強化學習驅動的不均衡數據分類任務優化方法
本發明屬于圖像分類處理領域,主要涉及一種強化學習驅動的不均衡數據分類任務優化方法。
背景技術:
1、深度學習是一種先進的機器學習技術,基于復雜的多層神經網絡架構,這使得它特別適合于處理復雜的模式識別和數據映射問題。在眾多領域,尤其是計算機視覺和自然語言處理領域,深度學習技術已經展示了其強大的能力,其性能在某些任務中甚至可與人類相媲美。隨著技術的不斷進步,基于深度學習的應用得到了快速發展,并在多個領域中實現了創新。但是,深度學習是一種數據驅動型算法,其性能很大程度依賴于訓練數據集的優劣,這限制了深度學習在實際中訓練數據質量較差應用中的性能。在現實世界的機器學習應用中,我們常遇到數據分布不均衡的問題,特別是在分類任務中。數據不均衡意味著數據集中某些類別的樣本遠多于其他類別,這種不平衡的數據分布會導致分類模型偏向多數類,從而忽略或錯誤分類少數類,影響整體的分類性能。
2、為了解決這一問題,研究者們開發了多種方法來優化不均衡數據集的分類任務訓練。目前的主流方法之一是通過直接修改數據集的結構來平衡數據集中的類別分布,最常見的策略包括過采樣和欠采樣。
3、過采樣技術如smote通過在少數類樣本的特征空間中合成新樣本來增加其數量,這有助于豐富特征表達并增強模型的泛化能力。然而,當少數類樣本本身較少或分布復雜時,合成的樣本可能不完全準確反映真實分布,引入噪聲,影響訓練效果。另一方面,欠采樣通過隨機減少多數類樣本來平衡數據集,但這種方法可能導致丟失關鍵信息,尤其是那些對分類決策至關重要的樣本,進而可能削弱模型對多數類關鍵特征的捕捉能力,降低整體準確性和可靠性。
技術實現思路
1、為了克服現有技術的不足,當少數類樣本本身較少或分布復雜時,合成的樣本可能不完全準確反映真實分布以及關鍵信息丟失的問題,本發明提供強化學習驅動的不均衡數據分類任務優化方法。
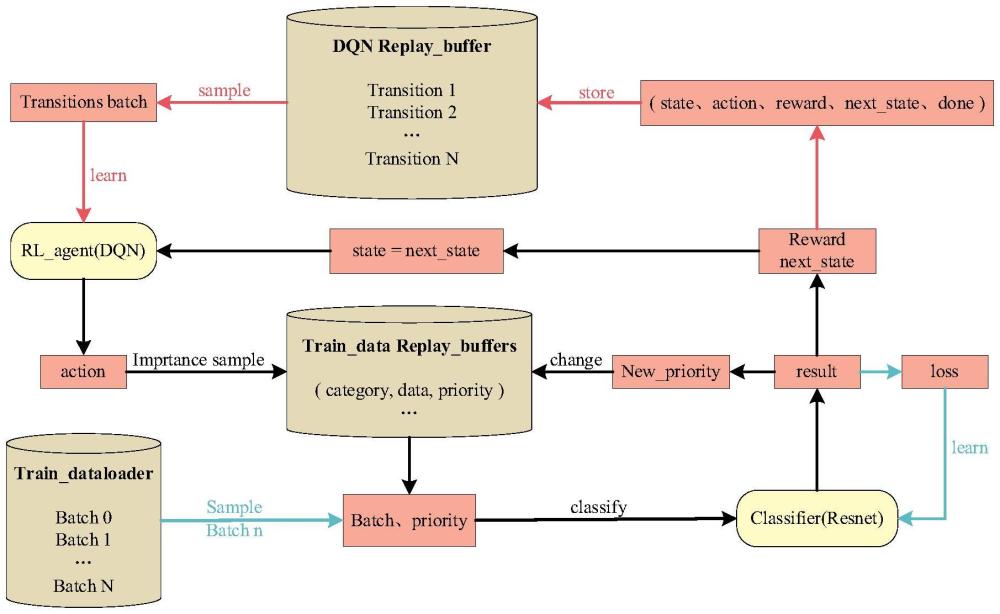
2、一種強化學習驅動的不均衡數據分類任務優化方法包括如下步驟:
3、步驟s1:初始化數據集,構建分類器模型,并初始化分類器模型參數,構建并初始化強化學習模型;
4、步驟s2:訓練強化學習模型;
5、對強化學習模型進行訓練;根據強化學習模型的狀態,計算每個可能采取動作的價值估計的q值,并根據q值和ε-貪婪策略選擇動作執行;根據動作在對應的數據集合中按照樣本的優先級進行重要性采樣,并將得到的批次數據送入分類器模型進行預測,根據預測結果計算獎勵;將學習到的經驗存入強化學習模型的經驗回放池,強化學習模型從經驗回放池中采樣經驗進行學習,并更新強化學習模型參數;
6、步驟s3:更新分類器模型;
7、對分類器模型進行更新;強化學習模型根據狀態采取動作,并根據各樣本的優先級參數進行重要性采樣,得到重要性采樣批次數據;同時,從訓練數據中隨機采樣得到隨機采樣批次數據,將兩者組合為訓練批次數據;將訓練批次數據輸入分類器模型進行學習,更新分類器模型的參數,并根據預測結果更新訓練批次中數據的優先級;訓練完成后,獲得的分類器模型即為最終的結果,應用該分類器模型具有最優的分類準確率。
8、更進一步的,所述步驟s1初始化數據集、構建分類器并初始化分類器模型參數、構建并初始化強化學習模型詳細步驟為:
9、步驟s1-1:對數據集初始化;
10、首先對數據集進行預處理;
11、預處理的方法為調整數據集中所有樣本的尺寸統一為c×w×h,其中c是通道數,w是寬度,h是高度,確保輸入數據的一致性;
12、將預處理后的數據集按功能劃分為訓練集{data}train、驗證集{data}validation和測試集{data}test;
13、對訓練集{data}train中的樣本按照不同的標簽l={l1,l2,...,li,...,ln}進行聚類,得到n個集合{s1,s2,...,si,...,sn},每個集合si包含訓練集中所有標簽為li的樣本;n為標簽總數;
14、為訓練集中的每個樣本e的優先級參數p(e)賦予初始值p0;初始優先級是后續的訓練過程中強化學習模型選擇樣本的依據,此步驟確保數據在接下來的訓練中能夠被正確和高效地利用;
15、步驟s1-2:構建分類器并初始化模型參數;
16、所述分類器包括初始卷積層、殘差網絡層和輸出層;
17、所述初始卷積層結構為:初始卷積層的輸入通道數為3,初始卷積層的輸出通道數為64,卷積核尺寸為3x3,步長為1,填充為1;所述初始卷積層的輸入為原始圖像數據,對輸入的樣本進行初步的特征提取,輸出為初步提取特征后的特征圖;初始卷積層用于進行做出的圖像特征提取;
18、所述殘差網絡層包括基本單元殘差塊res-block;所述基本單元殘差塊res-block包括第一層序列、第二層序列、第三層序列、第四層序列;每個層序列包含兩個殘差塊;
19、所述基本單元殘差塊res-block包括conv1、bn1、relu、conv2和bn2層;
20、conv1層和conv2層具有相同的結構,conv1層和conv2層的尺寸均為3x3,步長均為1,填充均為1,通道數均為64;bn1層和bn2層的填充均為0,通道數均為64;relu的通道數為64;
21、所述殘差塊的尺寸為1x1,步長為1,填充為零,通道數為64;
22、所述第一層序列的通道數是64;第二層序列的通道數為128;、第三層序列的通道數256;第四層序列的通道數為512;
23、所述殘差網絡層的輸入為初始卷積層輸出的特征圖;在這一層組中,特征圖通過一系列殘差塊進行處理,每個塊都進一步深化特征提取;殘差網絡層的輸出為經過復雜特征提取和優化的特征圖;
24、所述輸出層的輸入為殘差網絡層輸出的特征圖,輸出層對殘差網絡層輸出的特征圖依次進行平均池化、展平、全連接層映射操作,輸出層的輸出是維度為n的分類預測結果;
25、所述分類器的輸入為在訓練集中依據樣本的優先級參數p(e)采樣得到的批次樣本{b1,b2,…,bi,…,bk},bi表示樣本,k表示一個批次中樣本的數量;每個樣本的尺寸為c×w×h;
26、依據樣本的優先級參數進行采樣稱為重要性采樣,樣本被采樣的概率計算如下:
27、
28、其中,p(e)是樣本e對應的優先級,α是優先級權重調節因子;
29、所述分類器的輸出為預測的樣本標簽所屬的類別預測的樣本標簽所屬的類別數量與訓練集的分類標簽的數量相同;此步驟保證了分類器能夠適應不同類型的數據集,并正確地輸出每個實例的類別預測。
30、更進一步的,所述數據集采用cifar-10;n=10。
31、更進一步的,所述步驟s2訓練強化學習模型的步驟為:
32、步驟2-1:初始化強化學習模型狀態s;
33、狀態s為集合{s1,s2,...,si,...,sn},被選取的次數集合;集合si是存放分類器數據訓練的集合;集合si為{x1,x2,…,xi,…,xn}中xi被選取的次數;
34、在回合eposide開始時,令s={0,0,0,……,0}來表示每個回合的初始狀態,并初始化行動步數n=0;
35、步驟2-2:強化學習模型rl_agent行動選擇;
36、強化學習模型接收狀態s,并計算每個可能動作的價值估計q值;基于價值估計q值,強化學習模型選擇動作ai來執行;
37、強化學習模型rl_agent行動選擇的具體步驟為將表示狀態s的向量輸入強化學習模型,輸出每個動作對應的價值{q1,q2,...qi…,qn},強化學習模型采用ε-貪婪策略進行動作選擇,ε是一個介于0到1之間的參數,控制探索與利用平衡,即:以1-ε的概率選擇ai=argmaxaqi;以ε的概率隨機選擇動作,最終得到強化學習模型的輸出動作ai;每個輸出動作ai對應集合si;
38、步驟2-3:根據強化學習模型的輸出動作ai,在對應的集合si中按照各個樣本的優先級參數p(e)進行重要性采樣,生成批次數據{b1,b2,…,bi,…,bk};
39、每一個樣本被采樣的概率計算如下:
40、
41、p(e)是樣本e對應的優先級,α是優先級權重調節因子,si是對應的集合;
42、步驟2-4:將采樣得到的批次樣本{b1,b2,…,bi,…,bk}輸入分類器進行預測,根據預測結果計算獎勵r,并更新批次中數據的優先級p(e);
43、獎勵r公式如下:
44、
45、β是縮放因子,k是批次中樣本總數,c是分類的正確樣本數;
46、根據預測結果更新樣本優先級,計算公式如下:
47、p(e)=|δ(e)|+∈
48、|δ(e)|是樣本e預測與實際標簽的誤差,∈為小于0.001的正數;
49、步驟2-5:計算強化學習模型的下一狀態s′,并判斷回合eposide是否結束,若回合已結束,則done=true,若回合未結束,則將done=false;將狀態s、動作ai、獎勵r、下一狀態s′、回合是否結束done組合為經驗轉換為(s,ai,r,s′,done),將(s,ai,r,s′,done)存入強化學習模型的經驗回放池;
50、步驟2-6:強化學習模型在經驗回放池中采樣經驗進行學習并更新參數;
51、強化學習模型從經驗回放池中隨機抽取批量的經驗轉換{(si,ai,ri,s′i,donei)}進行學習更新,(si,ai,ri,s′i,donei)代表其中的一條經驗轉換,使用時間差分td算法對強化學習模型參數進行更新。
52、首先計算強化學習模型預測值q(si,ai;θ)是當強化學習模型參數為θ時,對于在給定狀態si和動作ai的價值估計;
53、然后計算td目標ri是獎勵值,γ是折扣因子,取值在0到1之間,maxq(s′i,a;θ)表示當強化學習模型參數為θ時,對下一狀態s′i采取所有可能動作的最大價值估計;之后計算td誤差最后用下式更新強化學習模型的參數θ:
54、
55、其中α是學習率,是在狀態si和動作ai的價值估計關于θ的梯度;
56、步驟2-7:強化學習模型狀態轉移s←s′;
57、當前狀態為s={x1,x2,…,xi,…,xn},下一狀態為s′={x1,x2,…,xi+1,…,xn},將強化學習模型從當前狀態轉移至下一狀態s=s′;
58、若回合未結束,則返回步驟2-2;若回合結束但回合數eposide未達到設定最大回合數t,則回合數eposide增加1并回到步驟2-1開始新的回合;若回合結束且回合數eposide達到設定最大回合數t,進入步驟s3;
59、更進一步的,所述步驟s3更新分類器模型的步驟為:
60、步驟s3-1:初始化環境與狀態s;
61、步驟s3-2:強化學習模型根據當前狀態s采取行動ai;
62、步驟s3-3:根據強化學習模型的輸出動作ai,在對應的集合si中按照各個樣本的優先級參數進行重要性采樣,得到重要性采樣批次數據{b1,b2,…,bi,…,bk};
63、步驟s3-4:在訓練數據中進行隨機采樣,得到隨機采樣批次數據{c1,c2,…,ci,…,cm},m為隨機采樣批次數據樣本個數,將其與重要性采樣批次數據{b1,b2,…,bi,…,bk}組合,得到訓練批次數據{c1,c2,…,ci,…,cm,b1,b2,…,bi,…,bk};
64、步驟3-5:將訓練批次數據輸入分類器進行學習,更新分類器模型參數,并根據預測結果更新批次中數據的優先級;
65、將訓練批次數據輸入分類器,得到預測用交叉熵損失函數來計算預測與標簽y的損失使用隨機梯度下降sgd更新分類器網絡權重η是學習率,控制網絡權重調整的步長;是損失函數關于權重ω的梯度;根據預測結果更新數據的優先級p(e);
66、步驟3-6:計算下一狀態s′,并判斷回合是否結束;
67、計算強化學習模型下一狀態s′={x1,x2,…,xi+1,…,xn},回合行動步數增加1,并判斷是否已到達設定的回合總步數m,若達到m,則代表回合結束;若未達到m,則代表回合未結束;
68、步驟s3-7:強化學習模型狀態轉移s←s′;
69、當前狀態為s,s={x1,x2,…,xi,…,xn},下一狀態為s′,s′={x1,x2,…,xi+1,…,xn},將強化學習模型從當前狀態轉移至下一狀態;
70、若回合已結束,則分類器模型更新階段結束,若回合未結束,則回到步驟3-2;
71、判斷訓練輪次epoch是否達到最大訓練輪次k,如未達到最大訓練輪次k,則epoch增加1,并返回強化學習訓練階段s2,反之則訓練結束;
72、執行強化學習模型訓練階段和分類器模型更新階段各一次記為1個訓練輪次epoch,循環執行k個訓練輪次后訓練結束。
73、更進一步的,強化學習模型基于dqn算法或q-learning或a2c算法進行構建。
74、更進一步的,所述分類器為resnet-18。
75、本發明提出了一種融合強化學習模型的分類器訓練框架,通過引入強化學習智能體,并設計特定的對抗場景,通過強化學習智能體在分類器訓練過程中智能化調整樣本的選擇和利用率,優化模型的訓練過程,顯著提高了分類器對不均衡數據的適應性和處理效果。相較于過去的不均衡分類數據集處理算法,本發明所提出的算法在不均衡cifar-10數據集中具有更優秀的分類精度,與smote相比,總體分類精度提升了2.03%,樣本稀缺類(第3類、第7類)分類精度分別提升了8.3%和7.9%;與欠采樣方法相比,總體分類精度提升了5.56%,樣本稀缺類(第3類、第7類)分類精度分別提升了11.3%和13.6%。
- 還沒有人留言評論。精彩留言會獲得點贊!