一種電力大數據分布控制系統及其構建方法與流程
本發明屬于大數據計算仿真技術領域,尤其涉及一種電力大數據分布控制系統及其構建方法。
背景技術:
隨著互聯網的不斷發展,我們的社會已經進入大數據時代,海量的信息不僅代表著大量的機遇,也為我們提出了巨大的挑戰。數字化的生活所需要處理的數據越來越龐大,越來越復雜,大量實際應用部門,如天氣預報、航天計算、核反應模擬、海量數據壓縮存儲以及其他大型事務處理等,都需要每秒執行數十萬億次乃至數百萬億此浮點運算的計算機,僅僅憑借單臺服務器已經難以快速有效地對海量數據進行分析處理。特別是在社交網絡、電子商務極度流行的今天,照片、視頻成為交流信息的主要手段,需要對圖像視頻進行不同格式、不同分辨率的重編碼,其所需數據的存儲與計算能力日漸升高。由此,計算機領域中出現了分布式并行計算的概念。
并行計算相對于串行計算而言,能夠一次處理多條指令,擴大數據處理規模,提高數據計算速度。分布式并行計算的核心思想是利用多個處理器設備協同計算,即將需處理的數據劃分成多個互相獨立的分片,統一調度分派給多個節點(即單臺處理設備),然后集群中的每個節點分別獨立的處理數據分片,最后將得到的部分數據處理結果匯集到一起,進而得出最終結果。由于FPGA硬件并行性的特點,非常適合進行大規模數據計算,同時現有很多軟核,方便二次開發,如果將分布式并行計算方式和FPGA硬件加速結合起來,必會對海量數據的處理取得更高的效率,從而給社會、生活帶來巨大的好處和商機。
技術實現要素:
本發明所要解決的技術問題是針對背景技術中的問題提供一種電力大數據分布控制系統及其構建方法,將分布式計算框架和FPGA硬件加速結合起來,從粗粒度和細粒度實現了對海量數據或大規模科學計算問題的超并行加速處理,大大提高大規模數據處理速率。
本發明為解決上述技術問題采用以下技術方案
一種電力大數據分布控制系統,包含Master調度器、節點和用戶終端,所述節點包括處理節點和收集節點,所述用戶終端通過Master調度器分別與處理節點、收集節點連接;所述Master調度器用于根據整個系統的資源及計算能力情況將任務分配給處理節點;所述處理節點根據Master調度器分配的任務對某個數據子部分進行處理;所述收集節點用于收集處理節點處理后的結果寫入到某一區域,并將數據返回給用戶終端。
作為本發明一種電力大數據分布控制系統的進一步優選方案,所述Master調度器包括數據緩存器、Hash算法模塊和可控輪詢算法模塊;所述數據緩存器用于存儲IP報文的數據;Hash算法模塊用于對數據信息進行哈希運算;可控輪詢算法模塊用于數據信息隊列調度和數據重組。
作為本發明一種電力大數據分布控制系統的進一步優選方案,所述處理節點和收集節點均包括ARM處理器、FPGA和通信接口模塊,所述ARM處理器分別與FPGA、通信接口模塊通過導線連接。
一種基于電力大數據分布控制系統的構建方法,具體包括以下步驟:
步驟1,用戶發送數據處理請求,Master調度器分析用戶的數據處理請求;
步驟2,Master調度器利用Hash算法模塊對各節點運行情況進行分析,根據分析結果將數據信息分發到節點隊列中;
步驟3,根據各個節點統計的數據流量值和狀態信息,利用可控輪詢算法對各個隊列進行輪詢調度,實現進程的動態均衡;
步驟4,將處理節點處理后的結果經過收集節點提交給用戶,并在客戶端顯示接收結果。
作為本發明一種電力大數據分布控制系統的構建方法的進一步優選方案,在步驟1中,用戶通過通信網絡將數據處理請求傳送至Master調度器。
作為本發明一種電力大數據分布控制系統的構建方法的進一步優選方案,所述步驟2中的Hash算法具體包括以下步驟:
步驟2-1,提取IP數據信息的首部信息,并將相應的IP數據緩存到一個數據存儲器中;
步驟2-2,將原IP地址和目的IP地址分別分為兩個16位字節,設定源端口號和目的端口號分別為SP和DP;
步驟2-3,進行Hash運算;
步驟2-4,根據Hash運算結果將數據信息傳送至各處理節點。
作為本發明一種電力大數據分布控制系統的構建方法的進一步優選方案,所述步驟3中的可控輪詢算法具體包括以下步驟:
步驟3-1,每次發送完一個數據分組時,詢問所有節點隊列;
步驟3-2,判斷存在幾個滿隊列,如果只有一個滿隊列,則計算該滿隊列的輪詢等待時間,啟動等待時間計數器,到達輪詢等待時間時,轉發該滿隊列的數據分組;如果存在多個滿隊列,則根據這幾個滿隊列統計的已發送數據流量值,選中滿隊列中端口流量值最小的滿隊列,計算其輪詢等待時間,啟動等待時間計數器,到達輪詢等待時間時轉發該滿隊列的數據分組;另外,如果多個滿隊列中有兩個以上的隊列的數據流量值相等,且它們的流量值最小,則轉發端口號最小的滿隊列的數據分組;
步驟3-3,如不存在滿隊列,選中所有隊列中的非空隊列;
步驟3-4,比較各個非空隊列統計的數據流量值,判斷非空隊列中是否只有一個隊列的流量最小值,如果是,就計算該隊列的輪詢等待時間,啟動等待時間計數器,到達輪詢等待時間時,就直接轉發該隊列對應的數據分組;否則,選中端口號最小的隊列,計算其輪詢等待時間,啟動等待時間計時器,達到輪詢等待時間時,轉發該隊列對應的數據分組。
本發明采用以上技術方案與現有技術相比,具有以下技術效果:
1、本發明發明了一種超并行計算框架,能夠對大數據進行合理分片并實現系統節點的負載均衡,系統結構可動態變化,實現高性能、高靈活度的分布式并行計算系統;
2、本發明采用合理的負載均衡算法,結合數據、各節點的資源和處理情況進行任務分發,使整個系統的資源利用率和性能實現最大化;
3、本發明提供界面顯示程序與各子結點的通信機制,實時顯示系統整體和子節點的處理情況。
附圖說明
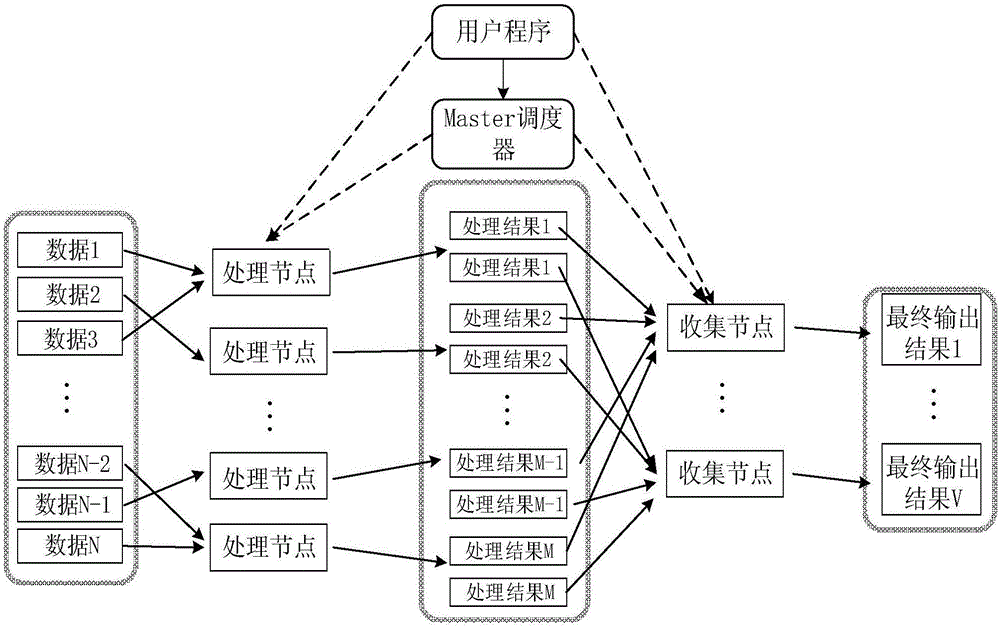
圖1是本發明實施例中結構示意圖;
圖2是本發明實施例中負載均衡結構圖;
圖3是本發明實施例中可控輪詢算法流程圖;
圖4是本發明實施例中各節點結構圖;
圖5是本發明實施例中數據處理流程圖。
具體實施方式
下面結合附圖對本發明的技術方案做進一步的詳細說明:
如圖1所示,一種電力大數據分布控制系統,包含Master調度器、節點和用戶終端,所述節點包括處理節點和收集節點,所述用戶終端通過Master調度器分別與處理節點、收集節點連接;所述Master調度器用于根據整個系統的資源及計算能力情況將任務分配給處理節點;所述處理節點根據Master調度器分配的任務對某個數據子部分進行處理;所述收集節點用于收集處理節點處理后的結果寫入到某一區域,并將數據返回給用戶終端。
所述Master調度器包括數據緩存器、Hash算法模塊和可控輪詢算法模塊;所述數據緩存器用于存儲IP報文的數據;Hash算法模塊用于對數據信息進行哈希運算;可控輪詢算法模塊用于數據信息隊列調度和數據重組。
所述處理節點和收集節點均包括ARM處理器、FPGA和通信接口模塊,所述ARM處理器分別與FPGA、通信接口模塊通過導線連接。
Master調度器計算整個系統的資源及計算能力情況,并將任務分配給處理節點。數據部分把各節點數據虛擬成一個整體,并將其劃分成各個獨立的子部分,存儲于各節點。處理節點根據Master調度器分配的任務對某個數據子部分進行處理,并將處理結果寫入到某一指定的區域;收集節點主要是收集處理節點處理后的結果,并寫入到某一指定的區域,最后將此區域的數據返回給用戶程序。用戶程序用以提交請求和接收處理結果的客戶端。包括實時的顯示當前系統的處理方式、系統整體及各節點的實時處理情況,并根據反饋的情況控制整個系統。
如圖2所示,Master調度器實現負載均衡算法的實現。它包括以下步驟:
步驟1、用戶程序發送數據處理請求,Master調度器分析用戶請求。
步驟2、Master調度器利用Hash算法模塊對各節點運行情況進行分析,根據分析結果將數據信息分發到所有節點隊列中,實現數據任務的靜態分配。
步驟3、根據各個節點統計的數據流量值和狀態信息,利用可控輪詢算法對各個隊列進行輪詢調度,實現進程的動態均衡。
步驟4、將處理節點處理后的結果經過收集節點提交給用戶,并在客戶端顯示接收結果。
步驟2中所述Hash算法包括以下步驟:
步驟2-1:提取IP數據信息的首部信息,并將相應的IP數據緩存到一個數據存儲器中;
步驟2-2:將原IP地址和目的IP地址分別分為兩個16位字節,分別為S1、S2、D1、D2。設定源端口號和目的端口號分別為SP和DP;
步驟2-3:進行Hash運算,包括:
1)hash1=S1<<n|S1>>(16-n),其中n為位移數;
2)hash1=hash1∧D1;
3)hash=hash1;
4)hash1=S2<<n|S2>>(16-n);
5)hash1=hash1∧SP;
6)Hash=hash∧hash1;
7)hash1=D2<<n|D2>>(16-n);
8)hash1=hash1∧DP;
9)hash∧=hash1;
10)hash=hash%N,N為處理節點數。
步驟2-4:根據Hash結果將數據信息傳送至各處理節點。
步驟3利用可控輪詢算法完成進程的動態均衡,具體流程如圖3所示,包括:
步驟3-1、每次發送完一個數據分組時,詢問所有節點隊列;
步驟3-2、首先判斷是否存在滿隊列,如果存在,再判斷存在幾個滿隊列,如果只有一個滿隊列,就計算該滿隊列的輪詢等待時間,啟動等待時間計數器,到達輪詢等待時間時,轉發該滿隊列的數據分組;如果存在多個滿隊列,根據這幾個滿隊列統計的已發送數據流量值,選中滿隊列中端口流量值最小的隊列,計算其輪詢等待時間,啟動等待時間計數器,到達輪詢等待時間時轉發該隊列的數據分組;另外,如果多個滿隊列中有兩個以上的隊列的數據流量值相等,且它們的流量值最小,則轉發端口號最小的滿隊列的數據分組;
步驟3-3、如不存在滿隊列,選中所有隊列中的非空隊列;
步驟3-4、比較各個非空隊列統計的數據流量值,判斷非空隊列中是否只有一個隊列的流量最小值,如果是,就計算該隊列的輪詢等待時間,啟動等待時間計數器,到達輪詢等待時間時,就直接轉發該隊列對應的數據分組;否則,選中端口號最小的隊列,計算其輪詢等待時間,啟動等待時間計時器,達到輪詢等待時間時,轉發該隊列對應的數據分組。
如圖4,單個節點包括ARM處理器、FPGA和通信接口模塊。當控制器接收到Master調度器的命令和代碼后,將代碼傳至FPGA,之后將數據通過數據通道傳至FPGA。FPGA模塊對接收數據處理后通過數據發送模塊將結果發送至ARM上,再送出節點外。同時FPGA的數據處理情況實時反饋到控制器,控制器將必要的數據顯示在界面上。
如圖5,一種電力大數據分布式計算平臺,其數據處理流程為:平臺啟動后,客戶端請求通過網絡傳至Master調度器進行分析。如果請求不可行,直接將異常輸出到客戶端;否則,Master調度器計算當前系統資源和運行情況,然后分配任務至各個節點;節點響應后,根據任務攜帶的信息判斷數據是否本地化,沒有則將遠端數據傳至本地進行處理,否則直接進行處理。各個節點處理完數據后,將處理結果寫入指定區域。當節點處理完后,將指定區域的總的處理結果通過網絡提交用客戶端。
- 還沒有人留言評論。精彩留言會獲得點贊!