個子情感數值進行加權平均,得到的數值即為文章的情感數值。
本實施例中,通過文章的特征向量構建相應數量的子向量,并計算出子向量的子情感數值,根據子情感數值得出文章的情感數值,可提高文章的情感數值的計算的效率。
在一個實施例中,上述的文章情感的分析方法還包括:獲取主體相同的文章的情感強度;計算相同主體的綜合情感強度。
本實施例中,如圖5所示,提供了另一種文章情感的分析方法,該方法包括以下步驟:
步驟502,獲取待分析的文章。
本實施例中,可預先設置所需獲取的文章的來源,該來源可為一個或多個網站。服務器或終端可通過網絡爬蟲技術從預設的多個網站上獲取其所發表的多個文章。進一步的,可設置一個獲取時間間隔,根據該時間間隔周期性的從預設的文章的來源處獲取在當前周期內所發表的文章。
步驟504,對文章中的內容進行詞句切分,生成對應數量的詞句。
步驟506,根據詞句確定文章描述的主體。
本實施例中,同一主體的表述方式可能存在多種,服務器或終端可對所確定的文章的主體進行識別,將不同表述的主體歸類為同一個主體。
步驟508,判斷文章描述的主體是否為預設的主體,若是,則執行步驟510,否則,執行步驟514。
可預先設置所需要識別的一個或多個主體,并在通過步驟206識別出文章的主體后,判斷該主體是否為預設的所需識別的主體,若是,則計算出該文章的情感數值,否則,舍棄該文章,并執行步驟514。
在一個實施例中,文章為新聞類的文章,文章的主體為上市企業。可將主體為同一企業的不同表述方式、以及該企業的子公司以及與該企業具有相關聯的主體均判斷為同一主體。比如,存在三篇文章,其主體分別為“平安集團”、“平安公司”、“平安集團的員工張三”,則可是識別出“平安集團”、“平安公司”均為“平安科技有限公司”這一主體,而“平安集團的員工張三”也與“平安科技有限公司”相關聯,因而可將這三篇文章的主體判定為相同的主體。
所設置的需獲取的文章的來源為預設的多個財經類網站,并周期性地通過網絡爬蟲技術從該網站獲取在當前周期內所發表的文章。其中,可每天固定的時間獲取在當天或前一天所發表的文章。
步驟510,獲取每個詞句的特征向量。
步驟512,根據每個詞句的特征向量計算文章對主體的描述的情感強度。
本實施例中,可根據每個詞句的特征向量計算出文章的特征向量,進而根據文章的特征向量計算出該文章的情感數值,將該情感數值歸類到對應的主體中。具體的,可以以“主體-情感數值”的形式來存儲所計算出的文章的情感數值,以便于進行匯總分析。根據文章的情感數值可確定該文章對主體的描述的情感強度。
步驟514,判斷是否還存在待分析的文章,若是,則執行步驟502,否則,執行步驟516。
本實施例中,待分析的文章包括多個,在完成對當前文章的情感數值的計算之后,可檢測是否還存在未檢測的文章,若存在,則執行步驟502,獲取下一個待分析的文章。
具體的,可對所提取的文章設置分析狀態標記,該分析狀態標記用于反映相應的文章的分析狀態,分析狀態包括未分析、正在分析、以及分析完畢。當文章處于分析中時,則更改其分析狀態標記為表示正在分析中的標記,當分析完畢時,則更改其分析狀態標記為表示已經分析完畢的標記。通過檢測是否還存在表示未分析的狀態標記,可獲知是否還存在待分析的文章。
步驟516,獲取主體相同的文章的情感強度,計算相同主體的綜合情感強度。
在計算出所有所需識別的文章的情感強度后,可將具有相同的主體的文章的情感強度進行加權平均,得到當前周期下的相同主體的綜合情感強度。其中每個文章的情感強度對應的權值可根據文章的來源進行設置,可設置為相同的權值或不同的權值。其中,可將具有相同的主體的文章的情感數值進行加權平均,得到當前周期下的相同主體的綜合情感數值,根據該綜合情感數值確定相同主體的綜合情感強度。
本實施例所提供的文章情感的分析方法,可應用于上市公司的市場預測中,其中,待分析的文章為相關財經類網站上的新聞報道,并結合多個新聞報道計算出該上市公司的情感強度,將該情感強度作為對該上市公司的市場預測的一個考慮因素,從而可提高對上市公司的時長預測的準確性。
在一個實施例中,如圖6所示,提供了一種文章情感的分析裝置,該裝置包括:
文章獲取模塊602,用于獲取待分析的文章。
詞句切分模塊604,用于對文章中的內容進行詞句切分,生成對應數量的詞句。
主體確定模塊606,用于根據詞句確定文章描述的主體。
特征向量獲取模塊608,用于獲取每個詞句的特征向量。
情感強度計算模塊610,用于根據每個詞句的特征向量計算文章對主體的描述的情感強度。
在一個實施例中,特征向量獲取模塊608還用于對切分后的詞句進行篩選,獲取篩選后的詞句的特征向量。
情感強度計算模塊610還用于根據篩選后的詞句的特征向量計算文章的情感數值。
在一個實施例中,特征向量獲取模塊608還用于當獲取不到詞句的特征向量時,檢測預設的詞庫中是否存在與詞句相近的詞句,若是,則獲取該相近詞句的特征向量,將其作為該詞句的特征向量,若否,則將預設的默認特征向量作為詞句的特征向量。
在一個實施例中,情感強度計算模塊610還用于根據每個詞句的特征向量計算對應文章的特征向量;根據文章的特征向量計算出文章對主體的描述的情感強度;根據文章的感情數值確定文章對主體的描述的情感數值。
在一個實施例中,如圖7所示,情感強度計算模塊610還包括:
子向量構建單元702,用于重復預設次數,從文章的特征向量中隨機選取第一數量的參數,構成對應的第二數量的子向量。
情感數值計算單元704,用于計算每個子向量對應的子情感數值,根據每個子情感數值計算文章的情感數值。
在一個實施例中,如圖8所示,提供了另一種文章情感的分析裝置,該裝置該包括:
綜合情感強度計算模塊612,用于獲取主體相同的文章的情感強度,計算相同主體的綜合情感強度。
本領域普通技術人員可以理解實現上述實施例方法中的全部或部分流程,是可以通過計算機程序來指令相關的硬件來完成,所述的程序可存儲于一非易失性計算機可讀取存儲介質中,該程序在執行時,可包括如上述各方法的實施例的流程。其中,所述的存儲介質可為磁碟、光盤、只讀存儲記憶體(Read-Only Memory,ROM)等。
以上所述實施例的各技術特征可以進行任意的組合,為使描述簡潔,未對上述實施例中的各個技術特征所有可能的組合都進行描述,然而,只要這些技術特征的組合不存在矛盾,都應當認為是本說明書記載的范圍。
以上所述實施例僅表達了本發明的幾種實施方式,其描述較為具體和詳細,但并不能因此而理解為對發明專利范圍的限制。應當指出的是,對于本領域的普通技術人員來說,在不脫離本發明構思的前提下,還可以做出若干變形和改進,這些都屬于本發明的保護范圍。因此,本發明專利的保護范圍應以所附權利要求為準。
- 還沒有人留言評論。精彩留言會獲得點贊!