一種多約束條件下的個性化信息推薦方法及信息推薦系統與流程
本發明屬于用戶信息推薦技術領域,具體涉及一種多約束條件下的個性化信息推薦方法及信息推薦系統。
背景技術:
個性化推薦根據用戶興趣和行為特點,向用戶推薦所需的信息或商品,幫助用戶在海量信息中快速發現真正所需的商品,提高用戶黏性,促進信息點擊和商品銷售。目前應用比較普遍的個性化推薦算法有以下幾種:
1.基于人口統計學的推薦(同類人喜歡什么就推薦什么)
基于人口統計學的推薦機制是一種最易于實現的推薦方法,它只是簡單的根據系統用戶的基本信息發現用戶的相關程度,然后將相似用戶喜愛的其他物品推薦給當前用戶。
這個方法的缺點和問題在于,這種基于用戶的基本信息對用戶進行分類的方法過于粗糙,尤其是對品味要求較高的領域,比如圖書,電影和音樂等領域,無法得到很好的推薦效果。另外一個局限是,這個方法可能涉及到一些與信息發現問題本身無關卻比較敏感的信息,比如用戶的年齡等,這些用戶信息不是很好獲取。
2.基于內容的推薦(用戶喜歡什么,就推薦相同類型的)
基于內容的推薦的核心思想是根據推薦物品或內容的元數據,發現物品或者內容的相關性,然后基于用戶以往的喜好記錄,推薦給用戶相似的物品。
這個方法的缺點和問題在于,抽取的特征既要保證準確性又要具有一定的實際意義,否則很難保證推薦結果的相關性。
3.基于關聯規則的推薦(用戶喜歡a,a和b有緊密聯系,就推薦b)
基于關聯規則的推薦系統的首要目標是挖掘出關聯規則,也就是那些同時被很多用戶購買的物品集合,這些集合內的物品可以相互進行推薦。目前關聯規則挖掘算法主要從apriori和fp-growth兩個算法發展演變而來。
這個方法的缺點和問題在于,計算量較大,由于采用用戶數據,不可避免的存在冷啟動和稀疏性問題,存在熱門項目容易被過度推薦的問題。
4.基于協同過濾的推薦
協同過濾是基于一個“物以類聚,人以群分”的假設,喜歡相同物品的用戶更有可能具有相同的興趣。協同過濾被視為利用集體智慧的典范,不需要對項目進行特殊處理,而是通過用戶建立物品與物品之間的聯系。
目前,協同過濾推薦系統被分化為兩種類型:基于用戶(user-based)的推薦和基于物品(item-based)的推薦。
4.1.基于用戶的推薦
參考圖1所示,基于用戶的協同過濾推薦的基本原理是,根據所有用戶對物品或者信息的偏好(評分),發現與當前用戶口味和偏好相似的“鄰居”用戶群,在一般的應用中是采用計算k最近鄰的算法;然后,基于這k個鄰居的歷史偏好信息,為當前用戶進行推薦。
但是,這種推薦系統的缺點在于:在一般的網絡系統中,用戶的增長速度都遠遠大于物品的增長速度,因此其計算量的增長巨大,系統性能容易成為瓶頸。因此在業界中單純的使用基于用戶的協同過濾系統較少。
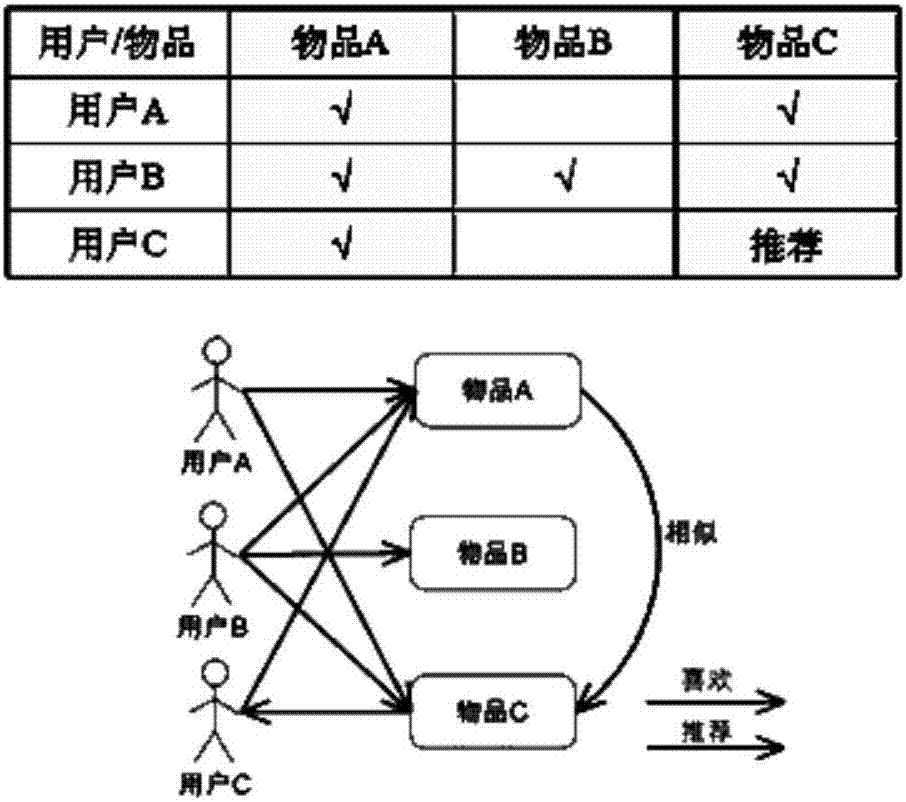
4.2.基于物品的推薦
參考圖2所示,基于物品的協同過濾和基于用戶的協同過濾相似,它使用所有用戶對物品或者信息的偏好(評分),發現物品和物品之間的相似度,然后根據用戶的歷史偏好信息,將類似的物品推薦給用戶。基于物品的協同過濾可以看作是關聯規則推薦的一種退化,但由于協同過濾更多考慮了用戶的實際評分,并且只是計算相似度而非尋找頻繁集,因此可以認為基于物品的協同過濾準確率較高,并且覆蓋率更高。
同基于用戶的推薦相比,基于物品的推薦應用更為廣泛,擴展性和算法性能更好。由于項目的增長速度一般較為平緩,因此性能變化不大。缺點就是無法提供個性化的推薦結果。
基于協同過濾的推薦機制是現今應用最為廣泛的推薦機制,然而它也存在以下幾個問題:
1、方法的核心是基于歷史數據,所以對新物品和新用戶都有“冷啟動”的問題。
2、推薦的效果依賴于用戶歷史偏好數據的多少和準確性。
3、在協同過濾實現過程中,用戶歷史偏好大部分是用稀疏矩陣進行存儲的,而稀疏矩陣上的計算有些明顯的問題,包括可能存在少部分人的錯誤偏好會對推薦的準確度有很大的影響等等。
4、對于一些特殊品味的用戶不能給予很好的推薦。
5、由于以歷史數據為基礎,抓取和建模用戶的偏好后,很難修改或者根據用戶的使用演變,從而導致這個方法不夠靈活。
技術實現要素:
本發明的目的在于,為了解決現有的推薦方法中因用戶或物品信息不足,導致推薦結果不準確、數據稀疏“冷啟動”、數據計算量較大的技術問題,提出了一種多約束條件下的個性化信息推薦方法及信息推薦系統,以實現在多個物品已經被明確指定的約束條件下,再根據物品之間的潛在聯系進行其他物品的推薦。本發明結合了統計學原理、關聯數據挖掘算法、聚類算法、基于物品的推薦算法、大數據列式存儲等多項技術。
為了實現上述目的,本發明提供一種多約束條件下的個性化信息推薦方法,包括:
步驟1)利用數據庫中存儲的所有物品信息構建元數據,對各種物品對應的元數據進行編碼;
步驟2)根據元數據的編碼數據對用戶關聯的物品數據進行數字編碼為“1”,對用戶未關聯的物品數據進行數字編碼為“0”,形成用戶數據;
步驟3)以預設的若干種約束物品能夠關聯到同一用戶為約束條件檢索所有用戶數據,如果能夠檢索出滿足該約束條件的用戶數據,則將所有滿足約束條件的用戶數據組成數據集,并執行步驟5),否則執行步驟4);
步驟4)將所有約束物品進行分組,在用戶數據中根據分組分別進行聚類分析,尋找聚類結果最好的分組作為檢索條件,以該檢索條件進行物品的統計推薦,獲得對應的推薦結果;
步驟5)對步驟3)中的數據集進行關聯分析,如果僅獲得一個滿足支持度和置信度設定條件的物品組合,則將該物品組合作為推薦結果,否則,如果獲得至少兩個滿足支持度和置信度設定條件的物品組合,則利用協同過濾推薦算法對不同組的物品組合進行打分評估,挑選評分最高的物品組合作為推薦結果,否則,如果沒有獲得滿足支持度和置信度設定條件的物品組合,則根據步驟3)中的約束條件進行物品的統計推薦,獲得對應的推薦結果。
作為上述技術方案的進一步改進,所述統計推薦的步驟包括:根據用戶數據的列式存儲結構,分別檢索出各種物品對應在用戶數據中數字編碼為“1”的總數,然后根據總數大小對物品排序,選擇排序靠前的物品進行推薦。
作為上述技術方案的進一步改進,所述步驟4)中聚類分析的步驟包括:
步驟101)分別在每一分組數據中任意選擇k個數據對象作為該分組的初始聚類中心;
步驟102)根據每個聚類中數據對象的均值作為中心對象,根據以下公式計算每個數據對象與中心對象的距離,并根據最小距離重新對相應數據對象進行劃分,所述的公式表示為:
其中,
步驟103)根據以下公式重新計算每個聚類中數據對象的均值:
其中,||ci||表示第i個聚類中數據對象的總數;
步驟104)計算標準測度函數,當滿足下列函數收斂時,則算法終止,否則繼續執行步驟102),
其中,
步驟201)通過掃描數據集累計除約束物品外的每種物品對應在用戶數據中數字編碼為“1”的計數,并收集滿足設定支持度條件的物品作為待選物品,組成數據集合l1;
步驟202)使用數據集合l1尋找包含兩項待選物品組合的數據集合l2,以此類推,直至無法找到包含k項待選物品組合的數據集合;
步驟203)從包含k-1項待選物品組合的數據集合中遞歸計算出置信度最高的關聯規則,輸出具有最大支持度和置信度的關聯物品組合。
作為上述技術方案的進一步改進,所述支持度的計算公式表示為:
其中,x表示物品,d表示數據集中包含的物品種類組成的物品集合,稱d中包含x的交易的個數與d中總的交易個數之比為x在d中的支持度,記作support(x)。
作為上述技術方案的進一步改進,所述置信度的計算公式表示為:
其中,x→y表示x對y的關聯規則,x和y均表示物品,定義關聯規則的置信度為物品x∪y的支持度與x的支持度之比。
本發明還提供了一種多約束條件下的信息推薦系統,所述的系統包括存儲器、處理器及存儲在存儲器上并在處理器上運行的計算機程序,所述處理器執行所述程序時實現以下步驟:
步驟1)利用數據庫中存儲的所有物品信息構建元數據,對各種物品對應的元數據進行編碼;
步驟2)根據元數據的編碼數據對用戶關聯的物品數據進行數字編碼為“1”,對用戶未關聯的物品數據進行數字編碼為“0”,形成用戶數據;
步驟3)以預設的若干種約束物品能夠關聯到同一用戶為約束條件檢索所有用戶數據,如果能夠檢索出滿足該約束條件的用戶數據,則將所有滿足約束條件的用戶數據組成數據集,并執行步驟5),否則執行步驟4);
步驟4)將所有約束物品進行分組,在用戶數據中根據分組分別進行聚類分析,尋找聚類結果最好的分組作為檢索條件,以該檢索條件進行物品的統計推薦,獲得對應的推薦結果;
步驟5)對步驟3)中的數據集進行關聯分析,如果僅獲得一個滿足支持度和置信度設定條件的物品組合,則將該物品組合作為推薦結果,否則,如果獲得至少兩個滿足支持度和置信度設定條件的物品組合,則利用協同過濾推薦算法對不同組的物品組合進行打分評估,挑選評分最高的物品組合作為推薦結果,否則,如果沒有獲得滿足支持度和置信度設定條件的物品組合,則根據步驟3)中的約束條件進行物品的統計推薦,獲得對應的推薦結果。
本發明的一種多約束條件下的個性化信息推薦方法及信息推薦系統優點在于:
本發明通過約束條件的使用和聚類算法的使用,對數據集合進行數據補全和數據壓縮,解決數據稀疏“冷啟動”問題,在此基礎上,結合基于物品的推薦算法和關聯數據挖掘算法解決因信息不足導致的推薦結果不準確的問題;通過對算法的并行化運算過程的改造,解決數據計算量大的技術問題。
附圖說明
圖1為協同過濾技術中基于用戶的推薦的操作原理示意圖;
圖2為協同過濾技術中基于物品的推薦的操作原理示意圖;
圖3為本發明中提供的多約束條件下的個性化信息推薦方法的結構框圖;
圖4為本發明中構建元數據的操作示意圖;
圖5為本發明中用戶數據編碼的操作示意圖;
圖6為本發明中多約束條件下的列式條件檢索示意圖;
圖7為本發明中約束條件部分滿足下的并行條件聚類示意圖;
圖8為本發明中約束條件部分滿足下的統計排序示意圖;
圖9為本發明中約束條件全部滿足下的關聯分析示意圖;
圖10為本發明中約束條件全部滿足下的統計排序示意圖;
具體實施方式
下面結合附圖和實施例對本發明所述的一種多約束條件下的個性化信息推薦方法及信息推薦系統進行詳細說明。
參照圖3所示的結構框圖,本發明提供的一種多約束條件下的個性化信息推薦方法具體包括以下步驟:
步驟1)利用數據庫中存儲的所有物品信息構建元數據,對各種物品對應的元數據進行編碼;
步驟2)根據元數據的編碼數據對用戶關聯的物品數據進行數字編碼為“1”,對用戶未關聯的物品數據進行數字編碼為“0”,形成用戶數據(源數據編碼);
步驟3)以預設的若干種約束物品能夠關聯到同一用戶為約束條件檢索所有用戶數據,如果能夠檢索出滿足該約束條件的用戶數據,則將所有滿足約束條件的用戶數據組成數據集,并執行步驟5),否則執行步驟4);
步驟4)將所有約束物品進行分組,在用戶數據中根據分組分別進行聚類分析,尋找聚類結果最好的分組作為檢索條件,以該檢索條件進行物品的統計推薦,獲得對應的推薦結果;
步驟5)對步驟3)中的數據集進行關聯分析,如果僅獲得一個滿足支持度和置信度設定條件的物品組合,則將該物品組合作為推薦結果,否則,如果獲得至少兩個滿足支持度和置信度設定條件的物品組合,則利用協同過濾推薦算法對不同組的物品組合進行打分評估,挑選評分最高的物品組合作為推薦結果,否則,如果沒有獲得滿足支持度和置信度設定條件的物品組合,則根據步驟3)中的約束條件進行物品的統計推薦,獲得對應的推薦結果。
基于上述個性化信息推薦方法,所述步驟4)中的聚類算法基本步驟包括:
步驟(1)分別在每一分組數據中任意選擇k個數據對象作為該分組的初始聚類中心;
步驟(2)根據每個聚類中數據對象的均值作為中心對象,根據下式計算每個數據對象與這些中心對象的距離;并根據最小距離重新對相應數據對象進行劃分;所述的公式表示為:
其中,
步驟(3)根據下式重新計算每個聚類中數據對象的均值(中心對象):
其中,||ci||表示第i個聚類中數據對象的總數;
步驟(4)計算標準測度函數,當滿足下列函數收斂時,則算法終止;如果條件不滿足,則回到步驟(2)。
其中,
關聯分析算法的基本步驟包括:
(1)首先,通過掃描數據集累計除約束物品外的每個物品的計數,并收集滿足最小支持度設定條件的物品作為待選物品組成數據集合l1;
(2)然后,使用數據集合l1尋找包含2項待選物品組合的數據集合l2;
(3)然后,使用數據集合l2尋找包含3項待選物品組合的數據集合l3;
(4)以此類推,直到不能再找到包含k項待選物品組合的數據集合;從包含k-1項待選物品組合的數據集合開始遞歸計算置信度最高的關聯規則,輸出具有最大支持度和置信度的關聯物品。
假定x是一個物品,d是數據集中包含的物品種類組成的物品集合,稱d中包含x的交易的個數與d中總的交易個數之比為x在d中的支持度,記作support(x),即支持度的計算公式表示為:
支持度很低的規則可能只是偶然出現,通過設定支持度的判定閾值,能夠刪除那些不令人感興趣的規則。
對形如x→y的關聯規則(x和y都是物品),定義規則的置信度為物品集合d中既包含x也包含y的交易個數與d中包含x的交易個數之比,或者說是物品x∪y的支持度與x的支持度之比,即置信度的計算公式記作:
本發明還提供了一種多約束條件下的信息推薦系統,該系統包括多項技術的組合應用,最終構成一套擁有多個模塊的推薦系統。本系統主要包括存儲器、處理器及存儲在存儲器上并在處理器上運行的計算機程序,具體包括由計算機程序及上述硬件形成的4個模塊,詳細介紹如下:
1.數據預處理模塊
該模塊主要實現兩項功能,一是構建元數據,這里元數據指的是數據庫中對所要記錄的物品信息資源的結構化的描述信息。其作用為:描述信息資源或數據本身的特征和屬性,規定了數據庫所收錄物品的名稱和物品的屬性。對元數據進行編碼就是將數據庫中以文字描述的物品名稱和屬性轉化為計算機可以識別的信息,方便后續算法調用的碼字或編號(圖4中以物品總數100為例進行元數據編碼),方便計算機后續對用戶數據進行識別和在數據庫中進行物品檢索和統計。
二是根據元數據編碼對用戶數據進行數字編碼,方便計算機后續識別和在數據庫中進行項目檢索和統計。
用戶數據是指用戶與物品之間的關聯關系數據,關聯關系數據可表示為購買商品的數據。經過數字編碼后的用戶數據就是一串用“0”和“1”編碼的行向量,購買過的商品編碼為“1”,沒有購買過的商品編碼為“0”(如圖5所示)。
2.多約束檢索模塊
該模塊主要實現多約束條件檢索,如圖6所示,以a1、a3、a55、a78、a99為已知約束物品為例,用戶數據以列式存儲方式進行存儲,通過并行運算的方式分別檢索出a1=1,a3=1,a55=1,a78=1,a99=1的不同數據集,然后通過數據集的交運算,匯總出滿足a1=1且a3=1且a55=1且a78=1且a99=1的用戶數據組成數據集。
3.部分約束條件推薦模塊
該模塊主要實現在多約束檢索模塊中沒有檢索出滿足全部約束條件時的物品推薦。該模塊主要實現兩項功能,一是基于約束條件的聚類分析,將所有約束物品進行分組,通過并行運算的方式在用戶數據中根據分組分別聚類,尋找聚類結果最好,即類和類之間距離比較遠,類內元素之間距離比較近的聚類結果,包含約束物品最多的聚類結果作為新的檢索條件,如圖7所示,以a1、a3、a55、a78、a99為已知約束物品,通過分組聚類后選擇a1、a3、a55、a99為最優分組。
二是根據新的檢索條件進行物品的統計推薦(統計排序1),結合用戶數據的列式存儲結構,分別檢索出各項物品對應在用戶數據中數字編碼為“1”的總數,然后根據總數大小對物品排序,選擇排序靠前的物品優先進行推薦,如圖8所示,以a1、a3、a55、a99為新約束物品為例,ni為物品統計得出的數量。
4.全約束條件推薦模塊
該模塊主要實現在多約束檢索模塊中滿足全部約束條件時的物品推薦。該模塊主要實現兩項功能,一是關聯分析,將多約束檢索模塊中生成的數據集進行關聯分析如圖9所示,以a1、a3、a55、a78、a99為已知約束物品,如果僅獲得一個滿足支持度和置信度設定條件的物品組合,則將該物品組合作為推薦結果,否則,當在相同支持度和置信度條件下,關聯分析所能得出的物品組合可能會有多組,例如圖8中示出的a2、a7、a33、a48、a84是一組推薦物品,a6、a18、a34、a43、a88是另一組推薦物品,在這種情況下,則使用基于物品的協同過濾推薦算法對不同組的推薦物品組合進行打分評估,挑選評分靠前的組合進行推薦。
二是當關聯分析時,如果沒有獲得滿足支持度或置信度設定條件的物品組合時,可以降低支持度或置信度的取值,但如果達到預先設定的最小閾值還沒有找到滿足支持度或置信度的物品組合時,則根據多約束檢索模塊中的約束條件進行物品的統計推薦(統計排序2),結合用戶數據的列式存儲結構,分別檢索出各項物品對應在用戶數據中數字編碼為“1”的總數,然后根據總數大小對物品排序,選擇排序靠前的物品優先進行推薦,如圖9所示,以a1、a3、a55、a78、a99為已知約束物品為例,ni為物品統計得出的數量。
本發明結合了統計學原理、關聯數據挖掘算法、聚類算法、基于物品的推薦算法、大數據列式存儲等多項技術實現了多約束條件下的快速個性化推薦。所述系統以模塊組合的方式進行耦合,其中關聯數據挖掘算法、聚類算法并無特別指代,依據不同應用領域的數據特征可以被同類算法優化取代。基于物品的協同過濾推薦算法也主要是在計算不同物品間的距離和關系時根據不同評價指標的使用效果來互相取代,例如可選擇歐幾里德距離評價、皮爾遜相關度評價、加權排序推薦、互信息排序推薦等算法。
總之,本發明可以在指明多個物品必須被選定的條件下,實現向客戶快速推薦相關聯物品的功能。如果用戶或物品信息不足,可以使用聚類方法解決數據稀疏問題,使用統計方法推薦相關物品;如果用戶或物品信息充足,可以使用關聯規則方法并結合統計方法實現相關聯物品的推薦。在所有物品的檢索統計過程中,使用大數據列式存儲技術,以物品作為關鍵詞進行檢索,而不是以用戶數據作為關鍵詞進行檢索,針對大數據量場景下,采用列式檢索方式使計算速度可以達到100萬條/秒的效果,提高了計算速度。
最后所應說明的是,以上實施例僅用以說明本發明的技術方案而非限制。盡管參照實施例對本發明進行了詳細說明,本領域的普通技術人員應當理解,對本發明的技術方案進行修改或者等同替換,都不脫離本發明技術方案的精神和范圍,其均應涵蓋在本發明的權利要求范圍當中。
- 還沒有人留言評論。精彩留言會獲得點贊!