一種結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法
本發明屬于人工智能,涉及一種多文檔問答檢索方法,具體涉及一種結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法。
背景技術:
1、當前,大型語言模型在各個領域得到了廣泛應用,特別是在問答(qa)任務中表現出顯著進展。然而,盡管這些模型強大,但由于它們未見過預訓練數據之外的內容,且容易產生幻覺,尤其在開放領域中,檢索增強型大模型的重要性愈發凸顯。這種模型的輸出可以基于真實可靠的外部知識進行構建。
2、以往的檢索增強型大模型方法通常采用一次性檢索策略,即僅使用用戶輸入來檢索相關知識。對于簡單問題,這種單次檢索方式能夠有效滿足信息需求,適用于單跳問答或單跳事實驗證。然而,對于復雜的信息需求,例如多跳推理和長格式問答,單一檢索顯然不夠。為了解決復雜的多跳任務,近期研究通過整個回答過程中的多次知識收集來提升效果。例如,使用中間信息生成或將前驅搜索信息作為查詢條件。這類方法在多跳問答任務中表現良好,但其所依賴的知識庫往往基于傳統的啟發式bm25方法或僅使用深度密集嵌入,導致檢索重復率高、多樣性不足等問題。此外,基于三元組構建的知識圖譜(kgqa)方法雖然有潛力,但在三元組抽取上耗時且難以擴展。
3、綜上所述,現有技術所存在的問題:
4、1、知識庫的局限性。現有的知識庫多依賴傳統的bm25方法或深度密集嵌入,導致檢索結果重復率高且多樣性不足。
5、2、知識圖譜構建的困難。基于三元組的知識圖譜(kgqa)方法在三元組抽取上耗時且難以擴展,限制了其實際應用。
6、3、對多次知識收集的依賴。雖然通過多次知識收集提升效果,但仍未能解決基礎知識庫的質量和多樣性問題。
技術實現思路
1、針對現有技術所存在的上述問題,本發明提供了一種結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法。該方法進一步完善和優化了文檔知識圖譜的構建與遍歷方式,分別設計基于bert類模型去構建圖譜構建,設計kgp3算法優化檢索遍歷方式。在圖譜遍歷過程中,本發明結合主問題及已獲得節點,生成涉及下一個需要節點信息的子問題,從鄰居節點中精確挑選出最合適的文檔節點,并判斷該節點與初始問題的相關性,若不相關,則不列入后續檢索列表。這種方法不僅高效且具備可追溯性和可解釋性,同時抽象概括了模型在圖譜遍歷中選擇下一跳節點的整體過程。為了降低成本,本發明還對小型編碼器-解碼器t5模型進行了改進,并在該模型中引入對比學習機制,進一步提升了小型模型的檢索性能。
2、本發明的目的是通過以下技術方案實現的:
3、一種結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,包括如下步驟:
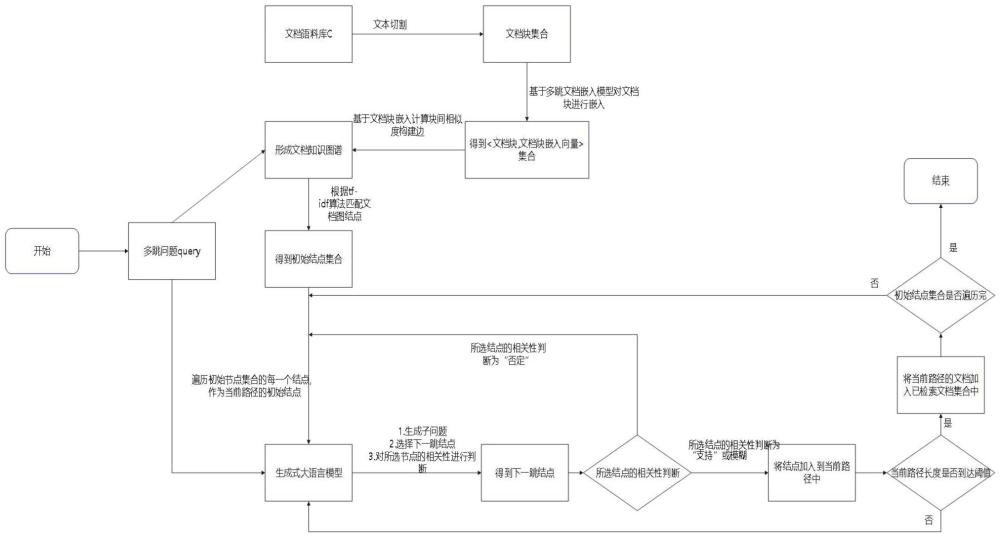
4、步驟1、文檔型知識圖譜的構建:
5、步驟1.1、文檔庫獲取:獲取一個包含某個領域大量相關文檔的文檔庫;
6、步驟1.2、文本切割:在獲取到文檔庫后,對文檔進行分詞處理,將文檔分割為一個個獨立的文塊;
7、步驟1.3、基于預訓練語言模型對文檔塊進行嵌入:使用預訓練語言模型,提取每個文檔塊的語義特征;
8、步驟1.4、計算相似度:基于文檔塊嵌入向量計算文塊間的相似度,形成邊,對于每個文檔節點基于相似度閾值和top-k算法連接鄰居文檔節點,形成文檔知識圖譜;
9、步驟2、基于生成式語言模型的文檔知識圖譜多跳檢索生成式問答:
10、步驟21、生成初始候選集:以用戶的問題作為查詢條件,在步驟1獲取的文檔庫中進行tf-idf算法搜索,得到一組與之相關的節點,即初始候選集;
11、步驟22、迭代擴展文檔集:
12、步驟221、遍歷初始節點集合:遍歷步驟21生成的初始候選集中的每一個節點,并將其作為當前路徑的初始節點;
13、步驟222、問題與已檢索到的節點輸入生成式語言模型:將問題以及當前路徑上的節點信息輸入到生成式語言模型中,基于kgp3算法得到文檔知識圖譜多跳問答,具體步驟如下:
14、(1)生成子問題:結合主問題以及已經獲得的節點生成一個子問題涉及下一個需要的節點應該包含的信息;
15、(2)根據生成的子問題拿到下一跳節點:使用生成的子問題進一步在步驟1構建的文檔型知識圖譜中檢索新的節點,這些節點即為下一步要訪問的目標;
16、(3)對所選節點的相關性進行判斷:如果節點的相關性被判斷為“支持”或"模糊",則將該節點加入到當前路徑中,并基于此節點繼續進行下一跳的選擇;如果節點的相關性被判斷為“拒絕”,則跳過當前節點,繼續遍歷初始節點集合;支持:表示當前節點在回答查詢時高度支持種子節點,模糊:表示當前節點在一定程度上支持種子節點,拒絕:表示對于主問題沒有任何有價值的信息;
17、(4)判斷當前路徑長度是否到達閾值:檢查當前路徑的長度是否達到了預先設定的閾值,如果未達到閾值,則繼續執行步驟(1)至步驟(3);如果達到閾值,則將當前路徑的文檔加入到已檢索文檔集合中;
18、(5)判斷初始節點集合是否遍歷完:檢查初始節點集合是否已經被完全遍歷,如果尚未遍歷完,繼續遍歷初始節點集合;如果遍歷完畢,則結束整個檢索過程,得到檢索文檔集合;
19、所述生成式語言模型為生成式大語言模型或小型編碼器-解碼器模型t5模型,當生成式語言模型為小型編碼器-解碼器模型t5模型時,對其進行微調,為每條微調數據增加了負樣本同時引入對比學習頭:t5模型的輸入包括一個問題和與之相關的檢索證據,其中每個候選節點都代表一個潛在的相關信息片段,通過t5模型的編碼器,這些輸入被轉換成一個豐富的連續向量表示,然后送入解碼器生成或預測文本,在訓練期間,為每個正樣本提供兩個負樣本,形成正樣本和負樣本的對比;
20、步驟23、經過步驟21和步驟22后,對檢索得到的文檔集合進行去重后處理步驟,得到最終的檢索文檔集合,并入用戶問題一并輸入生成式語言模型得到答案回復。
21、相比于現有技術,本發明具有如下優點:
22、本發明提出了kgp3方法,用于進一步改進模型的檢索流程,這種方法高效且可追溯可解釋性,同時也抽象概括了模型在圖譜遍歷選擇下一跳節點的整體過程,具有一定的普適性,并且本發明可以方便的模擬這種通用的場景以構建一個微調數據集進一步提升模型的檢索能力。此外,本發明對t5模型進行了微調,同時針對其編碼器-解碼器的架構,以及kgp3方法的遍歷方法的特點,引入了對比學習頭。這種方法通過增加上下文對比目標,鼓勵模型選擇正確的文檔,同時避免選擇到其他容易混淆的文檔,從而加強模型的判斷能力。最后,將其接入微信中,實現機器人問答的落地應用,該方法降低人力和物力的損耗,促進企業高質量發展。
技術特征:
1.一種結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述方法包括如下步驟:
2.根據權利要求1所述的結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述步驟1.2包括如下步驟:
3.根據權利要求2所述的結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述步驟1.2還包括如下步驟:
4.根據權利要求1所述的結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述步驟1.3包括如下步驟:
5.根據權利要求1所述的結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述步驟1.4包括如下步驟:
6.根據權利要求1所述的結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述tf-idf算法包括以下步驟:
7.根據權利要求6所述的結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述步驟211還包括以下步驟:
8.根據權利要求1所述的結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述生成式語言模型為生成式大語言模型或小型編碼器-解碼器模型t5模型。
9.根據權利要求8所述的結合大語言模型與語義文檔圖譜的多文檔問答檢索方法,其特征在于所述生成式語言模型為小型編碼器-解碼器模型t5模型時,對其進行微調,為每條微調數據增加了負樣本同時引入對比學習頭:t5模型的輸入包括一個問題和與之相關的檢索證據,其中每個候選節點都代表一個潛在的相關信息片段,通過t5模型的編碼器,這些輸入被轉換成一個豐富的連續向量表示,然后送入解碼器生成或預測文本,在訓練期間,為每個正樣本提供兩個負樣本,形成正樣本和負樣本的對比。
技術總結
本發明公開了一種結合生成式語言模型與語義文檔圖譜的多文檔問答檢索方法,所述方法進一步完善和優化了文檔知識圖譜的構建與遍歷方式,分別設計基于bert類模型去構建圖譜構建,設計KGP3算法優化檢索遍歷方式。在圖譜遍歷過程中,結合主問題及已獲得節點,生成涉及下一個需要節點信息的子問題,從鄰居節點中精確挑選出最合適的文檔節點,并判斷該節點與初始問題的相關性,若不相關,則不列入后續檢索列表。這種方法不僅高效且具備可追溯性和可解釋性,同時抽象概括了模型在圖譜遍歷中選擇下一跳節點的整體過程。為了降低成本,還對小型編碼器?解碼器T5模型進行了改進,并在該模型中引入對比學習機制,進一步提升了小型模型的檢索性能。
技術研發人員:易志偉,張柏林,涂志瑩,初佃輝
受保護的技術使用者:哈爾濱工業大學
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!