通過上下文中強化學習進行的智能體控制的制作方法
背景技術:
1、本說明書涉及使用機器學習模型來處理數據。
2、機器學習模型接收輸入并基于接收到的輸入來生成輸出,例如預測輸出。一些機器學習模型是參數模型,并且基于接收到的輸入和模型參數的值來生成輸出。
3、一些機器學習模型是深度模型,深度模型采用多層模型來為接收到的輸入生成輸出。例如,深度神經網絡是一種深度機器學習模型,該深度機器學習模型包括輸出層和一個或多個隱藏層,一個或多個隱藏層各自將非線性變換應用于接收到的輸入以生成輸出。
技術實現思路
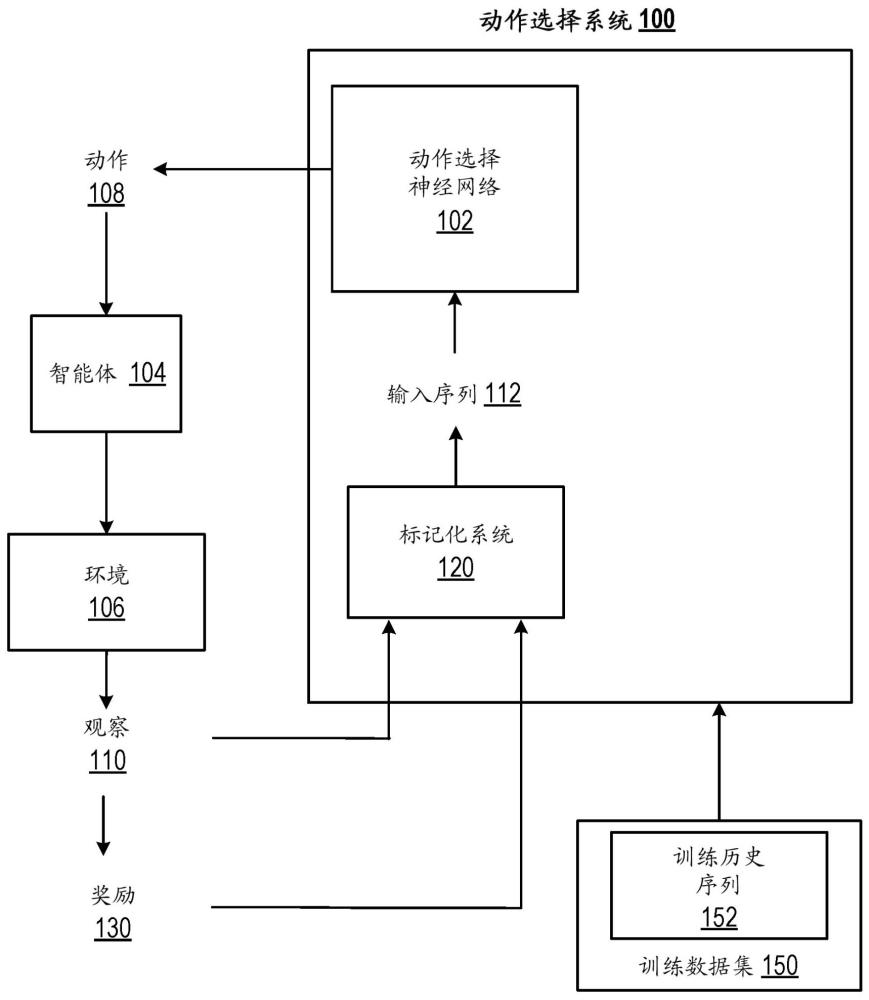
1、本說明書總體上描述了一種在一個或多個位置的一個或多個計算機上被實現為計算機程序的系統,該系統控制與環境交互的智能體以使用動作選擇神經網絡在環境中執行任務。
2、更具體地說,智能體選擇神經網絡表示“上下文中”(“?in-context”)強化學習算法。也就是說,由于在使用動作選擇神經網絡來控制智能體的同時以來自與環境的先前交互的上下文數據為條件,隨著上下文數據的量增加,動作選擇神經網絡可以選擇導致任務上的提高的性能(相對于智能體控制期間的較早時間點)的動作,而無需更新動作選擇神經網絡的參數。換句話說,隨著可用數據量的增加,動作選擇神經網絡可以“模仿”強化學習算法的性能,而不需要更新神經網絡的參數,即,不需要進一步訓練神經網絡。
3、可以實現本說明書中描述的主題的特定實施例,以便實現以下優點中的一個或多個優點。
4、本說明書描述了一種動作選擇神經網絡,該動作選擇神經網絡可以用于在于訓練數據集上被訓練之后對新任務執行上下文中強化學習。當執行新任務時,動作選擇神經網絡可以比用于生成訓練數據集的強化學習算法更加數據高效得多,例如,因為多演員算法(multi-actor?algorithm)被“蒸餾”為單演員算法、因為系統在生成訓練數據集時對訓練回合進行子采樣、或者兩者。
5、而且,使用動作選擇神經網絡“學習”新任務也比使用rl算法學習用于新任務的策略消耗少得多的計算資源,因為由于動作選擇神經網絡不再需要在“學習”期間被更新而不需要計算上昂貴的反向傳遞。也就是說,因為動作選擇神經網絡僅通過觀察更多的上下文并且在不更新神經網絡的權重的情況下來對新任務進行改進,所以不需要梯度計算,并且因此不需要反向傳遞,同時仍然改進新任務上的性能。
6、另外,分布式強化學習算法在學習過程期間需要分布式演員和學習者之間的大量的網絡通信。通過利用已經訓練的動作選擇神經網絡,這種網絡通信被大大減少或者甚至完全消除。也就是說,通過利用所描述的“上下文中”強化學習方案,該系統可以利用在一個或多個硬件裝置的單個集上實現的單個演員來實現在給定新任務上的與使用需要各自被實現在一個或多個硬件裝置的不同集上的多個演員和一個或多個學習者的分布式強化學習算法學習任務時相當或比其更好的性能。因此,網絡通信被大大減少,因為不需要在演員和學習者之間傳輸權重更新,并且不需要從重放緩沖區采樣轉變。
7、另外,在訓練之后并且當“上下文中學習”新任務時,存儲需求至少與分布式強化學習算法相當,并且在許多情況下甚至相對于分布式強化學習算法顯著降低,因為僅需要存儲在當前時間步處當前上下文對動作選擇神經網絡所需的經標記化的觀察、動作和獎勵,并且可以丟棄上下文不再需要的任何經標記化的觀察和獎勵。另一方面,分布式強化學習算法需要維護重放緩沖區,該重放緩沖區包括大量轉變,學習者可以從這些轉變中進行采樣以訓練神經網絡。通過去除維護這個大的重放緩沖區的需求,所描述的技術大大降低了“學習”新任務的存儲需求。
8、而且,動作選擇神經網絡可以完全“離線”地進行訓練,即不需要用于控制智能體。這避免了對現實世界智能體的損害或磨損,還提供了分攤和并行化訓練工作負載的能力。
9、而且,一旦被訓練,相同的動作選擇神經網絡可以用于“學習”許多新任務,而不需要任何進一步的訓練,從而大大減少多任務系統內所需的計算資源的量。
10、本說明書的主題的一個或多個實施例的細節在附圖和以下描述中進行闡述。根據描述、附圖和權利要求,該主題的其他特征、方面和優點將變得顯而易見。
技術特征:
1.一種由一個或多個計算機執行的方法,所述方法包括:
2.如權利要求1所述的方法,其中,在每個訓練歷史序列內,所述回合子序列根據在所述訓練期間執行對應的任務回合的順序被排序。
3.如任一項前述權利要求所述的方法,其中,每個訓練歷史序列包括在用于所述任務的智能體在用于所述任務的所述策略的所述訓練期間的多個不同時間點處正在被所述策略控制的同時生成的轉變。
4.如權利要求3所述的方法,其中,用于所述任務的所述策略由具有多個權重的機器學習模型表示,并且其中,所述訓練歷史序列包括在用于所述任務的所述智能體正在根據所述多個權重的多個不同的權重值集被控制的同時生成的轉變。
5.如任一項前述權利要求所述的方法,其中:
6.如任一項前述權利要求所述的方法,其中,獲得包括多個任務中的每個任務的相應的訓練歷史序列的訓練數據集針對所述任務中的一個或多個任務中的每個任務包括:
7.如權利要求6所述的方法,其中,獲得包括多個任務中的每個任務的相應的訓練歷史序列的訓練數據集針對所述一個或多個任務中的每個任務進一步包括:
8.如權利要求6或權利要求7所述的方法,其中,重復執行以下操作包括:
9.如權利要求1至8中任一項所述的方法,其中,獲得包括多個任務中的每個任務的相應的訓練歷史序列的訓練數據集針對所述任務中的一個或多個任務中的每個任務包括:
10.如任一前述權利要求所述的方法,其中,在所述多個訓練步驟中的一個或多個訓練步驟:
11.一種由一個或多個計算機執行的用于控制智能體執行任務的任務回合序列的方法,所述方法針對當前任務回合中的時間步序列中的多個時間步中的每個時間步包括:
12.如權利要求11所述的方法,其中,控制智能體執行任務的任務回合序列包括控制所述智能體,同時保持所述動作選擇神經網絡的參數的值固定為通過執行如權利要求1至10中任一項所述的相應的操作來訓練所述動作選擇神經網絡所確定的經訓練的值。
13.如權利要求11或權利要求12所述的方法,其中,所述動作選擇神經網絡是因果transformer神經網絡。
14.如權利要求11或權利要求12所述的方法,其中,所述動作選擇神經網絡是遞歸神經網絡。
15.如權利要求11至14中任一項所述的方法,其中,所述輸入序列包括所述先前轉變子序列,之后是所述當前轉變子序列,以及之后是表示所述當前觀察的所述一個或多個標記,并且其中,所述先前轉變子序列和所述當前轉變子序列在所述輸入序列內根據生成對應的轉變的順序被排序。
16.如任一項前述權利要求所述的方法,其中,每個任務需要所述策略來控制與相應的環境交互的相應的智能體,其中,對于所述任務中的一個或多個任務,所述相應的智能體是與現實世界環境交互的機械智能體。
17.如權利要求16所述的方法,其中,所述機械智能體是機器人。
18.如任一項前述權利要求所述的方法,其中,每個任務需要所述策略來控制與相應的環境交互的相應的智能體,其中,對于所述任務中的一個或多個任務,所述環境是包括電子設備的多個項的服務設施的現實世界環境,并且所述智能體是被配置為控制所述服務設施的操作的電子智能體。
19.如任一項前述權利要求所述的方法,其中,每個任務需要所述策略來控制與相應的環境交互的相應的智能體,其中,對于所述任務中的一個或多個任務,所述環境是用于制造產品的現實世界制造環境,并且所述智能體包括被配置為控制制造單元或操作來制造所述產品的機器的電子智能體。
20.一種系統,包括:
21.一個或多個存儲指令的非暫時性計算機存儲介質,所述指令在由一個或多個計算機執行時致使所述一個或多個計算機執行如權利要求1至19中任一項所述的相應的方法的操作。
技術總結
用于控制智能體的方法、系統和設備,包括編碼在計算機存儲介質上的計算機程序。特別地,當在新的任務上控制智能體時,可以使用執行上下文中強化學習的動作選擇神經網絡來控制智能體。
技術研發人員:邁克爾·拉斯金,沃洛季米爾·姆尼赫,王路宇,薩蒂德爾·辛格·巴韋亞
受保護的技術使用者:淵慧科技有限公司
技術研發日:
技術公布日:2025/4/24
- 還沒有人留言評論。精彩留言會獲得點贊!