一種基于博弈模型的AI人機協同決策優化方法及其系統與流程
本發明涉及人工智能,尤其涉及一種基于博弈模型的ai人機協同決策優化方法及其系統。
背景技術:
1、隨著人工智能技術的快速發展,ai與人類協同決策的應用場景日益增多。在金融風控、醫療診斷、智能制造、智慧城市等領域,ai系統需要與人類專家進行持續互動,共同完成復雜的決策任務。這種協同決策模式既可以發揮ai系統高效處理數據、快速推理的優勢,又能結合人類專家的經驗判斷和創造性思維,實現優勢互補。
2、目前,人機協同決策系統主要采用監督學習、深度強化學習、多智能體學習等方法構建ai決策模型,結合人類反饋和專家知識來優化模型性能。一些系統還引入了主動學習和在線學習機制,以適應動態變化的決策環境。這些方法在實際應用中展現出良好的潛力,但仍面臨諸多挑戰。
3、然而,現有技術仍存在以下突出問題:
4、首先,大多數系統僅關注ai模型的決策性能,忽視了人類干預成本,存在效用評估單一的問題。系統往往過度依賴人工干預來提升決策準確性,導致人類專家疲勞度上升,協作效率低下。特別是在需要快速響應的場景中,頻繁的人工干預會顯著延長決策時間,影響系統的實際應用效果。
5、其次,現有的訓練方法普遍缺乏有效的穩定性保障機制。在長期訓練過程中,模型性能容易出現波動或退化,特別是在處理復雜多變的決策任務時,訓練的不穩定性問題更為突出。雖然一些方法采用了簡單的檢查點保存機制,但缺乏系統的策略評估和回退方案。
6、第三,針對新任務類型的適應能力不足。現有系統大多采用固定的模型結構和訓練方式,當面對新的任務類型時,需要重新進行大量訓練才能適應,無法滿足實際應用中快速響應新場景的需求。缺乏對任務相似性的有效建模和快速適應機制,嚴重限制了系統的泛化能力。
7、這些技術問題嚴重制約了ai人機協同決策系統的實際應用效果。在實踐中,決策效率與人工成本的權衡、訓練穩定性保障、新任務快速適應等問題亟待解決。因此,迫切需要一種能夠平衡ai決策效率與人類干預成本、保證訓練穩定性、具備快速任務適應能力,同時具有良好實用性的人機協同決策優化方法。
技術實現思路
1、為了解決上述技術問題,本發明提出一種基于博弈模型的ai人機協同決策優化方法及其系統,通過設計雙效用函數平衡ai決策效率與人類干預成本,引入動態適應機制提升模型泛化能力,采用策略回退機制保證訓練穩定性,實現高效的人機協同決策。
2、本發明所采取的技術方案如下:
3、一種基于博弈模型的ai人機協同決策優化方法,包括以下步驟:
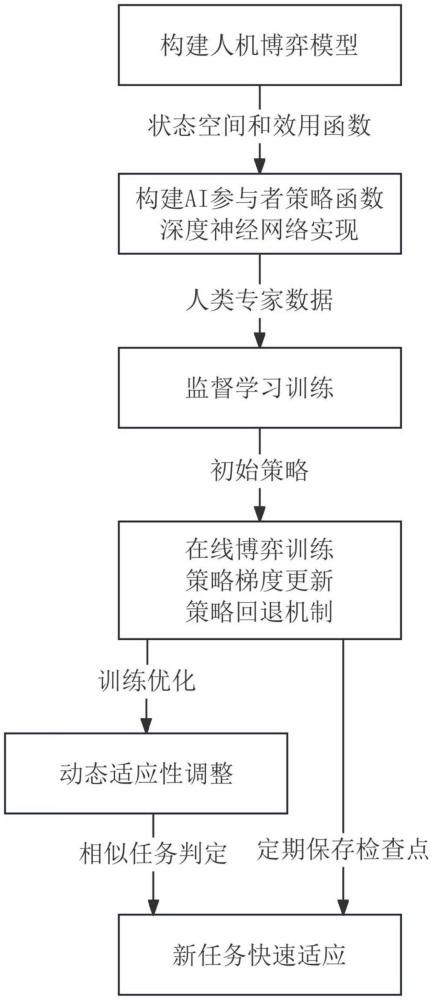
4、構建人機博弈模型,所述人機博弈模型包括ai參與者和人類參與者,將任務狀態和歷史交互記錄構建為狀態空間,其中所述任務狀態t包含任務的輸入特征信息和類型語義信息,定義所述ai參與者的行動空間和所述人類參與者的行動空間,并構建雙方效用函數和聯合效用函數,用于實現所述ai參與者與所述人類參與者的協同決策;
5、采用深度神經網絡實現所述ai參與者的策略函數,基于人類專家的歷史決策數據通過監督學習方式訓練所述策略函數,將所述狀態空間映射為所述ai參與者行動空間中的行為概率分布,并通過驗證評估確保所述策略函數具備可靠的決策能力,用于構建所述ai參與者的初始策略;
6、執行在線博弈訓練,所述在線博弈訓練包括采用溫度參數調節所述策略函數對應的神經網絡輸出的概率分布并進行決策行為采樣,記錄包含狀態、行為和基于所述ai參與者效用函數計算的效用值的交互數據,構建價值評估網絡并采用策略梯度方法更新所述神經網絡的參數,通過訓練過程監控和策略回退機制保證訓練穩定性,用于優化所述ai參與者的決策效果;
7、基于所述任務狀態t中的類型語義信息進行相似任務判定,對所述策略網絡進行動態適應性調整,包括保存檢查點數據和執行快速適應訓練,其中所述檢查點數據包含所述任務類型標識、所述聯合效用函數計算的效用值和所述策略網絡的參數,用于提升所述ai參與者在新任務場景下的適應能力。
8、進一步地,所述人機博弈模型按如下方式構建:
9、所述狀態空間采用二元組s=(t,h)表示,其中,任務狀態t包含數字形式的輸入特征向量、任務類型的語義嵌入向量、歸一化的任務完成進度值和歸一化的時間限制值,歷史交互記錄h包含離散化的決策時間戳序列、決策主體的二值標識序列和決策內容的向量序列;
10、所述ai參與者的行動空間a1包含m維決策動作向量、取值為{0,1}的執行動作標識和取值為{0,1}的確認請求標識,所述人類參與者的行動空間a2包含取值為{0,1,2,3}的響應動作標識,分別對應接受建議、修改建議、直接決策和終止任務;
11、所述ai參與者的效用函數為:
12、
13、其中,c為任務完成標識,當任務用時不超過最大時間限制tmax時取值為1,否則取值為0,p為任務目標達成度得分,計算方式為任務目標達成數除以總任務目標數,其取值范圍為[0,1],t為所述ai參與者的決策用時,所述最大時間限制tmax用于限定任務完成的最長時間,所有變量均采用最大最小值方法進行歸一化處理,使其取值范圍限定在[0,1]區間內;
14、所述人類參與者的效用函數為:
15、
16、其中,n為所述人類參與者的干預次數,nmax為預設的最大干預次數,所有變量均采用最大最小值方法進行歸一化處理,使其取值范圍限定在[0,1]區間內;所述聯合效用函數:
17、u=min(u1,u2)
18、作為所述策略網絡訓練的優化目標,以實現所述ai參與者和所述人類參與者的效用均衡提升。
19、進一步地,所述深度神經網絡和監督學習過程按如下方式實現:
20、所述深度神經網絡包括三層全連接層,接收經過處理的狀態空間輸入,其中任務狀態t保持完整輸入歷史交互記錄h僅保留所述決策主體的二值標識序列中標識為人類參與者的對應時刻的所述決策時間戳序列和決策內容序列,每層神經元數量根據所述狀態空間s的維度和所述ai參與者行動空間a1的維度按照預設的收縮比例逐層遞減設置,每層采用relu激活函數實現非線性變換,最后一層采用softmax函數將輸出映射為概率分布,用于表征ai參與者在行動空間a1中不同決策行為的選擇概率;
21、從所述人類參與者的歷史決策數據中提取專家決策數據,其中專家決策數據的篩選滿足任務完成時間小于預設時間閾值、決策結果滿足質量評估標準、且具有較高的歷史決策成功率,將滿足條件的決策數據構建為數據集d={(t,h,a)},其中,a為與所述人類參與者行動空間a2對應的專家決策行為標識;
22、將所述專家決策數據按照預設比例劃分為訓練集和驗證集,其中訓練集用于所述策略函數的參數優化,驗證集用于評估所述策略函數的泛化性能;
23、采用交叉熵損失函數優化所述策略函數的參數,并在所述驗證集上評估決策準確性,當準確率達到預設閾值時停止訓練,使所述ai參與者習得人類專家的決策模式,為后續的在線博弈訓練提供良好的初始策略。
24、進一步地,所述在線博弈訓練按如下方式執行:
25、采用基于訓練輪次動態調整的溫度參數τ調節所述策略網絡的輸出概率分布,其中溫度參數隨訓練輪次增加而遞減,并基于調節后的概率分布進行決策行為采樣,用于平衡策略探索與利用;
26、收集交互數據(st,at,rt),其中,st為所述狀態空間在t時刻的狀態表示,at為所述ai參與者基于所述策略網絡采樣得到的決策行為,rt為基于所述ai參與者效用函數u1計算的效用值;
27、構建與所述策略網絡具有相同輸入層結構的價值網絡v(s),所述價值網絡采用三層全連接結構,最后一層輸出單一數值以對狀態價值進行評估,基于如下策略梯度公式更新所述策略網絡的參數θ:
28、
29、其中,α為用于控制參數更新步長的學習率,γ為用于平衡即時效用與長期效用的折扣因子;
30、計算并記錄訓練過程中的平均效用值,其中平均效用值包括基于所述ai參與者效用函數計算的單步效用均值和基于所述聯合效用函數計算的協同效用均值,當連續多輪訓練后新策略的所述單步效用均值持續低于所述平均效用值的預設比例閾值時執行策略回退,所述策略回退包括加載具有最高所述協同效用均值的歷史參數、重置所述溫度參數、減小所述學習率,并保持所述收縮比例不變以維持網絡結構穩定性,用于保證訓練的穩定性和效用的持續提升,最終獲得優化后的所述策略網絡參數;
31、將所述優化后的策略網絡參數作為檢查點數據定期保存,用于所述動態適應性調整,同時將所述優化后的策略網絡參數應用于實際的人機協同決策過程中,基于輸入的狀態信息輸出決策建議供所述人類參與者參考。
32、進一步地,所述動態適應性調整按如下方式實現:
33、將所述任務狀態t中的任務類型的語義嵌入向量通過余弦相似度計算進行相似任務判定,用于識別與當前任務相近的歷史任務,當存在相似度高于預設閾值的歷史任務時選取相似度最高的檢查點進行參數加載,反之則保持所述策略網絡當前參數;
34、按照預設的時間間隔保存所述檢查點數據,所述檢查點數據包含所述任務類型的語義嵌入向量、基于所述聯合效用函數計算的效用值和所述策略網絡的參數;所述快速適應訓練包括計算當前任務與所述檢查點數據中歷史任務的相似度,選取相似度最高的歷史檢查點進行參數加載,收集所述交互數據(st,at,rt)對所述策略網絡進行訓練,其中訓練輪次與所述任務相似度呈反比,用于在保持所述策略網絡穩定性的同時實現快速適應。
35、本發明還公開了一種基于博弈模型的ai人機協同決策優化系統,包括:訓練數據管理單元,用于存儲和管理所述人類專家的歷史決策數據和所述在線博弈訓練過程中的交互數據;
36、策略網絡單元,用于構建所述深度神經網絡,基于輸入的狀態信息通過所述策略函數輸出決策建議;
37、訓練執行單元,用于實現所述監督學習訓練和所述在線博弈訓練,執行所述策略網絡的參數優化;
38、效用評估單元,用于計算所述ai參與者效用函數和所述聯合效用函數的效用值,并基于效用評估結果指導所述訓練執行單元的優化過程;
39、任務適應單元,用于執行所述相似任務判定和所述快速適應訓練,實現所述策略網絡對新任務的快速適應;
40、其中,所述訓練數據管理單元向所述訓練執行單元提供訓練數據,所述效用評估單元的評估結果用于指導所述訓練執行單元的參數優化過程,所述任務適應單元基于所述效用評估單元的評估結果選擇最優檢查點進行快速適應訓練。
41、本發明的有益效果如下:
42、(1)通過設計雙效用函數和聯合效用函數,有效平衡了ai決策速度和人類干預成本。其中,ai效用函數考慮了完成時間,人類效用函數考慮了干預次數,通過聯合效用函數實現雙方效用的均衡提升。這種設計使ai系統在追求決策效率的同時會考慮減少對人類的打擾,避免了過度依賴人工干預的問題。
43、(2)采用溫度參數動態調節和策略回退機制,實現了訓練過程的穩定性保障。通過溫度參數動態調節策略網絡輸出的概率分布,并基于效用值設計了完整的策略回退機制,包括加載最優歷史參數、重置溫度參數和調整學習率等。這種機制有效防止了長期訓練中的性能退化問題,確保了模型性能的單調提升。
44、(3)引入基于任務類型相似度的動態適應機制,實現了模型對新任務的快速適應能力。通過計算任務類型的余弦相似度進行相似任務判定,并采用訓練輪次與任務相似度反比的快速適應策略,使模型能夠快速適應新的任務類型,同時保持歷史經驗的穩定性。
- 還沒有人留言評論。精彩留言會獲得點贊!