一種信息處理方法、裝置、設備及計算機可讀存儲介質與流程
本技術涉及人工智能,尤其涉及一種信息處理方法、裝置、設備及計算機可讀存儲介質。
背景技術:
1、通常,問答系統的知識庫是由多個文檔組成的,且將一個問題和答案(q&a)對看作一個文檔;可以利用文本匹配技術從知識庫中為用戶推薦與用戶輸入的問題的相似問題以及相似問題的答案。
2、在整理知識庫時,通常采用單一語義相似度聚類的方法將知識庫中相似的問題確定為一個問題簇,且之后將構建出的多個問題簇在知識庫以平行存儲結構進行存儲;但是,在相關技術在確定問題簇的過程中,單一語義相似度聚類的方法通常獲取的問題的語義出現偏差,從而將不相似的問題確定為一個問題簇,導致確定問題簇的準確度較低,且多個問題簇以平行存儲結構,導致在知識庫中檢索用戶輸入的問題的效率較低。
技術實現思路
1、為解決上述技術問題,本技術實施例期望提供一種信息處理方法、裝置、設備及計算機可讀存儲介質,可以解決相關技術中的確定問題簇的準確度較低和在知識庫中檢索用戶輸入的問題的效率較低的問題,不僅提高了確定文本之間相似度的準確率,還提高了在目標文本集中檢索用戶輸入的問題的效率。
2、本技術的技術方案是這樣實現的:
3、一種信息處理方法,所述方法包括:
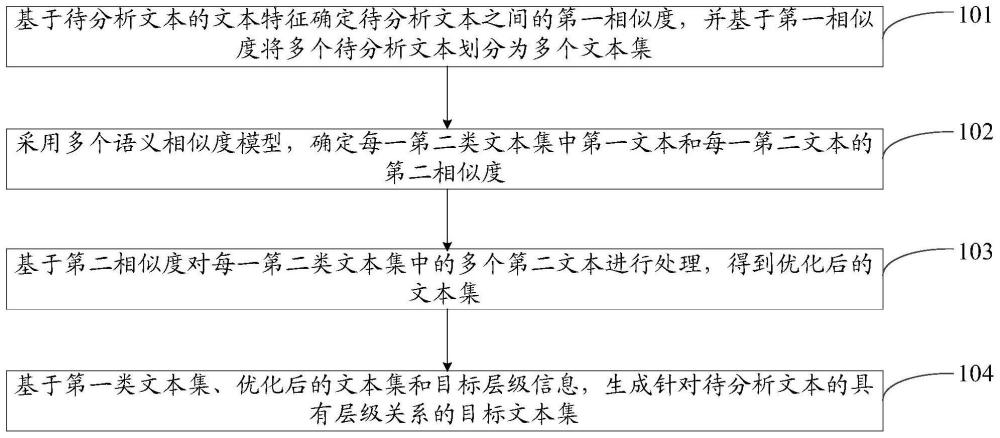
4、基于待分析文本的文本特征確定所述待分析文本之間的第一相似度,并基于所述第一相似度將多個所述待分析文本劃分為多個文本集;其中,所述多個文本集包括具有一個待分析文本的第一類文本集和具有多個待分析文本的第二類文本集;
5、采用多個語義相似度模型,確定每一所述第二類文本集中第一文本和每一第二文本的第二相似度;其中,所述每一第二類文本集中包括所述第一文本和多個所述第二文本;
6、基于所述第二相似度對每一所述第二類文本集中的多個所述第二文本進行處理,得到優化后的文本集;
7、基于所述第一類文本集、所述優化后的文本集和目標層級信息,生成針對所述待分析文本的具有層級關系的目標文本集。
8、上述方案中,所述基于待分析文本的文本特征確定所述待分析文本之間的第一相似度,并基于所述第一相似度將多個所述待分析文本劃分為多個文本集,包括:
9、確定所述待分析文本之間的相同字符的數量;
10、確定所述待分析文本之間的總字符的數量與所述相同字符的數量的差值;
11、對所述差值和所述相同字符的數量進行運算,得到所述第一相似度;
12、基于所述第一相似度和相似度閾值,將所述多個待分析文本劃分為所述多個文本集。
13、上述方案中,所述基于所述第一相似度和相似度閾值,將所述多個待分析文本劃分為所述多個文本集,包括:
14、在所述第一相似度中的最大相似度滿足第一閾值的情況下,基于第一關鍵字將所述多個待分析文本劃分為所述第一類文本集;
15、在所述最大相似度滿足第二閾值的情況下,確定滿足第三閾值的待分析文本為第一文本集;
16、在所述最大相似度滿足第四閾值的情況下,基于滿足第五閾值的待分析文本的數量,將所述待分析文本劃分為第二文本集;
17、在所述最大相似度滿足第六閾值的情況下,基于所述第一相似度對所述待分析文本進行排序,得到第一排序后的文本;
18、將所述第一排序后的文本中的m個待分析文本確定為第三文本集;其中,所述第二類文本集包括所述第一文本集、所述第二文本集和所述第三文本集。
19、上述方案中,所述基于第一關鍵字將所述多個待分析文本劃分為所述第一類文本集,包括:
20、在所述待分析文本中不存在所述第一關鍵字的情況下,將所述待分析文本劃分為第一類文本集;
21、在所述待分析文本中存在所述第一關鍵字的情況下,刪除所述待分析文本中的所述第一關鍵字,并確定刪除關鍵字后的文本之間的第三相似度;
22、在所述第三相似度中的最大相似度滿足所述第一閾值的情況下,將所述刪除關鍵字后的文本對應的待分析文本劃分為第一類文本集。
23、上述方案中,所述在所述最大相似度滿足第四閾值的情況下,基于滿足第五閾值的待分析文本的數量,將所述待分析文本劃分劃分為第二文本集,包括:
24、在滿足第五閾值的待分析文本的數量大于或者等于第一數量的情況下,將所述滿足第五閾值的待分析文本劃分為所述第二文本集;
25、在所述滿足第五閾值的待分析文本的數量小于所述第一數量的情況下,基于所述第一相似度對所述待分析文本進行排序,得到第二排序后的文本;
26、將所述第二排序后的文本中的所述第一數量個待分析文本劃分為所述第二文本集。
27、上述方案中,所述基于所述第二相似度對每一所述第二類文本集中的多個所述第二文本進行處理,得到優化后的文本集,包括:
28、針對所述第二相似度中的目標相似度滿足第七閾值的第二類文本集,確定所述第二類文本集中的所述第一文本和所述每一第二文本各自為第一優化后的文本集;
29、針對所述第二相似度中的目標相似度滿足第八閾值的第二類文本集,將所述第二類文本集中滿足所述第八閾值的第二文本和所述第一文本確定為第二優化后的文本集;其中,所述優化后的文本集包括所述第一優化后的文本集和所述第二優化后的文本集。
30、上述方案中,所述信息處理方法還包括:
31、針對所述第二相似度中的目標相似度不滿足所述第七閾值和所述第八閾值的第二類文本集,確定每一所述不滿足所述第七閾值和所述第八閾值的第二類文本集中的待處理文本與所述第二優化后的文本集中的文本之間的第四相似度;
32、確定每一所述第二優化后的文本集中的第一目標文本;
33、基于所述第四相似度和所述第一目標文本,將所述待處理文本劃分為所述第一優化后的文本集和第二優化后的文本集。
34、上述方案中,所述確定每一所述第二優化后的文本集中的第一目標文本,包括:
35、確定所述第二優化后的文本集中的所述第一文本和每一所述第二文本的密度參數和距離參數;
36、基于所述密度參數和所述距離參數確定所述第一目標文本。
37、上述方案中,所述基于所述第四相似度和所述第一目標文本,將所述待處理文本劃分為所述第一優化后的文本集和第二優化后的文本集,包括:
38、在所述第四相似度中存在p個第四相似度大于第九閾值的情況下,將所述待處理文本劃分為所述第二優化后的文本集;
39、在所述第四相似度中不存在p個第四相似度大于所述第九閾值的情況下,基于所述第一目標文本,將所述待處理文本劃分為所述第一優化后的文本集和第二優化后的文本集。
40、上述方案中,所述基于所述第一目標文本,將所述待處理文本劃分為所述第一優化后的文本集和第二優化后的文本集,包括:
41、確定每一所述待處理文本與每一所述第一目標文本之間的第五相似度;
42、在所述第五相似度中的最大相似度小于或等于所述第一目標文本對應的所述第二相似度的情況下,將所述待處理文本劃分為所述第二優化后的文本集;
43、在所述第五相似度中的最大相似度大于所述第一目標文本對應的所述第二相似度的情況下,將所述待處理文本劃分為所述第一優化后的文本集。
44、上述方案中,所述信息處理方法還包括:
45、確定所述第一類文本集中的文本的第一出現總次數和所述優化后的文本集中的文本的第二出現總次數;
46、將所述第一出現總次數標記在所述第一類文本集中,并將所述第二出現總次數標記在所述優化后的文本集中,得到更新后的文本集。
47、上述方案中,所述信息處理方法還包括:
48、針對所述更新后的文本集中的出現總次數小于第一次數閾值的第三文本,確定與所述第三文本為同一層級的所述出現總次數滿足第二次數閾值的第四文本;其中,所述更新后的文本集中包括所述第三文本和所述第四文本;
49、基于所述第三文本中的第二關鍵字和所述第四文本中除第三關鍵字之外的字符,得到第五文本。
50、上述方案中,所述信息處理方法還包括:
51、接收用戶輸入的詢問文本;
52、從所述目標文本集中獲取與所述詢問文本的匹配度滿足第一匹配度閾值的第二目標文本,并顯示所述第二目標文本的應答信息;
53、在所述目標文本集中不存在所述第二目標文本情況下,從所述目標文本集中確定與所述詢問文本的匹配度滿足第二匹配度閾值的第三目標文本,并顯示所述第三目標文本的應答信息。
54、一種信息處理裝置,所述裝置包括:
55、第一處理單元,用于基于待分析文本的文本特征確定所述待分析文本之間的第一相似度,并基于所述第一相似度將多個所述待分析文本劃分為多個文本集;其中,所述多個文本集包括具有一個待分析文本的第一類文本集和具有多個待分析文本的第二類文本集;
56、確定單元,用于采用多個語義相似度模型,確定每一所述第二類文本集中第一文本和每一第二文本的第二相似度;其中,所述每一第二類文本集中包括所述第一文本和多個所述第二文本;
57、第二處理單元,用于基于所述第二相似度對每一所述第二類文本集中的多個所述第二文本進行處理,得到優化后的文本集;
58、生成單元,用于基于所述第一類文本集、所述優化后的文本集和目標層級信息,生成針對所述待分析文本的具有層級關系的目標文本集。
59、一種信息處理設備,所述設備包括:處理器、存儲器和通信總線;
60、所述通信總線用于實現所述處理器和所述存儲器之間的通信連接;
61、所述處理器用于執行所述存儲器中存儲的信息處理程序,以實現如上述的信息處理方法的步驟。
62、一種計算機可讀存儲介質,所述存儲介質存儲有一個或者多個程序,所述一個或者多個程序可被一個或者多個處理器執行,以實現如上述的信息處理方法的步驟。
63、本技術實施例所提供的信息處理方法、裝置、設備及計算機可讀存儲介質,首先基于待分析文本的文本特征確定待分析文本之間的第一相似度,并基于第一相似度將多個待分析文本劃分為多個文本集,且多個文本集包括具有一個待分析文本的第一類文本集和具有多個待分析文本的第二類文本集,然后采用多個語義相似度模型,確定每一第二類文本集中第一文本和每一第二文本的第二相似度,且每一第二類文本集中包括第一文本和多個第二文本,再基于第二相似度對每一第二類文本集中的多個第二文本進行處理,得到優化后的文本集,之后基于第一類文本集、優化后的文本集和目標層級信息,生成針對待分析文本的具有層級關系的目標文本集,如此,先基于文本特征確定出只具有一個待分析文本的第一類文本集和具有多個待分析文本的第二類文本集,之后僅對具有多個待分析文本的第二類文本集再進行處理,減少了處理的數據量,且對第二類文本集再處理時,采用的是多個語義相似度模型確定文本之間的相似度,從而提高了確定文本之間相似度的準確率,且之后還構建了具有層級關系的目標文本集,提高了在目標文本集中檢索用戶輸入的問題的效率。
- 還沒有人留言評論。精彩留言會獲得點贊!