一種基于提示學習的金融報表字段分級方法及系統
本發明涉及計算機自然語言處理,尤其是一種基于提示學習的金融報表字段分級方法及系統。
背景技術:
1、近年來,我國證券期貨市場信息化發展迅速,隨著技術進步和應用程度加深,各類市場主體積累了大量數據,對數字化建設提出了新的挑戰。比如,需要甄別數據使用需求、明確技術標準、識別風險隱患加強數據安全管理等。通過規范的數據分類、分級將有助于厘清數據資產、確定其重要性或敏感度,對應采取適當管理措施和安全防護,形成科學的數據資產管理與保護機制。
2、金融數據分類分級,從業務條線出發,首先對業務細分,解決業務分類問題,同時確定數據的管理主體;其次對數據細分,形成從總到分的樹形邏輯體系結構,在明確數據管理主體和業務分類的基礎上,重點解決數據分類問題;最后,在考慮確定數據形態的同時對分類后的數據確定級別。數據分級,即在數據分類基礎上,對已分類數據按照數據泄露或損壞造成的影響進行分級,形成統一的分類分級方法。數據級別從高到低,一般從4級到1級,4級(極高)數據主要用于行業內大型或特大型機構中的重要業務使用,一般針對特定人員公開,且僅為必須知悉的對象訪問或使用;3級(高)數據用于重要業務使用,一般針對特定人員公開,且僅為必須知悉的對象訪問或使用;2級(中)數據用于一般業務使用,一般針對受限對象公開,指內部管理且不宜廣泛公開的數據;1級(低)數據一般可被公開或可被公眾獲知、使用。在進行數據分級時,要遵循依從性、可執行性、時效性等原則。
3、雖然目前金融行業已經制定了一系列通用的數據分級標準和方法論,但由于在進行數據分級時,要根據企業性質、數據分類情況、影響范圍和影響程度等多個因素,綜合判定數據級別,仍然面臨過程復雜、工作量大的問題,難以進行合理、有效、全面的數據分級。通過查詢大量文獻資料進行調研分析,發現對于金融字段分級任務,一直缺乏有效自動化方法,目前金融數據字段分類主要依靠人力手動方式,工作量大、成本高。
技術實現思路
1、為解決現有技術在金融字段分級過程中一直缺乏有效自動化方法而出現的工作量大、成本高的問題,本發明的首要目的在于提供一種簡化金融文本分類的預測過程,實現金融報表字段智能分級,增強對文本的理解和分類能力,極大地提高分類的準確性和一致性的基于提示學習的金融報表字段分級方法。
2、為實現上述目的,本發明采用了以下技術方案:一種基于提示學習的金融報表字段分級方法,該方法包括下列順序的步驟:
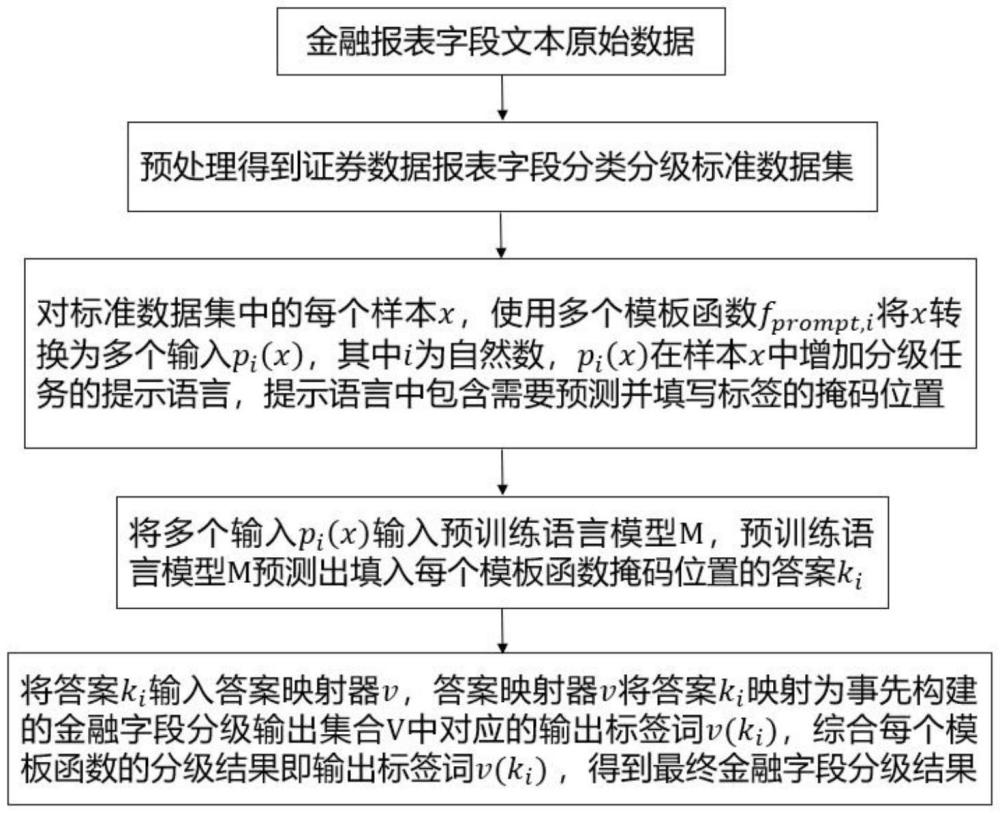
3、(1)對金融報表字段文本的原始數據進行預處理,得到預處理后的數據樣本,預處理后的數據樣本組成證券數據報表字段分類分級的標準數據集,所述預處理包括分詞處理和去除停用詞;
4、(2)對標準數據集中的每個樣本x,使用多個模板函數fprompt,i將x轉換為多個輸入pi(x),其中i為自然數,pi(x)在樣本x中增加分級任務的提示語言,提示語言中包含需要預測并填寫標簽的掩碼位置;
5、(3)將多個輸入pi(x)輸入預訓練語言模型m,預訓練語言模型m預測出填入每個模板函數掩碼位置的答案ki;
6、(4)將答案ki輸入答案映射器v,答案映射器v將答案ki映射為事先構建的金融字段分級輸出集合v中對應的輸出標簽詞v(ki),綜合每個模板函數的分級結果即輸出標簽詞v(ki),得到最終金融字段分級結果。
7、在步驟(1)中,所述分詞處理是指對金融報表字段文本的原始數據使用jieba分詞方法實現對文本的分詞,分詞采取不同粒度進行,所述不同粒度包括詞級別和字符級別,將文本數據轉換為分詞后對應的詞或字符序列;所述去除停用詞是指對經過分詞處理后得到的詞或字符序列,基于自定義停用詞表進行去除停用詞處理,即刪除在文本中出現頻率很高且無實際意義的詞。
8、在步驟(2)中,所述pi(x)的公式為:
9、pi(x)=fprompt,i(x,[mask])
10、其中,fprompt,i為不同的模板函數,x經fprompt,i(x,[mask])轉換后,將金融文本分類問題轉換為完形填空問題,即預訓練語言模型m以完形填空問題形式表示的pi(x)為輸入,mask為掩碼位置。
11、所述步驟(3)具體是指:通過使用預訓練語言模型m來計算答案ki填入模板函數掩碼位置的概率,并根據概率進行搜索,公式如下:
12、
13、其中,ffill(pi(x),ki)為預訓練語言模型m將不同的答案ki填入到pi(x)中的掩碼位置的過程;θ表示預訓練語言模型m的參數集合;k是文本分類任務的標簽集合即答案空間,即預訓練語言模型m所要預測的答案集合;search是一個argmax搜索或一個sampling函數,argmax搜索根據輸出分布直接找到每個提示語言最高得分的輸出,sampling函數根據預訓練語言模型m輸出的概率分布隨機生成輸出。
14、在步驟(4)中,所述答案映射器v的映射公式如下:
15、v=[v1,v2,v3,..,vi]=[v(k1),v(k2),v(k3),..,v(ki)]
16、vi=v(ki)
17、最終采取投票機制綜合每個模板函數的分級結果,統計每個分級結果的出現次數,較高出現次數的分級結果為預測得到的最終金融字段分級結果。
18、本發明的另一目的在于提供一種基于提示學習的金融報表字段分級系統,包括:
19、字段分類數據預處理模塊,用于對金融報表字段文本的原始數據進行預處理操作,得到證券數據報表字段分類分級標準數據集,其中預處理操作包括分詞處理和去除停用詞;
20、提示工程模塊,用于針對預處理后的數據樣本設計不同的提示語言和答案空間;
21、字段分級模塊,用于將經過提示工程模塊處理后的多個輸入pi(x)分別輸入到預訓練語言模型m,預測填入每個提示語言掩碼位置的答案,再通過答案映射器將所預測的答案映射為事先構建的金融字段分級輸出集合中對應的輸出標簽詞,綜合每個模板函數的分級結果即輸出標簽詞v(ki),得到最終金融字段分級結果。
22、由上述技術方案可知,本發明的有益效果為:第一,本發明簡化了金融文本分類的預測過程:本發明通過將金融文本分類問題轉化為類似完形填空的分類預測問題,有效利用了bert等預訓練語言模型在自然語言處理領域的優勢,減少了對大量人工特征工程的依賴,簡化了金融文本分類的預測流程,提高了分類效率和準確性;第二,本發明實現了金融報表字段智能分級:能夠智能化地對金融報表中的字段進行分類分級,與傳統基于規則的人工分類方法相比,本發明不依賴于硬編碼規則,可以根據實際需求動態調整分類標準;第三,本發明采用提示集成策略提高分類性能:采用提示集成策略,通過集成多個提示語言信息,增強了對文本的理解和分類能力,極大地提高了分類的準確性和一致性。
技術特征:
1.一種基于提示學習的金融報表字段分級方法,其特征在于:該方法包括下列順序的步驟:
2.根據權利要求1所述的基于提示學習的金融報表字段分級方法,其特征在于:在步驟(1)中,所述分詞處理是指對金融報表字段文本的原始數據使用jieba分詞方法實現對文本的分詞,分詞采取不同粒度進行,所述不同粒度包括詞級別和字符級別,將文本數據轉換為分詞后對應的詞或字符序列;所述去除停用詞是指對經過分詞處理后得到的詞或字符序列,基于自定義停用詞表進行去除停用詞處理,即刪除在文本中出現頻率很高且無實際意義的詞。
3.根據權利要求1所述的基于提示學習的金融報表字段分級方法,其特征在于:在步驟(2)中,所述pi(x)的公式為:
4.根據權利要求1所述的基于提示學習的金融報表字段分級方法,其特征在于:所述步驟(3)具體是指:通過使用預訓練語言模型m來計算答案ki填入模板函數掩碼位置的概率,并根據概率進行搜索,公式如下:
5.根據權利要求1所述的基于提示學習的金融報表字段分級方法,其特征在于:在步驟(4)中,所述答案映射器v的映射公式如下:
6.實施權利要求1至5中任一項所述的基于提示學習的金融報表字段分級方法的系統,其特征在于:包括:
技術總結
本發明涉及一種基于提示學習的金融報表字段分級方法,包括:對金融報表字段文本的原始數據進行預處理;將標準數據集中的每個樣本轉換為多個輸入;將多個輸入輸入預訓練語言模型,預測出填入每個模板函數掩碼位置的答案;將答案輸入答案映射器,將答案映射為對應的輸出標簽詞,綜合每個模板函數的輸出標簽詞,得到最終金融字段分級結果。本發明還公開了一種基于提示學習的金融報表字段分級系統。本發明減少了對大量人工特征工程的依賴,簡化金融文本分類的預測流程,提高了分類效率和準確性;實現了金融報表字段智能分級,可以根據實際需求動態調整分類標準增強對文本的理解和分類能力,極大地提高分類的準確性和一致性。
技術研發人員:王紅強,鮑彬江,謝新平
受保護的技術使用者:中國科學院合肥物質科學研究院
技術研發日:
技術公布日:2025/3/20
- 還沒有人留言評論。精彩留言會獲得點贊!