一種基于多層融合對比解碼框架的大模型幻覺去除方法
本發明涉及計算機,具體為一種基于多層融合對比解碼框架的大模型幻覺去除方法。
背景技術:
1、隨著人工智能技術的快速發展,大型語言模型(large?language?models,簡稱llms)已成為自然語言處理(nlp)領域的一個熱點研究方向。這些模型通過在海量文本數據上的預訓練,學習到了豐富的語言知識和模式,從而在多種nlp任務上展現出了令人印象深刻的性能。
2、然而,大型語言模型在在執行自然語言處理任務時所面臨的一個關鍵問題:幻覺(hallucination)現象。幻覺現象指的是模型在生成文本時,時常會輸出與現實世界知識不符、或是與用戶期望相違背的內容。這種現象不僅損害了模型輸出的準確性和可信度,也限制了模型在需要高精確度的應用場景中的使用,如自動新聞生成、智能客服、教育輔助等。這種現象的產生可能源于模型在訓練過程中接觸到的數據質量問題、模型結構設計不合理、或是解碼策略存在缺陷等多種因素。
3、現有的研究嘗試通過引入額外的外部知識庫、改進模型架構或優化解碼策略等方法來減輕幻覺現象,但這些方法往往需要大量的人工干預、計算資源消耗巨大,且難以適應不同的應用場景和數據分布,進一步導致模型輸出的準確性和真實性較差。此外,這些方法在實際應用中可能還會遇到模型泛化能力下降、可擴展性差等問題。
技術實現思路
1、有鑒于此,本發明提供一種基于多層融合對比解碼框架的大模型幻覺去除方法,以至少解決上述問題。
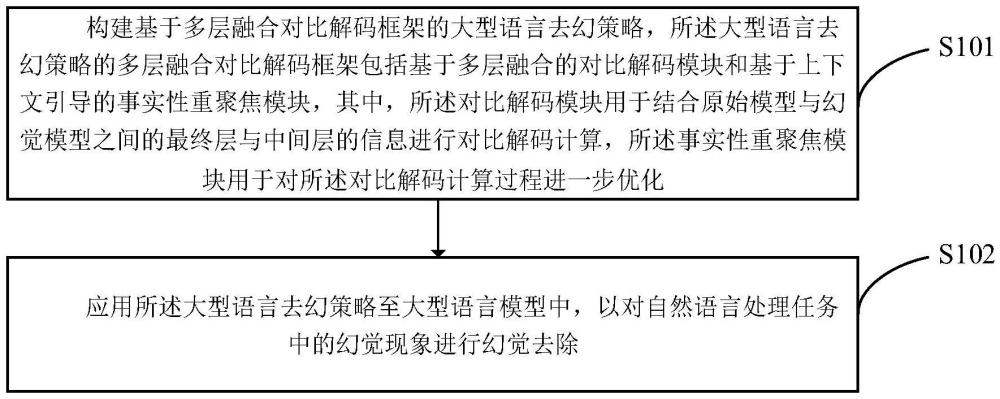
2、本發明提供的一種基于多層融合對比解碼框架的大模型幻覺去除方法,包括:構建基于多層融合對比解碼框架的大型語言去幻策略,所述大型語言去幻策略的多層融合對比解碼框架包括基于多層融合的對比解碼模塊和基于上下文引導的事實性重聚焦模塊,其中,所述對比解碼模塊用于結合原始模型與幻覺模型之間的最終層與中間層的信息進行對比解碼計算,所述事實性重聚焦模塊用于對所述對比解碼計算過程進一步優化;應用所述大型語言去幻策略至大型語言模型中,以對自然語言處理任務中的幻覺現象進行幻覺去除。
3、在一種實現方式中,所述對比解碼模塊用于結合原始模型與幻覺模型之間的最終層與中間層的信息進行對比解碼計算,具體包括:a.幻覺模型構建:通過在包含非事實數據的數據集上對所述原始模型進行有監督微調,向所述原始模型中注入幻覺信息,得到幻覺模型;b.對比解碼:將查詢queryx={x1,x2,...,xn}分別輸入至所述原始模型和所述幻覺模型中,分別得到對應的文本回復輸出分布,進一步通過所述原始模型和所述幻覺模型的文本回復的概率分布相減實現對比解碼;c.多層融合:在所述原始模型和所述幻覺模型之間進行多層融合的對比解碼,結合兩個模型最終輸出層和中間層之間的對比解碼結果進行融合。
4、在另一種實現方式中,步驟a中幻覺模型構建過程表示為:
5、θ*=ft(θ,d)
6、其中,ft表示監督微調操作,θ表示原始模型,θ*表示幻覺模型,d是包含幻覺信息的數據集。
7、在另一種實現方式中,步驟b中對比解碼過程表示為:
8、ft=logp(χt|χ<t;θ)-λlogp(χt|χ<t;θ*)
9、p(χt|χ<t;θ)=softmax(logitθ(χt|χ<t))
10、
11、其中,ft表示所述原始模型和所述幻覺模型之間最終層對比解碼的結果,θ表示原始模型,θ*表示幻覺模型,λ是最終層解碼時控制對比解碼比例的超參數,p(χt|χ<t;θ)表示自回歸大型語言模型的標準解碼過程,p(χt|x<t;θ)在回復生成過程中,根據前面t-1個詞的結果預測第t個詞,logitθ表示文本生成的預測概率,softmax為激活函數。
12、在另一種實現方式中,步驟c中多層融合過程包括:
13、c11.并行地對所述原始模型和所述幻覺模型之間的中間層進行對比解碼,這一步驟用公式表述為:
14、f′t=logp(χt|χ<t;θ;l)-λ’logp(χt|χ<t;θ*;l)
15、其中,f’t表示兩個模型之間中間層對比解碼的結果,λ’是中間層解碼時控制對比解碼比例的超參數,l是一個超參數,用于指定人為選擇的所述還原模型和所述幻覺模型的中間層;
16、c12.將所述原始模型和所述幻覺模型最終層對比解碼的結果和中間層對比解碼的結果進行融合,以實現更加完善的對比解碼計算,這一計算過程用公式表述為:
17、fml=ft+ωf’t
18、其中,fml表示多層融合對比解碼的結果,ω是控制多層融合比例的超參數。
19、在另一種實現方式中,所述事實性重聚焦模塊用于對所述對比解碼計算過程進一步優化,具體包括:
20、d.在所述大型語言模型編碼的過程中向查詢query引入上下文引導,以鼓勵所述大型語言模型在對比解碼過程中更加關注句子中代表事實性的關鍵詞匯或短語,這一步驟用公式表述為:
21、ftr=logp(χt|(χ<t||χcontext);θ)-λ”logp(χt|(χ<t||χcontext);θ*)
22、其中,ftr表示事實性重聚焦模塊的對比解碼結果,λ”是所述事實性重聚焦模塊解碼時控制對比解碼比例的超參數,xcontext表示引入的上下文信息;
23、e.將所述事實性重聚焦模塊的輸出分布與多層融合對比解碼模塊的輸出分布進行融合,以進一步提高所述大型語言模型輸出的真實性,這一過程表示為:
24、ffinal=fml±ω’ftr
25、p(χt|χ<t)=softmax(ffinal)
26、其中,ffinal表示所述大型語言模型最終的輸出分布,ω’是最終輸出分布計算時控制融合比例的超參數。
27、綜上,本發明提出了一種基于多層融合對比解碼框架的大模型幻覺去除方法,該方法通過原始模型和幻覺模型之間多層融合的對比解碼調整模型的解碼策略,提高模型輸出的準確性和真實性,進一步提升模型的性能。同時在對比解碼框架中,借助基于上下文引導的事實性重聚焦模塊來增強事實性編碼,提升模型對于文本生成的事實性的感知能力,有效緩解了現有的大型語言模型幻覺去除方法所具有的計算效率較低、依賴外部數據資源、幻覺去除精度不足等問題。
技術特征:
1.一種基于多層融合對比解碼框架的大模型幻覺去除方法,其特征在于,包括:
2.根據權利要求1所述的方法,其特征在于,所述對比解碼模塊用于結合原始模型與幻覺模型之間的最終層與中間層的信息進行對比解碼計算,具體包括:
3.根據權利要求2所述的方法,其特征在于,步驟a中幻覺模型構建過程表示為:
4.根據權利要求3所述的方法,其特征在于,步驟b中對比解碼過程表示為:
5.根據權利要求4所述的方法,其特征在于,步驟c中多層融合過程包括:
6.根據權利要求5所述的方法,其特征在于,所述事實性重聚焦模塊用于對所述對比解碼計算過程進一步優化,具體包括:
技術總結
本發明提供一種基于多層融合對比解碼框架的大模型幻覺去除方法,包括:構建基于多層融合對比解碼框架的大型語言去幻策略,大型語言去幻策略的多層融合對比解碼框架包括基于多層融合的對比解碼模塊和基于上下文引導的事實性重聚焦模塊,其中,所述對比解碼模塊用于結合原始模型與幻覺模型之間的最終層與中間層的信息進行對比解碼計算,所述事實性重聚焦模塊用于對所述對比解碼計算過程進一步優化;應用所述大型語言去幻策略至大型語言模型中,以對自然語言處理任務中的幻覺現象進行幻覺去除。本發明的技術方案不僅能夠提高大型語言模型輸出的準確性和真實性,還具有較好的泛化能力和較低的計算成本,適用于多種不同的自然語言處理任務和應用場景。
技術研發人員:李成明,陳定緯,楊敏,胡希平
受保護的技術使用者:深圳北理莫斯科大學
技術研發日:
技術公布日:2025/4/24
- 還沒有人留言評論。精彩留言會獲得點贊!