基于saas區(qū)域訂單與運力供需大盤的統計存儲方法和系統與流程
本發(fā)明涉及saas互聯網代駕平臺,特別涉及基于saas區(qū)域訂單與運力供需大盤的統計存儲方法和系統。
背景技術:
1、在互聯網代駕服務的技術框架中,saas代駕平臺扮演著連接車隊服務商(即運力供應方)與乘客(即需求方)的關鍵角色,構成了一個復雜的雙邊交易平臺。該平臺依托于網絡預約系統,實現乘客訂單的即時發(fā)起與服務商專業(yè)代駕司機的有效對接。此過程不僅涉及高效的算法撮合機制,以確保訂單與運力的精準匹配,還融合了嚴格的風險控制措施,旨在保障服務過程中的人員與車輛安全,確保乘客能夠順利抵達目的地。
2、核心挑戰(zhàn)之一在于撮合成交的效率與效果,這是代駕平臺運營的痛點所在。平臺需為乘客高效匹配運力,同時最大化利用有限的運力資源。然而,現實場景中的供需關系呈現出顯著的時間與空間不均衡性。時間上,訂單量存在明顯的高峰與低谷周期,而運力的出車時間則具有較大的不確定性;空間上,訂單分布呈現出熱點區(qū)域與冷門區(qū)域的鮮明對比,且運力本身亦處于動態(tài)流動狀態(tài)。這一系列因素共同作用,極易導致運力閑置與乘客長時間等待并存的供需失衡問題。
3、為應對這一挑戰(zhàn),現有技術體系主要依賴于定時全量更新與實時增量更新兩種策略。然而,這兩種方法均存在固有局限。定時全量更新策略因數據更新周期較長,難以滿足實時性要求;而實時增量更新雖能提升即時性,但隨時間推移,數據準確性逐漸下降,且其增量統計過程需等待全量統計完成,導致在高并發(fā)情境下數據一致性問題凸顯。
4、此外,當前解決方案在數據統計時采用統一的網格粒度,未充分考慮地域差異、市場競爭態(tài)勢及不同城市運營商的特定策略需求。因此,對于訂單熱力值、運力熱力值及綜合熱力值的計算,缺乏針對不同區(qū)域特性的靈活調整能力。鑒于此,構建一種能夠動態(tài)調整網格粒度的供需分析模型顯得尤為重要。該模型應能夠根據各區(qū)域的實際情況,如競爭強度、市場需求變化及運營商策略調整等,自動優(yōu)化網格劃分,以實現更加精細化的供需匹配與預測,從而有效提升代駕服務的整體效率與用戶體驗。
5、為此,本發(fā)明提出基于saas區(qū)域訂單與運力供需大盤的統計存儲方法和系統。
技術實現思路
1、有鑒于此,本發(fā)明實施例希望提供基于saas區(qū)域訂單與運力供需大盤的統計存儲方法和系統,以解決或緩解現有技術中存在的技術問題,即數據多變,數據更新實時性不高的問題,并對此至少提供一種有益的選擇;本發(fā)明的技術方案是這樣實現的:
2、第一方面,基于saas區(qū)域訂單與運力供需大盤的統計存儲方法:
3、(一)概述:
4、本發(fā)明旨在構建一個高效、實時的代駕平臺數據處理系統,以優(yōu)化供需匹配和提升用戶體驗。通過監(jiān)聽訂單和運力兩側的數據流,實時捕獲乘客和司機的動態(tài)事件,為后續(xù)的數據處理和分析提供基礎。方案采用分布式緩存和定時批量寫入的技術,既保證了數據處理的實時性,又降低了數據庫的寫入壓力。通過熱力計算和數據統計,方案能夠準確反映不同區(qū)域、不同時間段的供需情況,為運營決策提供有力支持。同時,供需差的計算進一步揭示了市場的不平衡狀態(tài),為調整運力分布和制定營銷策略提供了依據。最終,通過數據查詢與展示模塊,用戶能夠直觀地了解到全城或附近的實時供需大盤信息,從而做出更加明智的決策。
5、(二)技術方案:
6、為實現上述技術目標,輸入saas代駕平臺數據處理激活指令,該指令由系統管理員或自動化腳本發(fā)出,標志著數據處理流程的正式啟動。然后開始執(zhí)行如下操作流程。
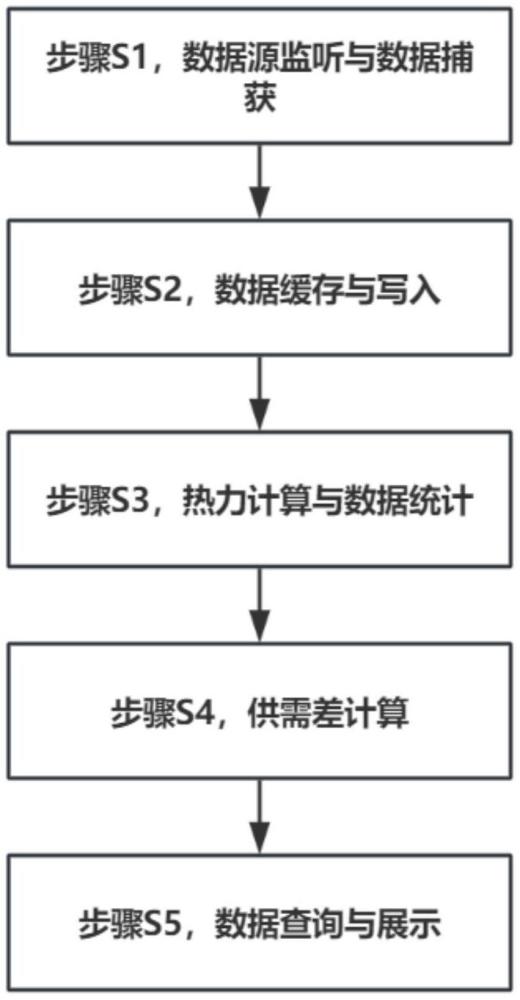
7、2.1步驟s1,數據源監(jiān)聽與數據捕獲:
8、訂單監(jiān)聽模塊監(jiān)聽訂單側的數據流,實時捕獲乘客事件;
9、運力監(jiān)聽模塊開始監(jiān)聽資產側和位置側的數據流,實時捕獲司機事件;
10、2.1.1步驟s100,訂單監(jiān)聽模塊初始化與配置:
11、根據業(yè)務需求,設置訂單監(jiān)聽模塊需要捕獲的數據類型、格式和條件,包括乘客下單和取消訂單事件;建立與訂單側數據源的穩(wěn)定連接。
12、2.1.2步驟s101,實時捕獲乘客事件:
13、當識別到乘客下單或取消訂單事件時,進行捕獲;對捕獲到的乘客事件數據進行初步處理,包括格式轉換和去重,以便后續(xù)處理。
14、2.1.3步驟s102,運力監(jiān)聽模塊初始化與配置:
15、根據運力管理的需求,設置運力監(jiān)聽模塊需要捕獲的數據類型、格式和條件,包括司機出車、收車和上報點位;與資產側和位置側的數據源建立連接,確保能夠實時獲取運力數據。
16、2.1.4步驟s103,實時捕獲司機事件:
17、當識別到司機出車、收車或上報點位時,進行捕獲。
18、2.2步驟s2,數據緩存與寫入:
19、將預處理后的數據首先寫入jvm緩存,進行城市維度的首次分區(qū);定時將jvm緩存中的數據批量寫入redis緩存池,分別存入訂單緩存池和運力緩存池。
20、2.2.1步驟s200,數據寫入jvm緩存與首次分區(qū):
21、在數據寫入jvm緩存時,根據城市維度進行首次分區(qū);將屬于同一城市的數據歸類存儲,以便后續(xù)根據城市進行快速的數據檢索和處理。
22、2.2.2步驟s201,定時批量寫入redis緩存池:
23、配置定時任務,根據業(yè)務需求設定合理的寫入頻率。例如,可以設置為每5分鐘、10分鐘或更長時間間隔執(zhí)行一次寫入操作。
24、在定時任務觸發(fā)時,從jvm緩存中讀取需要寫入redis緩存池的數據。為了提高寫入效率,可以對數據進行批量處理,即一次性處理多條數據而不是單條處理。
25、根據數據的類型(訂單數據或運力數據),將數據分別存入redis緩存池中的訂單緩存池和運力緩存池。這樣做有助于數據的分類管理和快速檢索。在數據寫入redis緩存池后,利用redis的持久化機制(如rdb快照或aof日志)確保數據的安全性和可靠性。即使系統發(fā)生故障,也能通過redis的持久化文件恢復數據。
26、2.3步驟s3,熱力計算與數據統計:
27、定時任務觸發(fā)熱力計算模塊,對redis緩存池中的數據進行熱力計算。
28、按不同粒度的蜂窩和5分鐘的時間分片,統計發(fā)單總數、取消訂單總數、未接單訂單總數以及運力總數。
29、2.3.1步驟s300,定時任務觸發(fā):
30、設置定時任務的觸發(fā)頻率(例如每5分鐘觸發(fā)一次)。
31、2.3.2步驟s301,觸發(fā)熱力計算模塊:
32、調用熱力計算模塊的接口或函數,傳遞時間范圍和蜂窩粒度。
33、2.3.3步驟s302,數據獲取:
34、建立與redis緩存池的連接;
35、根據預定義的鍵和值格式,從redis緩存池中獲取相關的訂單和運力數據;
36、2.2.4步驟s303,熱力計算:
37、調用根據業(yè)務需求預先定義不同的蜂窩粒度(地理區(qū)域或時間段);
38、對獲取的數據進行遍歷,根據蜂窩粒度和時間分片(5分鐘)進行統計;
39、計算每個蜂窩在每個時間分片內的發(fā)單總數、取消訂單總數、未接單訂單總數以及運力總數。
40、2.2.5步驟s304,數據統計與存儲:
41、將計算得到的各項統計數據按照蜂窩粒度、時間分片進行匯總。
42、將匯總的統計結果存儲到指定的數據庫或緩存中,以便后續(xù)查詢和分析。
43、2.4步驟s4,供需差計算:
44、根據統計結果,計算各個蜂窩區(qū)域的供需差;
45、將統計結果和供需差數據批量寫入elasticsearch引擎并建立相應的索引,以便后續(xù)查詢。
46、2.4.1步驟s400,獲取統計結果:
47、根據之前步驟中存儲的統計結果的位置,從數據庫或緩存中檢索出各個蜂窩區(qū)域的發(fā)單總數、取消訂單總數、未接單訂單總數以及運力總數;根據業(yè)務需求,計算需求與供給之間的差值。
48、2.4.2步驟s401,寫入elasticsearch引擎數據:
49、將計算得到的供需差數據與之前的統計結果整合在一起,形成完整的數據集。為數據集添加時間戳、蜂窩區(qū)域標識和數據來源的元數據,以便后續(xù)查詢和分析。
50、建立與elasticsearch引擎的連接,確保連接穩(wěn)定且能夠正常寫入數據;
51、使用elasticsearch提供的批量寫入api或工具,將整理好的數據集批量寫入到elasticsearch引擎中。
52、2.5步驟s5,數據查詢與展示:
53、當用戶通過查詢接口查詢全城或附近的實時供需大盤信息時,從elasticsearch中檢索相關數據,并展示給用戶。
54、(三)解決技術問題的機制:
55、3.1實時數據源監(jiān)聽與捕獲:
56、通過訂單監(jiān)聽模塊和運力監(jiān)聽模塊,實時監(jiān)聽并捕獲來自訂單側和運力側的數據流。任何乘客下單、取消訂單或司機出車、收車等行為都能被即時捕捉到,從而確保了數據的實時性和準確性。
57、3.2定時批量寫入與redis緩存池:
58、本發(fā)明采用定時批量寫入的方式,將jvm緩存中的數據轉移到redis緩存池。redis緩存池分為訂單緩存池和運力緩存池,分別存儲訂單數據和運力數據。這種策略既保證了數據的實時更新,又避免了頻繁寫入數據庫帶來的性能開銷。
59、3.3熱力計算與動態(tài)數據統計:
60、通過定時觸發(fā)的熱力計算模塊,本發(fā)明對redis緩存池中的數據進行熱力計算,評估不同區(qū)域的供需熱度。同時,按不同粒度的蜂窩和時間分片統計發(fā)單總數、取消訂單總數、未接單訂單總數以及運力總數等關鍵指標。這些動態(tài)數據為運營決策提供了實時、準確的信息支持。
61、3.4elasticsearch支持下的高效數據檢索:
62、本發(fā)明將統計結果和供需差數據批量寫入elasticsearch,并利用其強大的搜索引擎功能支持高效的數據檢索。這使得用戶能夠迅速查詢到全城或附近的實時供需大盤信息,為決策提供了極大的便利。
63、第二方面,基于saas區(qū)域訂單與運力供需大盤的統計存儲系統:
64、如圖6所示,該系統用于執(zhí)行如上述所述的統計存儲方法,包括:
65、(1)負責監(jiān)聽訂單側的數據流,實時捕獲乘客的下單和取消訂單事件的數據源監(jiān)聽模塊。
66、(2)負責監(jiān)聽資產側和位置側的數據流,實時捕獲司機的出車、收車和上報點位事件的運力監(jiān)聽模塊。
67、(3)數據緩存與寫入模塊,包括:
68、jvm緩存:用于臨時存儲預處理后的數據,支持快速訪問。
69、redis緩存池:作為高性能的分布式緩存解決方案,用于持久化保存jvm緩存中的批量數據。redis緩存池進一步細分為訂單緩存池和運力緩存池,分別存儲訂單數據和運力數據。
70、(4)定時觸發(fā),對redis緩存池中的數據進行熱力計算,同時按不同粒度的蜂窩和時間分片統計發(fā)單總數、取消訂單總數、未接單訂單總數以及運力總數的熱力計算與數據統計模塊。
71、(5)基于數據統計模塊的結果,計算各個蜂窩區(qū)域的供需差的供需差計算模塊。
72、(6)基于elasticsearch引擎存儲供需差計算模塊的輸出數據以及其他統計結果,并建立相應的索引的數據持久化與檢索模塊。
73、(7)提供用戶查詢接口,允許用戶查詢全城或附近的實時供需大盤信息的數據查詢與展示模塊。
74、與現有技術相比,本發(fā)明的有益效果是:
75、一、提升數據實時性與準確性:通過實時監(jiān)聽數據源并捕獲動態(tài)事件,結合高效的數據預處理與緩存策略,本發(fā)明確保了數據的實時更新與高度準確性。這為用戶提供了即時、可靠的供需信息,有助于做出更加明智的決策。
76、二、優(yōu)化供需匹配:本發(fā)明通過熱力計算和動態(tài)數據統計,精確揭示了不同區(qū)域、不同時間段的供需情況。這使得平臺能夠更加精準地調配運力,滿足乘客的即時需求,從而提升供需匹配的效率和用戶滿意度。
77、三、降低系統壓力與提高性能:采用分布式緩存和定時批量寫入的技術,本發(fā)明有效降低了數據庫的寫入壓力,提高了系統的整體性能。使得系統能夠輕松應對高并發(fā)場景,確保服務的穩(wěn)定性和可用性。
78、四、提升運營決策效率:本發(fā)明提供的實時供需大盤信息,為運營人員提供了直觀、全面的數據支持。這使得他們能夠迅速識別市場趨勢,制定和調整運營策略,從而提升決策效率和運營效果。
79、五、增強用戶體驗:通過優(yōu)化供需匹配和提供實時供需信息,本發(fā)明顯著提升了用戶體驗。乘客能夠更快地找到合適的代駕司機,而司機也能更高效地接到訂單,從而實現雙贏。
- 還沒有人留言評論。精彩留言會獲得點贊!