一種基于支持向量機的癲癇腦電分類方法與流程
本發明涉及一種癲癇腦電分類領域,具體涉及一種基于支持向量機的癲癇腦電分類方法。
背景技術:
癲癇是一種以腦內神經元異常放電為特征的部分或全腦功能障礙的慢性病,我國擁有數量龐大的癲癇患者,并且以60萬例的速度在增加。癲癇腦電信號的分類與檢測技術有助于減少醫務工作者的工作量,具有實際意義的臨床應用。現有技術利用近似熵、波動系數、極端學習機對癲癇腦電信號進行二分類,或者利用經驗模式分解和支持向量機,對正常腦電信號和癲癇腦電信號進行分類,或利用小波包分解系數矩陣、小波包熵、adaboost算法,將腦電信號分類成正常狀態和癲癇發作狀態,以及等用支持向量機和遞歸定量分析分類腦電信號,或用樣本熵、ar參數和自適應極限學習機對腦電信號進行分類,或用小波變換和高階矩陣相結合的方法提取特征,使用支持向量機對腦電信號進行分類。上述方法將腦電信號分類成正常信號和癲癇信號,但是沒有考慮癲癇發作間歇期信號的分類,本文提出一種粒子群算法優化支持向量機的信號分類檢測技術,解決了分類準確率和分類類別數的部分沖突。在保證分類精度的基礎上,腦電信號被分類為正常,癲癇發作和癲癇發作狀態。
技術實現要素:
本發明針對現有技術中癲癇腦電信號分類準確率低、分類類別少的問題,依據粒子群算法和支持向量機理論,提出了一種基于粒子群算法優化支持向量機參數的信號分類檢測方法。
本發明的目的是這樣實現的:一種基于支持向量機的癲癇腦電分類方法,具體步驟包括:
步驟a、選取實驗數據:在數據庫中分別選取健康人清醒時的腦電信號,癲癇病人發發作間期的腦電信號和癲癇病人發作期的腦電信號三組信號,各100段,并進行分解重構,提取有效波段;
步驟b、求解特征向量;
步驟c、利用支持向量機對實驗數據分類;
步驟d、用粒子群算法優化支持向量機的懲罰因子c和核函數參數σ。
進一步地,所述步驟a的具體方法是:分別選取100段健康人清醒時的腦電信號,癲癇病人發發作間期的腦電信號和癲癇病人發作期的腦電信號,每段時長23.6s,每段信號采集4097點,采樣頻率為173.6hz,利用小波變換,對腦電信號進行5層分解與重構,提取出有效頻段。
再進一步地,利用db4小波變換進行五層分解重構,第三、四和五層重構信號集中在0.5hz~35hz之間。
進一步地,所述步驟b的具體步驟包括:
步驟b1、利用改進算法計算進近似熵;
步驟b2、提取波動系數。
再進一步地,所述步驟b1的具體步驟包括:
步驟b11、待處理的癲癇腦電信號個數為n,計算n*n的距離矩陣d,d為對稱矩陣,d的第i行第j列元素記為dij,
步驟b12、利用距離矩陣d中的元素,對每個向量xi統計dij<r的數目,并求出該數目與距離總數n-m的比值
m增加1,求得
步驟b13、對
m增加1,求得φm+1(r):
步驟b14、根據φm(r)和φm+1(r)求得近似熵apen:
apen(m,r)=φm(r)-φm+1(r)
其中,m=2,r=0.2*std(sig),std(sig)為信號sig的標準差。
再進一步地,所述步驟b2中計算波動系數的具體方法是:波動系數可以表示為:
其中,ani為第n段腦電數據小波變換后第i層的幅度,m為信號的長度,n取值范圍1-100,i取值為3、4和5,m取4097。
進一步地,所述步驟c的具體步驟包括:
步驟c1、假設有兩類待分類的實驗數據:(x1,y1),(x2,y2),...,(xn,yn),x∈rn,yi∈{1,-1},xi是實驗數據,yi是實驗數據的標簽,存在一個最優分類面,其方程可以表示為:
wt·x+b=0
其中,wt是最優分類面的法向量,b為最優分類面的常數項;
通過這個最優分類面,可以分類兩種類型的樣本數據,令:
f(x)=wtx+b
如果f(x)=0,那么x是位于分類面上的點;
如果f(x)<0,可以設定x對應的標簽y為-1;f(x)>0,那么x對應的標簽y為1,將實驗數據進行分類;
如果所有測試樣本都可以正確分類,測試樣本滿足條件:
yi[(wt·xi)+b]-1≥0,i=1,…,n
兩條分類面h1、h2之間的距離是2/||w||,要尋找最優分類線,即使得2/||w||最大,即
s.tyi[w.x+b]-1≥0,i=1,…,n
求解上式的二次規劃問題,得到最優分類面的w和b,最優分類函數為:
f(x)=sgn(w·x+b)
步驟c2、利用核函數對線性不可分的數據進行處理,在低維空間線性不可分的數據xi,通過非線性映射φ(x)到高維空間,使得數據在高維空間線性可分,在高維空間找出最優分類面,滿足mercer條件的核函數能夠實現非線性轉換,
定義的mercer條件的核函數:
k(xi,xj)=φ(xi).φ(xj)
徑向基核函數:
進一步地,所述步驟d的具體步驟包括:
步驟d1、初始化粒子群:粒子種群數目設定為20,每個粒子在二維空間中的坐標表示為xi=(xi1,xi2)(i=1,2,…,20),以速度vs=[vs1,vs2](s=1,2,…,20)在二維解空間內進行搜索;
步驟d2、計算每個粒子的適應度:粒子在更新位置時需要考慮粒子個體的最優位置pi和粒子種群最優位置pg:
pi=(pi1,pi2),i=1,2,…,20,
pg=(pg1,pg2,…pgn),n=20;
步驟d3、更新粒子尋優速度向量:
vs+1=vs+c1rand1()(pi-xi)
+c2rand2()(pg-xi)
其中,c1取1.5,c2取1.7,rand1()和rand2()表示0到1的隨機數;
步驟d4、更新粒子位置:
xi+1=xi+vi+1
步驟d5、判斷是否滿足迭代次數200,如果:
不滿足,返回步驟d2;
滿足,則返回最優解。
有益效果:
本發明的一種基于支持向量機的癲癇腦電分類方法,利用粒子群算法優化支持向量機參數,對支持向量機的參數c和σ進行優化,尋找最優的參數值,進一步提高支持向量機的學習能力和收斂速度,提高了數據分類的準確率,并且將腦電信號分為正常,癲癇發作和癲癇發作狀態,增加了分類類別數,解決了現有技術的解決了分類準確率和分類類別數的部分沖突。
附圖說明
圖1本方法的不同組腦電信號的近似熵對比圖;
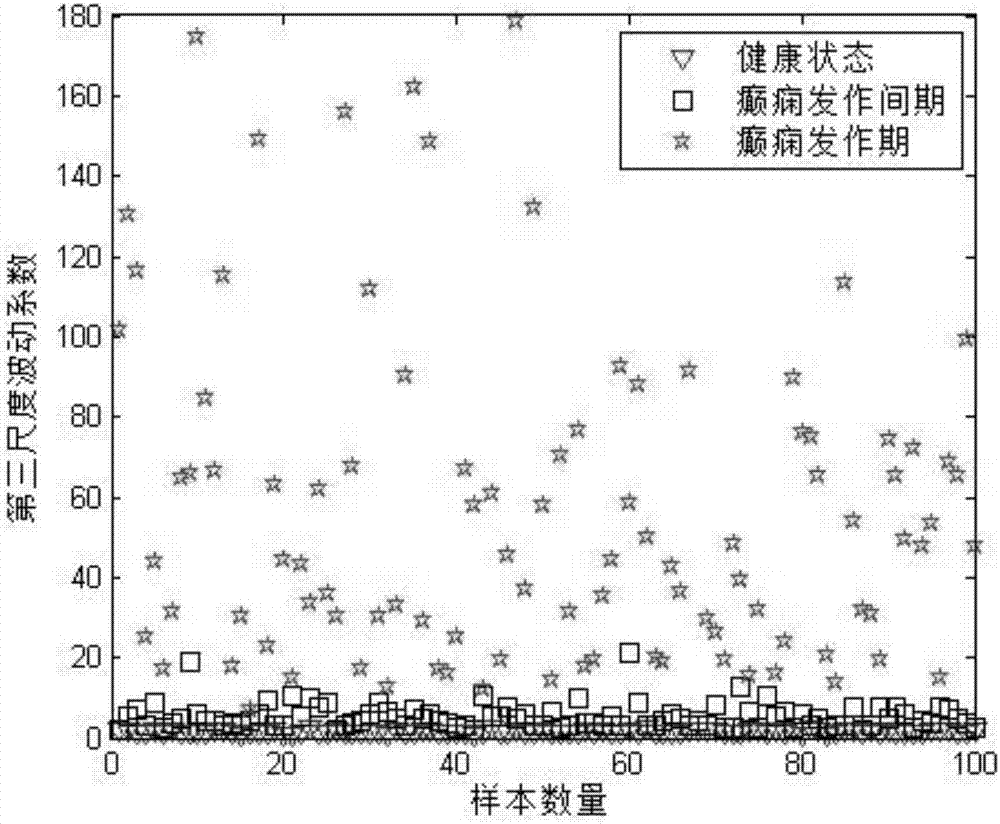
圖2各組腦電信號小波變換后第三層的波動系數;
圖3各組腦電信號小波變換后第四層的波動系數;
圖4各組腦電信號小波變換后第五層的波動系數;
圖5支持向量機分類后得到的最優分類面示意圖;
圖6粒子群算法流程圖。
具體實施方式
結合圖1~6說明本實施方式,本實施方式的一種基于支持向量機的癲癇腦電分類方法,具體步驟包括:
步驟a、選取實驗數據:分別選取100段健康人清醒時的腦電信號,癲癇病人發發作間期的腦電信號和癲癇病人發作期的腦電信號,每段時長23.6s,每段信號采集4097點,采樣頻率為173.6hz,利用小波變換,db4小波對三組腦電信號進行5層小波分解重構,第三、四和五層重構信號主要集中在0.5hz~35hz之間。
步驟b、求解特征向量,具體步驟包括:
步驟b1、利用改進算法計算進近似熵,具體步驟為:步驟b11、待處理的癲癇腦電信號個數為n,計算n*n的距離矩陣d,d為對稱矩陣,d的第i行第j列元素記為dij,
步驟b12、利用距離矩陣d中的元素,對每個向量xi統計dij<r的數目,并求出該數目與距離總數n-m的比值
m增加1,求得
步驟b13、對
m增加1,求得φm+1(r):
步驟b14、根據φm(r)和φm+1(r)求得近似熵apen:
apen(m,r)=φm(r)-φm+1(r)
其中,m=2,r=0.2*std(sig),std(sig)為信號sig的標準差,不同組腦電信號的近似熵對比圖如圖1所示,健康狀態、癲癇發作間期、癲癇發作期的近似熵的幅值具有較大差別,提取腦電信號的近似熵可以較好的表征不同腦電信號。
步驟b2、提取波動系數,波動系數可以表示為:
其中,ani為第n段腦電數據小波變換后第i層的幅度,m為信號的長度,n取值范圍1-100,i取值范圍3、4和5,m取4097,圖2,圖3和圖4分別為各組腦電信號小波變換后第三層、第四層和第五層的波動系數,在不同狀態下有較為明顯的差異。癲癇發作期波動系數最大而且波動性較強;癲癇發作間歇期的波動系數較為平穩,且值處于健康狀態和癲癇發作狀態的之間;健康狀態下的波動系數最為平穩且值最小。因此可用不同尺度下的波動系數作為腦電信號特征。
步驟c、支持向量機(supportvectormachine,svm)廣泛應用于模式識別和分類檢測中,svm很好的解決了高維度,小樣本,非線性等問題。支持向量機的核心思想是,找到一種能夠對兩類樣本進行正確分類的最優分類面,且不同樣本距分類面距離越大,分類效果越好。
利用支持向量機對實驗數據分類,具體步驟包括:
步驟c1、假設有兩類待分類的實驗數據:(x1,y1),(x2,y2),…,(xn,yn),x∈rn,yi∈{1,-1},xi是實驗數據,yi是實驗數據的標簽,存在一個最優分類面,其方程可以表示為:
wt·x+b=0
其中,wt是最優分類面的法向量,b為最優分類面的常數項;
通過這個最優分類面,可以分類兩種類型的樣本數據,令:
f(x)=wtx+b
如果f(x)=0,那么x是位于分類面上的點;
如果f(x)<0,可以設定x對應的標簽y為-1;f(x)>0,那么x對應的標簽y為1,將實驗數據進行分類;
如果所有測試樣本都可以正確分類,測試樣本應滿足條件:
yi[(wt·xi)+b]-1≥0,i=1,…,n
兩條分類面h1、h2之間的距離是2/||w||,要尋找最優分類線,即使得2/||w||最大,即
s.tyi[w.x+b]-1≥0,i=1,…,n
求解上式的二次規劃問題,得到最優分類面的w和b,最優分類函數為:
f(x)=sgn(w·x+b)
支持向量機分類后得到的最優分類面如圖5所示,正方形和圓形代表兩種類型的數據,h代表最優分類面,h1、h2為各類中離分類線最近的樣本且平行于分類面的直線,分布在該直線的點被稱為支持向量,h1和h2的距離就是分類間隔。所謂最優分類面是指分類線既能正確分離兩類,又能最大化分類間隔。wt是最優分類面的法向量,b為最優分類面的常數項。
步驟c2、利用核函數對線性不可分的數據進行處理,在低維空間線性不可分的數據xi,通過非線性映射φ(x)到高維空間,使得數據在高維空間線性可分,在高維空間找出最優分類面,滿足mercer條件的核函數能夠實現非線性轉換,
定義的mercer條件的核函數:
k(xi,xj)=φ(xi).φ(xj)
核函數有多種形式,經常使用的主要包含徑向基函數、多項式函數、sigmoid函數等。核函數的差異會構成不同的支持向量機,本實施方式選取的核函數是徑向基函數,徑向基核函數:
步驟d、用粒子群算法優化支持向量機的懲罰因子c和核函數參數σ,粒子群算法流程圖如圖6所示,具體步驟包括:
步驟d1、初始化粒子群:粒子種群數目設定為20,每個粒子在二維空間中的坐標表示為xi=(xi1,xi2)(i=1,2,…,20),以速度vs=[vs1,vs2](s=1,2,…,20)在二維解空間內進行搜索;
步驟d2、計算每個粒子的適應度:粒子在更新位置時需要考慮粒子個體的最優位置pi和粒子種群最優位置pg:
pi=(pi1,pi2),i=1,2,…,20,
pg=(pg1,pg2,…pgn),n=20;
步驟d3、更新粒子尋優速度向量:
vs+1=vs+c1rand1()(pi-xi)
+c2rand2()(pg-xi)
其中,c1取1.5,c2取1.7,rand1()和rand2()表示0到1的隨機數;
步驟d4、更新粒子位置:
xi+1=xi+vi+1
步驟d5、判斷是否滿足迭代次數200,如果:
不滿足,返回步驟d2;
滿足,則返回最優解。
- 還沒有人留言評論。精彩留言會獲得點贊!