一種基于動態時間規整的下井異常識別方法及裝置與流程
本發明涉及數據處理,尤其涉及一種基于動態時間規整的下井異常識別方法及裝置。
背景技術:
1、在采礦行業中,下井異常識別需要綜合分析多個方面的數據,包括礦工的打卡記錄、生命特征監測(如心率、血氧飽和度等)、井下環境參數(如溫度、有害氣體濃度等)、人員行為與活動模式分析、實時定位追蹤、工作與休息時間管理、歷史數據對比、設備狀態監控以及通訊記錄審核,以便及時發現安全隱患和異常情況。
2、然而,現有技術面臨一些挑戰。首先,雖然可以采用生物識別技術來識別下井異常,但其準確性容易受到環境因素(如光線、溫度、濕度等)的影響,這可能導致井下打卡結果的不準確。其次,在利用余弦值判斷井下異常時,如果礦工因信號不良而無法生成數據,相關數據會被記錄為0,這樣將導致數值差異增大,進而影響余弦值的計算準確性,降低檢測的相似度。因此,這種方法并不完全可靠。
3、因此,目前尚未有一種全面有效的方法來識別下井異常情況。
技術實現思路
1、本發明所要解決的技術問題是針對現有技術的上述不足,提出一種基于動態時間規整的下井異常識別方法及裝置。該方法能夠全面而有效地識別井下的異常情況,顯著提高了異常識別的準確性,從而為下井安全提供了更為可靠的保障。
2、第一方面,本發明提供一種基于動態時間規整的下井異常識別方法,所述方法包括如下步驟:
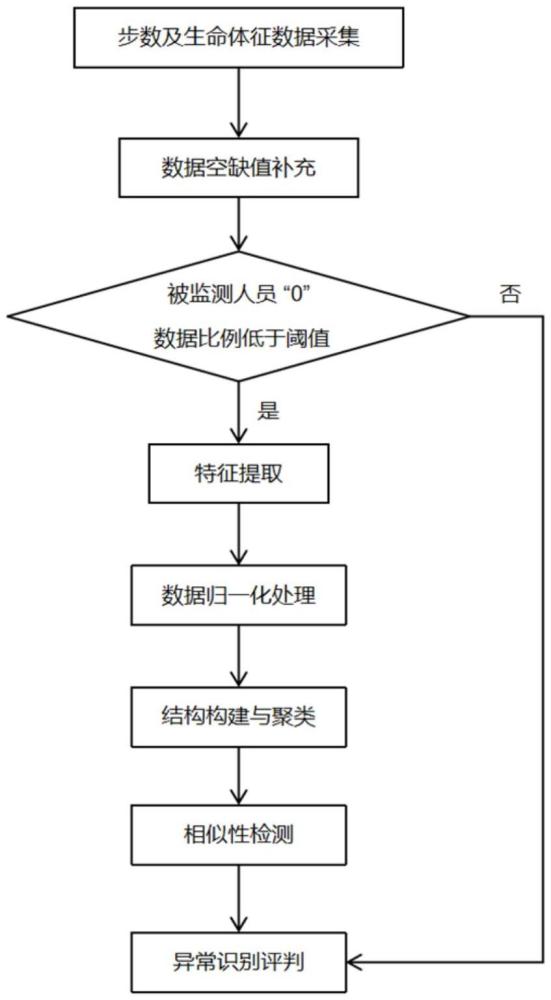
3、步驟s1:獲取礦工下井的監測數據;
4、步驟s3:從所述監測數據中提取人員步數和人員生命體征數據;
5、步驟s4:根據所述人員步數對礦工進行聚類,得到多個礦工聚類簇;
6、步驟s5:基于同一礦工聚類簇,根據動態時間規整得到任兩個礦工之間的人員生命體征相似度;
7、步驟s6:根據所述人員生命體征相似度,識別出下井異常數據,從而完成基于動態時間規整的下井異常識別。
8、進一步地,在步驟s3之前,所述方法還包括步驟s2;
9、步驟s2:對所述礦工下井的監測數據進行預處理,得到預處理后的監測數據;
10、所述步驟s1,具體包括如下步驟:
11、將所述礦工下井的監測數據中的空缺數值替換為0,得到0數據;
12、計算同一批礦工下井的監測數據中的0數據比例;
13、根據預設的異常比例閾值,判斷所述礦工下井的監測數據是否存在異常:
14、若0數據比例超出所述異常比例閾值,則判定所述礦工下井的監測數據存在異常,同時結束流程;若0數據比例未超出所述異常比例閾值,則判定所述礦工下井的監測數據不存在異常,同時進入步驟s2;
15、步驟s3具體包括:從所述預處理后的監測數據中提取人員步數和人員生命體征數據。
16、進一步地,所述步驟s4,具體包括如下步驟:
17、步驟s41:輸入數據集f={on},設置最小對象參數minpts和半徑參數ε;
18、其中,on表示礦工在預設時間節點的步數數據,最小對象參數minpts用于確定核心對象的領域范圍,半徑參數ε用于定義搜索領域的范圍;核心對象是指在數據集中,位于給定半徑參數ε內并且至少擁有minpts個鄰居的對象;
19、步驟s42:將數據集中的所有對象標記為未讀;
20、步驟s43:從數據集f中隨機選擇一個未讀對象p;
21、步驟s44:檢查未讀對象p是否為核心對象:
22、若未讀對象p為核心對象,則搜索所有密度可達的對象并標記為已讀;
23、其中,所述密度可達的對象是指位于核心對象的ε半徑內的可達對象;
24、步驟s45:重復步驟s43和步驟s44,直至所有數據集f中對象均被標記為已讀;
25、步驟s46:選擇一個核心對象作為種子,將其所有密度可達點的對象歸為一類;
26、步驟s47:選擇另一個未歸類的核心對象作為種子,將其所有密度可達點的對象歸為另一類;
27、步驟s48:重復步驟s47,循環至沒有未歸類的核心對象,從而得到多個礦工聚類簇。
28、進一步地,所述步驟s5,具體包括如下步驟:
29、步驟s51:獲取同一礦工聚類簇中兩名礦工的生命特征時間序列數據;
30、所述兩名礦工的生命特征時間序列數據的數學表示式如式(1):
31、
32、式(1)中,x表示兩名礦工中的第一礦工,y表示兩名礦工中的第二礦工,zsx表示第一礦工的生命特征時間序列數據,zsy表示第二礦工的生命特征時間序列數據,e表示zsx的數據長度,f表示zsy的數據長度,α∈[1,e],β∈[1,f];
33、表示第一礦工在第α時間序列的生命特征歸一化值,即xα元素的生命特征歸一化值;
34、表示第二礦工在第β時間序列的生命特征歸一化值,即yβ元素的生命特征歸一化值;
35、步驟s52:計算生命特征時間序列數據中的xα元素與yβ元素之間的距離;
36、所述xα元素與yβ元素之間的距離是采用歐式距離度量的,其計算公式如式(2):
37、
38、步驟s53:根據所述xα元素與yβ元素之間的距離,構建規整距離矩陣;
39、所述規整距離矩陣的表達式如式(3):
40、
41、式(3)中,dexf為規整距離矩陣;
42、步驟s54:根據所述規整距離矩陣,計算初始最小規整距離;
43、所述初始最小規整距離wd的計算公式如式(4):
44、wd=w1+w2+…+wk??????(4);
45、式(4)中,k∈[max(e,f),e+f-1],wk為第xα元素和第yβ元素之間的累積規整距離;
46、步驟s55:設定約束條件,確定最短動態規整路徑;以及,根據所述最短動態規整路徑,從所述初始最小規整距離wd中確定出目標最小規整距離,即得到最小規整距離w;
47、所述最短動態規整路徑的表達式如式(5):
48、
49、其中,dtw(zsx,zsy)表示zsx和zsy之間的最短動態規整路徑;
50、步驟s56:根據所述最小規整距離w,計算兩個礦工之間的人員生命體征相似度,其計算公式如式(6):
51、similarity=1/(1+w)???(6);
52、其中,similarity表示兩個礦工之間的人員生命體征相似度;
53、步驟s57:重復步驟s51至步驟s56,直到同一礦工聚類簇中任意兩名礦工的生命特征時間序列數據之間的相似度都已被計算完畢,從而得到任兩個礦工之間的人員生命體征相似度。
54、進一步地,所述步驟s51中的生命特征時間序列數據,是根據生命特征數據按時間順序排列而形成的;
55、所述生命特征數據,是根據體溫數據、心率數據、血氧數據得到的,具體包括如下步驟:
56、步驟s511:分別獲取體溫數據、心率數據和血氧數據;
57、步驟s512:分別將所述體溫數據、所述心率數據和所述血氧數據進行預處理和標準化,得到標準化的體溫數據、標準化的心率數據和標準化的血氧數據;
58、步驟s513:將所述標準化的體溫數據、所述標準化的心率數據和所述標準化的血氧數據進行組合,形成生命特征矩陣,以得到生命特征數據。
59、進一步地,所述下井異常數據包括代打卡異常數據;
60、所述步驟s6中,根據所述人員生命體征之間的相似度,識別出下井異常數據,具體包括如下步驟:
61、步驟s61:根據相似度閾值,判斷兩個礦工之間的人員生命體征相似度是否存在高度一致:
62、若任意兩名礦工的人員生命特征相似度超過預設的相似度閾值,則判定這兩名礦工的人員生命特征為高度一致;
63、其中,所述相似度閾值是根據歷史數據或業務需求預先設定的;
64、步驟s62:基于礦工的打卡記錄,當判定兩名礦工的人員生命特征高度一致,則判定存在代打卡異常行為,從而識別出下井的異常數據。
65、第二方面,本發明提供一種基于動態時間規整的下井異常識別裝置,所述裝置包括:
66、獲取單元,用于獲取礦工下井的監測數據;
67、提取單元,與所述獲取單元連接,用于從監測數據中提取人員步數和人員生命體征數據;
68、聚類單元,與所述提取單元連接,用于根據所述人員步數對礦工進行聚類,得到多個礦工聚類簇;
69、規整單元,與所述聚類單元連接,用于基于同一礦工聚類簇,根據動態時間規整得到任兩個礦工之間的人員生命體征相似度;
70、識別單元,與所述規整單元連接,用于根據所述人員生命體征相似度,識別出下井異常數據,從而完成基于動態時間規整的下井異常識別。
71、進一步地,所述規整單元包括:
72、獲取模塊,用于獲取同一礦工聚類簇中兩名礦工的生命特征時間序列數據;
73、所述兩名礦工的生命特征時間序列數據的數學表示式如下式:
74、
75、式中,x表示兩名礦工中的第一礦工,y表示兩名礦工中的第二礦工,zsx表示第一礦工的生命特征時間序列數據,zsy表示第二礦工的生命特征時間序列數據,e表示zsx的數據長度,f表示zsy的數據長度,α∈[1,e],β∈[1,f];
76、表示第一礦工在第α時間序列的生命特征歸一化值,即xα元素的生命特征歸一化值;
77、表示第二礦工在第β時間序列的生命特征歸一化值,即yβ元素的生命特征歸一化值;
78、第一計算模塊,與所述獲取單元連接,用于計算生命特征時間序列數據中的xα元素與yβ元素之間的距離;
79、所述xα元素與yβ元素之間的距離是采用歐式距離度量的,其計算公式如下式:
80、
81、構建模塊,與所述第一計算連接,用于根據所述xα元素與yβ元素之間的距離,構建規整距離矩陣;
82、所述規整距離矩陣的表達式如下式:
83、
84、式中,dexf為規整距離矩陣;
85、第二計算模塊,與所述構建模塊連接,用于根據所述規整距離矩陣,計算初始最小規整距離;
86、所述初始最小規整距離wd的計算公式如下式:
87、wd=w1+w2+…+wk;
88、式中,k∈[max(e,f),e+f-1],wk為第xα元素和第yβ元素之間的累積規整距離;
89、處理模塊,與所述第二計算模塊連接,用于設定約束條件,確定最短動態規整路徑;以及,根據所述最短動態規整路徑,從所述初始最小規整距離wd中確定出目標最小規整距離,即得到最小規整距離w;
90、所述最短動態規整路徑的表達式如下式:
91、
92、其中,dtw(zsx,zsy)表示zsx和zsy之間的最短動態規整路徑;
93、第三計算模塊,與所述處理模塊連接,用于根據所述最小規整距離w,計算兩個礦工之間的人員生命體征相似度,其計算公式如下式:
94、similarity=1/(1+w);
95、其中,similarity表示兩個礦工之間的人員生命體征相似度;
96、第一判定模塊,與所述第三計算模塊連接,用于判斷同一礦工聚類簇中任意兩名礦工的生命特征時間序列數據之間的相似度是否都已被計算完畢;
97、其中,所述獲取模塊與所述第一判定模塊連接,用于在所述第一判定模塊判定出同一礦工聚類簇中任意兩名礦工的生命特征時間序列數據之間的相似度不都已被計算完畢時,重新獲取同一礦工聚類簇中另外兩名礦工的生命特征時間序列數據。
98、進一步地,所述獲取模塊包括:
99、第一獲取子模塊,用于獲取體溫數據;
100、第二獲取子模塊,用于獲取心率數據;
101、第三獲取子模塊,用于獲取血氧數據;
102、處理子模塊,與所述第一獲取子模塊、所述第二獲取子模塊、及所述第三獲取子模塊分別連接,用于分別將所述體溫數據、所述心率數據和所述血氧數據進行預處理和標準化,得到標準化的體溫數據、標準化的心率數據和標準化的血氧數據;
103、組合子模塊,與所述處理子模塊連接,用于將所述標準化的體溫數據、所述標準化的心率數據和所述標準化的血氧數據進行組合,形成生命特征矩陣,以得到生命特征數據。
104、進一步地,所述識別單元包括:
105、第二判定模塊,用于根據相似度閾值,判斷兩個礦工之間的人員生命體征相似度是否存在高度一致;
106、其中,若任意兩名礦工的人員生命特征相似度超過預設的相似度閾值,則所述第二判定模塊判定這兩名礦工的人員生命特征為高度一致;所述相似度閾值是根據歷史數據或業務需求預先設定的;
107、第三判定模塊,與所述第二判定模塊連接,用于在所述第二判定模塊判定兩名礦工的人員生命特征存在高度一致性時,判斷是否存在代打卡異常行為;
108、其中,在礦工的打卡記錄中,如果存在礦工的人員生命特征高度一致,則所述第三判定模塊判定存在代打卡異常行為;
109、識別模塊,與所述第三判定模塊連接,用于在所述第三判定模塊判定為代打卡異常行為時,識別出下井的異常數據。
110、本發明能夠全面而有效地識別井下的異常情況,顯著提高了異常識別的準確性,從而為下井安全提供更為可靠的保障。具體的有益效果如下:
111、1.高準確率:本發明采用動態時間規整(dtw)技術,使得對時間序列數據的比較更加精確,有效降低了由于環境變化或信號噪聲導致的識別誤差。
112、2.實時監測:本發明能夠實時分析礦工的生命特征和行為模式,及時發現異常情況,顯著縮短了響應時間,提升了應急處理能力。
113、3.全面數據整合:本發明能夠整合多種數據源,包括打卡記錄、生命特征數據和環境參數等,以全面評估下井安全,提供更豐富的信息支持。
114、4.適應性強:本發明對不同類型的異常具有良好的適應性,能夠根據實時數據進行動態調整,提高了系統對新情況和突發事件的應對能力。
115、5.安全預警機制:本發明通過對異常情況的識別和分析,能夠提前發出安全預警,預防事故發生。
- 還沒有人留言評論。精彩留言會獲得點贊!