基于PER-MATD3深度強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)動(dòng)態(tài)博弈模型及其工作方法
本發(fā)明涉及無(wú)人機(jī),特別是涉及一種基于per-matd3深度強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)動(dòng)態(tài)博弈模型及其工作方法。
背景技術(shù):
1、近年來(lái),基于強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)群決策算法研究在國(guó)內(nèi)外均展現(xiàn)出了蓬勃的發(fā)展態(tài)勢(shì),成為提升無(wú)人機(jī)自主決策能力和協(xié)同作戰(zhàn)效率的關(guān)鍵技術(shù)之一。在國(guó)內(nèi),許多研究公司均投入到這一前沿領(lǐng)域的研究中。他們通過(guò)構(gòu)建多智能體系統(tǒng)模型,將單個(gè)無(wú)人機(jī)視為智能體,并應(yīng)用強(qiáng)化學(xué)習(xí)算法解決無(wú)人機(jī)群在復(fù)雜環(huán)境中的序貫決策問(wèn)題。這些研究不僅涵蓋了無(wú)人機(jī)群的任務(wù)規(guī)劃、路徑規(guī)劃、協(xié)同作戰(zhàn)等多個(gè)方面,還提出了多種優(yōu)化算法,如goose、apo、dcs等,以應(yīng)對(duì)無(wú)人機(jī)群在復(fù)雜戰(zhàn)場(chǎng)環(huán)境中面臨的挑戰(zhàn)。通過(guò)這些研究,國(guó)內(nèi)在無(wú)人機(jī)群自主決策與控制方面取得了顯著成果,為無(wú)人機(jī)群的廣泛應(yīng)用奠定了堅(jiān)實(shí)基礎(chǔ)。
2、與此同時(shí),國(guó)外在基于強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)群決策算法研究方面也取得了豐碩成果。美國(guó)空軍科學(xué)顧問(wèn)委員會(huì)等機(jī)構(gòu)將無(wú)人機(jī)群視為未來(lái)無(wú)人機(jī)應(yīng)用的重要趨勢(shì),并在此方向上進(jìn)行了深入探索。歐洲的信息社會(huì)技術(shù)計(jì)劃(ist)也開(kāi)展了類似項(xiàng)目,如comets,旨在通過(guò)實(shí)時(shí)控制技術(shù)提升無(wú)人機(jī)群的協(xié)同作戰(zhàn)能力。國(guó)外研究在分層控制、多目標(biāo)遺傳算法、通信網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)等方面取得了重要進(jìn)展,實(shí)現(xiàn)了無(wú)人機(jī)群在復(fù)雜戰(zhàn)場(chǎng)環(huán)境中的高效協(xié)同作戰(zhàn)。這些研究成果不僅提高了無(wú)人機(jī)群的作戰(zhàn)靈活性和適應(yīng)性,還為無(wú)人機(jī)群的廣泛應(yīng)用提供了有力支持。
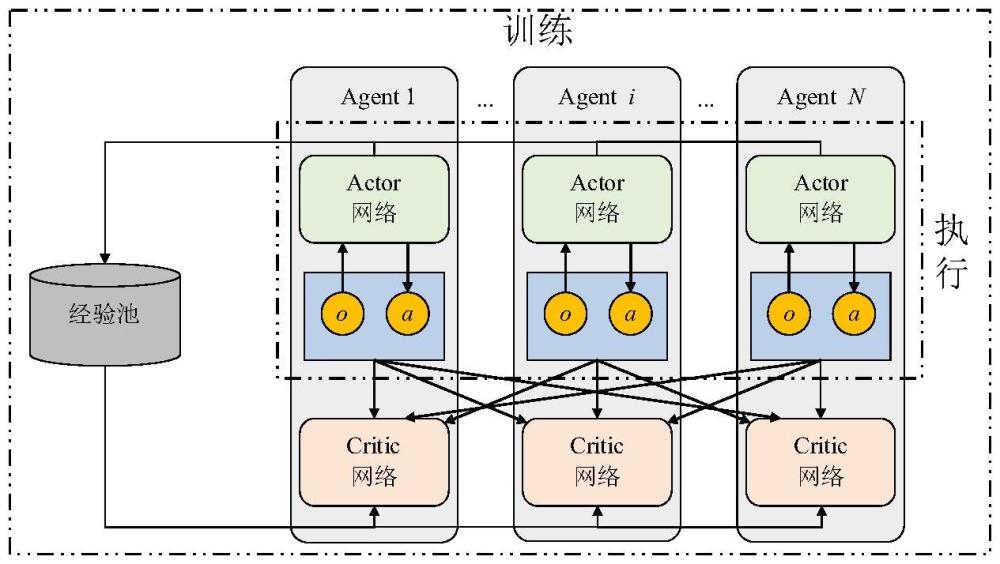
3、matd3是經(jīng)典的深度強(qiáng)化學(xué)習(xí)算法,它將td3算法應(yīng)用到了多智能體領(lǐng)域。matd3算法借鑒多智能體深度確定性策略梯度(multi-智能體deep?deterministic?policygradient,maddpg)集中式訓(xùn)練、分布式執(zhí)行的核心思想,在訓(xùn)練階段,算法可以訪問(wèn)所有智能體的信息,包括智能體的狀態(tài)和動(dòng)作,以便學(xué)習(xí)更加復(fù)雜的策略,但在執(zhí)行階段每個(gè)智能體僅基于自身的觀察和學(xué)習(xí)到的策略,獨(dú)立做出決策。因此,在matd3的訓(xùn)練過(guò)程中,critic不僅需要考慮當(dāng)前智能體的狀態(tài)和動(dòng)作信息,還需要綜合考慮其它智能體的狀態(tài)和動(dòng)作信息,以估計(jì)actor網(wǎng)絡(luò)的動(dòng)作質(zhì)量,并指導(dǎo)actor網(wǎng)絡(luò)產(chǎn)生更好的動(dòng)作。為了解決maddpg中的過(guò)高估計(jì)問(wèn)題,matd3中的critic使用兩個(gè)q網(wǎng)絡(luò)來(lái)估計(jì)動(dòng)作的價(jià)值,對(duì)于每個(gè)步驟的價(jià)值估計(jì),選擇這兩個(gè)q值中的較小者。matd3的算法框架如圖1所示。為了重復(fù)利用歷史經(jīng)驗(yàn)數(shù)據(jù),dqn算法中首先引入了經(jīng)驗(yàn)回放方法,將歷史數(shù)據(jù)存儲(chǔ)在經(jīng)驗(yàn)池中,大大提高了經(jīng)驗(yàn)利用率。然而,隨機(jī)采樣方法忽略了經(jīng)驗(yàn)數(shù)據(jù)的重要性,可能導(dǎo)致采樣的經(jīng)驗(yàn)數(shù)據(jù)質(zhì)量參差不齊,從而降低學(xué)習(xí)效率。
4、為了解決現(xiàn)有技術(shù)中采樣的經(jīng)驗(yàn)數(shù)據(jù)質(zhì)量參差不齊的問(wèn)題,本發(fā)明在matd3深度強(qiáng)化學(xué)習(xí)算法的基礎(chǔ)上,引入per方法,提高學(xué)習(xí)效率。
技術(shù)實(shí)現(xiàn)思路
1、本發(fā)明的目的是針對(duì)現(xiàn)有技術(shù)中存在的技術(shù)缺陷,而提供一種基于per-matd3深度強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)動(dòng)態(tài)博弈模型;
2、本發(fā)明的另一個(gè)目的是提供一種基于per-matd3深度強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)動(dòng)態(tài)博弈模型的工作方法。
3、為實(shí)現(xiàn)本發(fā)明的目的所采用的技術(shù)方案是:
4、一種基于per-matd3深度強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)動(dòng)態(tài)博弈模型,包括matd3算法模塊、per排序模塊以及樣本重要性評(píng)價(jià)模塊:
5、所述matd3算法模塊包括n個(gè)智能體和一個(gè)經(jīng)驗(yàn)池d,所述每個(gè)智能體代表一個(gè)博弈模型中的無(wú)人機(jī),每個(gè)智能體參與critic1網(wǎng)絡(luò)、critic2網(wǎng)絡(luò)和actor網(wǎng)絡(luò)的計(jì)算,其中,critic1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò)由φi1和φi2參數(shù)化,actor網(wǎng)絡(luò)由θ參數(shù)化,actor網(wǎng)絡(luò)獲取第i個(gè)智能體的本時(shí)刻的觀測(cè)o,輸出第i個(gè)智能體的下一時(shí)刻的動(dòng)作a,第i個(gè)智能體的觀測(cè)o和動(dòng)作a與本智能體和其他智能體的critic1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò)交互,每個(gè)智能體參與的actor網(wǎng)絡(luò)將信息傳遞給所述經(jīng)驗(yàn)池d,每個(gè)智能體的critic1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò)從經(jīng)驗(yàn)池d中隨機(jī)獲取k個(gè)樣本;
6、所述經(jīng)驗(yàn)池d包括來(lái)自所有智能體的樣本其中,s1為第一個(gè)樣本當(dāng)前時(shí)刻的狀態(tài),a1為第一個(gè)樣本當(dāng)前時(shí)刻的動(dòng)作,s′1為第一個(gè)樣本下一時(shí)刻的狀態(tài),r1為第一個(gè)樣本的獎(jiǎng)勵(lì),sk為第k個(gè)樣本當(dāng)前時(shí)刻的狀態(tài),ak為第k個(gè)樣本當(dāng)前時(shí)刻的動(dòng)作,s′k為第k個(gè)樣本下一時(shí)刻的狀態(tài),rk為第k個(gè)樣本的獎(jiǎng)勵(lì),stadd為第tadd個(gè)樣本當(dāng)前時(shí)刻的狀態(tài),為第tadd個(gè)樣本當(dāng)前時(shí)刻的動(dòng)作,為第tadd個(gè)樣本下一時(shí)刻的狀態(tài),為第tadd個(gè)樣本的獎(jiǎng)勵(lì),tadd為經(jīng)驗(yàn)池d中的樣本總數(shù);
7、所述per排序模塊根據(jù)每個(gè)樣本的重要性對(duì)k個(gè)樣本進(jìn)行優(yōu)先級(jí)pk排序,具有較大td誤差值的樣本的優(yōu)先級(jí)pk較高,具有較小td誤差值的樣本的優(yōu)先級(jí)pk較低,計(jì)算第k個(gè)樣本的采樣概率
8、所述樣本重要性評(píng)價(jià)模塊計(jì)算第k個(gè)樣本的權(quán)重ωk,以降低td誤差高的樣本權(quán)重,同時(shí)對(duì)權(quán)重ωk進(jìn)行歸一化處理。
9、上述技術(shù)方案中,所述matd3算法模塊中觀測(cè)o包括狀態(tài)s、動(dòng)作a和獎(jiǎng)勵(lì)r,所述狀態(tài)s包括無(wú)人機(jī)位置、偏航角、俯仰角、速度;所述動(dòng)作a包括無(wú)人機(jī)的機(jī)動(dòng)策略,對(duì)應(yīng)博弈模型中純策略的機(jī)動(dòng)動(dòng)作。
10、上述技術(shù)方案中,所述matd3算法模塊中,對(duì)于第i個(gè)智能體,從經(jīng)驗(yàn)池d中隨機(jī)選擇樣本,目標(biāo)動(dòng)作a′i(s′i)如下式所示:
11、
12、式中,a′i(s′i)為第i個(gè)智能體在目標(biāo)狀態(tài)s′i下的目標(biāo)動(dòng)作,μ′為參數(shù)θ′i的目標(biāo)網(wǎng)絡(luò)策略,s′i為第i個(gè)智能體轉(zhuǎn)移后的目標(biāo)狀態(tài),clip為最大可用切向過(guò)載,將目標(biāo)動(dòng)作限制在一定范圍內(nèi)的函數(shù),為滿足正態(tài)分布的隨機(jī)噪聲,訓(xùn)練過(guò)程中方差由初始值逐漸衰減到最小值,c為噪聲邊緣值。
13、上述技術(shù)方案中,所述matd3算法模塊中critic1網(wǎng)絡(luò)的損失函數(shù)l(φi1)如下式如下:
14、
15、所述matd3算法模塊中critic2網(wǎng)絡(luò)的損失函數(shù)如下式所示:
16、
17、式中,和分別為critic1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò)的損失函數(shù),e(·)為數(shù)學(xué)期望,yi為第i個(gè)智能體的目標(biāo)q值,s=(s1,s2,...,sn)和s′=(s′1,s′2,...,s′n)分別為當(dāng)前時(shí)刻和下一時(shí)刻n個(gè)智能體的聯(lián)合狀態(tài);r={r1,r2,...,rn}表示當(dāng)前時(shí)刻n個(gè)智能體的聯(lián)合獎(jiǎng)勵(lì),a=(a1,a2,...,an)和a′=(a′1,a′2,...,a′n)分別為當(dāng)前時(shí)刻和下一時(shí)刻n個(gè)智能體的聯(lián)合動(dòng)作,μ={μ1,μ2,...,μn},μ為參數(shù)為θ={θ1,θ2,...,θn}的n個(gè)智能體的策略集合;和分別為critic1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò),由和參數(shù)化,d為經(jīng)驗(yàn)池,包括來(lái)自所有智能體的樣本k為第i個(gè)智能體在經(jīng)驗(yàn)池中隨機(jī)抽取的樣本數(shù),ωk為第k個(gè)樣本的權(quán)重;
18、所述第i個(gè)智能體的目標(biāo)q值yi的計(jì)算如下式所示:
19、
20、式中,ri為第i個(gè)智能體當(dāng)前時(shí)刻的聯(lián)合獎(jiǎng)勵(lì),ri=r1,r2,...,rn,i=1-n;μ′={μ′1,μ′2,...,μ′n},μ′為參數(shù)θ={θ1,θ2,...,θn}的n個(gè)智能體的目標(biāo)網(wǎng)絡(luò)的聯(lián)合策略;a′=(a′1,a′2,...,a′n)為n個(gè)智能體下一時(shí)刻的聯(lián)合動(dòng)作,s′=(s′1,s′2,...,s′n)為n個(gè)智能體下一時(shí)刻的聯(lián)合狀態(tài),和分別為critic1的目標(biāo)網(wǎng)絡(luò)和critic2的目標(biāo)網(wǎng)絡(luò),由和參數(shù)化,γ為折扣因子。
21、上述技術(shù)方案中,所述matd3算法模塊中critic1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò)的參數(shù)和φi2通過(guò)梯度下降進(jìn)行更新,critic1網(wǎng)絡(luò)的參數(shù)的計(jì)算如下式所示:
22、
23、式中,為critic1網(wǎng)絡(luò)的參數(shù),為critic1網(wǎng)絡(luò)的學(xué)習(xí)率,為critic1網(wǎng)絡(luò)的損失函數(shù)相對(duì)于參數(shù)的梯度;
24、critic2網(wǎng)絡(luò)的參數(shù)計(jì)算如下式所示:
25、
26、式中,為critic2網(wǎng)絡(luò)的參數(shù),為critic2網(wǎng)絡(luò)的學(xué)習(xí)率,為critic2網(wǎng)絡(luò)的損失函數(shù)相對(duì)于參數(shù)的梯度。
27、上述技術(shù)方案中,所述matd3算法模塊中actor網(wǎng)絡(luò)的參數(shù)θi的計(jì)算如下式所示:
28、
29、式中,θi為actor網(wǎng)絡(luò)的參數(shù),αa為actor網(wǎng)絡(luò)學(xué)習(xí)率,為第i個(gè)智能體期望獎(jiǎng)勵(lì)的策略梯度;
30、所述第i個(gè)智能體期望獎(jiǎng)勵(lì)的策略梯度計(jì)算公式如下式所示:
31、
32、式中,j(θi)為第i個(gè)智能體在t時(shí)刻內(nèi)的累積期望獎(jiǎng)勵(lì),e(·)為數(shù)學(xué)期望,si=(s1,s2,...,sn),為n個(gè)智能體在t時(shí)刻內(nèi)的聯(lián)合狀態(tài);ai=(a1,a2,...,an),為n個(gè)智能體在t時(shí)刻內(nèi)的聯(lián)合動(dòng)作;μi={μ1,μ2,...,μn},μi為參數(shù)為θ={θ1,θ2,...,θn}的n個(gè)智能體在t時(shí)刻內(nèi)策略集合;為critic1網(wǎng)絡(luò),由參數(shù)化;
33、所述第i個(gè)智能體在t時(shí)刻內(nèi)的累積期望獎(jiǎng)勵(lì)j(θi)如下式所示:
34、
35、式中,t為時(shí)間,e(·)為數(shù)學(xué)期望,γt為t時(shí)刻的折扣因子,為t時(shí)刻第i個(gè)智能體的聯(lián)合獎(jiǎng)勵(lì)。
36、上述技術(shù)方案中,所述matd3算法模塊中actor目標(biāo)網(wǎng)絡(luò)參數(shù)θ′i和critic目標(biāo)網(wǎng)絡(luò)參數(shù)φim更新公式如下:
37、θ′i=τθi+(1-τ)θ′i
38、
39、式中,θi′為actor目標(biāo)網(wǎng)絡(luò)參數(shù),φim為critic目標(biāo)網(wǎng)絡(luò)參數(shù)τ為軟更新系數(shù),0<τ≤1,m=1,2。
40、上述技術(shù)方案中,所述per排序模塊中樣本k的優(yōu)先級(jí)pk如下式所示:
41、
42、式中,pk為第k個(gè)樣本的優(yōu)先級(jí),分別為第i個(gè)智能體采用critc1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò)相對(duì)于第k個(gè)樣本的td誤差;
43、的計(jì)算如下式所示:
44、
45、式中,和分別為由和參數(shù)化的critic1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò),yi為第i個(gè)智能體的目標(biāo)q值;
46、所述per排序模塊中第k個(gè)樣本的采樣概率的計(jì)算如下式所示:
47、
48、式中,為第k個(gè)樣本的采樣概率,pk為第k個(gè)樣本的優(yōu)先級(jí),α為影響優(yōu)先級(jí)的0-1的超參數(shù),k為從經(jīng)驗(yàn)池中隨機(jī)抽取的樣本數(shù)。
49、上述技術(shù)方案中,所述樣本重要性評(píng)價(jià)模塊中,第k個(gè)樣本的采樣權(quán)重ωk的計(jì)算如下式所示:
50、
51、式中,ωk為第k個(gè)樣本的采樣權(quán)重,β為一個(gè)0-1的超參數(shù);
52、對(duì)采樣權(quán)重ωk進(jìn)行歸一化處理,如下式所示:
53、
54、式中,n為權(quán)重最大的樣本序號(hào)。
55、一種基于per-matd3深度強(qiáng)化學(xué)習(xí)的無(wú)人機(jī)動(dòng)態(tài)博弈模型的工作方法,包括以下步驟:
56、步驟1,初始化網(wǎng)絡(luò)參數(shù):
57、初始化各智能體的網(wǎng)絡(luò)參數(shù),并創(chuàng)建critic1網(wǎng)絡(luò)、critic2網(wǎng)絡(luò)和actor網(wǎng)絡(luò);
58、步驟2,初始化目標(biāo)網(wǎng)絡(luò):
59、初始化第i個(gè)智能體的目標(biāo)網(wǎng)絡(luò)參數(shù)和θi′并創(chuàng)建critic1目標(biāo)網(wǎng)絡(luò)、critic2目標(biāo)網(wǎng)絡(luò)和actor目標(biāo)網(wǎng)絡(luò);
60、步驟3,初始化超參數(shù):
61、初始化優(yōu)先級(jí)系數(shù)α,采樣權(quán)重系數(shù)β,經(jīng)驗(yàn)池d,軟更新系數(shù)τ,折扣因子γ,噪聲邊緣值c,每次提取的樣本數(shù)k,正態(tài)方差σ;
62、步驟4,訓(xùn)練循環(huán),在每個(gè)episode中執(zhí)行以下步驟:
63、s41產(chǎn)生隨機(jī)噪聲以進(jìn)行動(dòng)作探索;
64、s42獲取各智能體的初始狀態(tài)s=(s1,s2,...,sn),n為智能體總數(shù);
65、s43執(zhí)行動(dòng)作根據(jù)當(dāng)前策略選擇動(dòng)作,并執(zhí)行目標(biāo)動(dòng)作a′i(s′i);
66、s44將每次交互的數(shù)據(jù)<s1,a1,s′1,r1,...,sk,ak,s′k,rk>存放到經(jīng)驗(yàn)池d中,k為隨機(jī)抽取樣本數(shù)量;
67、步驟5,樣本選擇與更新:
68、s51,從經(jīng)驗(yàn)池d中隨機(jī)抽取k個(gè)樣本,第k個(gè)樣本的抽取概率為pk;
69、s52,計(jì)算第k個(gè)樣本的采樣權(quán)重ωk和td誤差δk;
70、s53,根據(jù)|δk|更新第k個(gè)樣本的優(yōu)先級(jí);
71、s54,計(jì)算目標(biāo)q值;
72、s55,最小化損失函數(shù)和更新critic1網(wǎng)絡(luò)和critic2網(wǎng)絡(luò),計(jì)算累積期望獎(jiǎng)勵(lì)j(θi);
73、步驟6,更新目標(biāo)網(wǎng)絡(luò)參數(shù)和θ′i;
74、步驟7,根據(jù)步驟1-6構(gòu)建無(wú)人機(jī)動(dòng)態(tài)博弈模型,求解完美貝葉斯-納什均衡,確定無(wú)人機(jī)機(jī)動(dòng)決策。
75、與現(xiàn)有技術(shù)相比,本發(fā)明的有益效果是:
76、1.構(gòu)建了matd3的算法框架,并引入優(yōu)先經(jīng)驗(yàn)回放(prioritized?experiencereplay,per)方法對(duì)其進(jìn)行改進(jìn),per方法根據(jù)每個(gè)經(jīng)驗(yàn)數(shù)據(jù)的重要性對(duì)其進(jìn)行優(yōu)先級(jí)排序,并且能夠在采樣時(shí)多次選擇更重要的經(jīng)驗(yàn),從而提高學(xué)習(xí)效率,進(jìn)而提高無(wú)人機(jī)空戰(zhàn)機(jī)動(dòng)決策的效率。
77、2.由于per方法會(huì)頻繁地使用具有較高td誤差的樣本,雖然能夠提高學(xué)習(xí)效率,但會(huì)不可避免地帶來(lái)偏差。為了避免訓(xùn)練時(shí)出現(xiàn)偏差導(dǎo)致振蕩甚至離散,引入重要性采樣方法,適當(dāng)降低td誤差高的樣本權(quán)重,使訓(xùn)練時(shí)每個(gè)樣本在梯度下降時(shí)的影響相同,從而保證訓(xùn)練結(jié)果的收斂性。
- 還沒(méi)有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!