一種基于多模態(tài)的先驗(yàn)-后驗(yàn)知識(shí)提示與推理方法
本發(fā)明屬于計(jì)算機(jī)視覺及醫(yī)學(xué)人工智能領(lǐng)域,涉及視覺問答技術(shù),具體為一種基于多模態(tài)的先驗(yàn)-后驗(yàn)知識(shí)提示與推理方法。
背景技術(shù):
1、外隨著醫(yī)療技術(shù)的發(fā)展,外科視覺問答(vqa)模型逐漸成為醫(yī)療學(xué)生和初級(jí)醫(yī)生外科培訓(xùn)中的重要輔助工具。此類模型在外科場(chǎng)景中展現(xiàn)出解決各類問題的廣泛潛力,能夠應(yīng)對(duì)諸如手術(shù)器械識(shí)別、手術(shù)步驟解析以及病理狀況判斷等多方面的需求。然而,現(xiàn)有的基于深度學(xué)習(xí)的外科vqa模型在生成和驗(yàn)證文本答案時(shí),往往僅依賴單一的驗(yàn)證機(jī)制,其復(fù)雜的架構(gòu)類似黑箱模型,內(nèi)部運(yùn)作難以明晰,這導(dǎo)致生成的響應(yīng)難以解釋,嚴(yán)重阻礙了外科vqa模型在實(shí)際臨床場(chǎng)景中的有效應(yīng)用。為解決這一問題,視覺問題定位回答系統(tǒng)應(yīng)運(yùn)而生,該系統(tǒng)在傳統(tǒng)視覺問答的基礎(chǔ)上引入了基礎(chǔ)答案驗(yàn)證機(jī)制,通過定位和強(qiáng)調(diào)視覺領(lǐng)域內(nèi)的相關(guān)區(qū)域,不僅能夠生成與外科領(lǐng)域相關(guān)的準(zhǔn)確答案,還能為答案提供直觀的視覺依據(jù),從而有效提升答案的準(zhǔn)確性與可解釋性。
2、然而現(xiàn)有視覺問題定位回答方法過度依賴當(dāng)前外科場(chǎng)景后續(xù)知識(shí)所提供的視覺文本信息,在處理同一外科場(chǎng)景內(nèi)的不同實(shí)例并回答相應(yīng)問題時(shí)較為困難。例如,在復(fù)雜的外科手術(shù)場(chǎng)景中,可能存在多個(gè)相似的解剖結(jié)構(gòu)或手術(shù)器械實(shí)例,現(xiàn)有方法難以精確聚焦于特定實(shí)例并作出準(zhǔn)確回應(yīng)。
技術(shù)實(shí)現(xiàn)思路
1、為了增強(qiáng)視覺定位回答模型對(duì)全球知識(shí)的理解和對(duì)局部信息的精確定位,滿足實(shí)時(shí)決策和外科程序準(zhǔn)確性的嚴(yán)格要求,本發(fā)明提供一種基于多模態(tài)的先驗(yàn)-后驗(yàn)知識(shí)提示與推理方法,使用先驗(yàn)知識(shí)來補(bǔ)充后續(xù)信息,能夠有效的將先驗(yàn)提示知識(shí)探索應(yīng)用于機(jī)器人手術(shù)任務(wù),進(jìn)而更好的生成定位答案并進(jìn)行更準(zhǔn)確的隱性推理以預(yù)測(cè)答案。
2、本發(fā)明為解決其技術(shù)問題所采用的技術(shù)方案是:
3、一種基于多模態(tài)的先驗(yàn)-后驗(yàn)知識(shí)提示與推理方法,步驟包括:
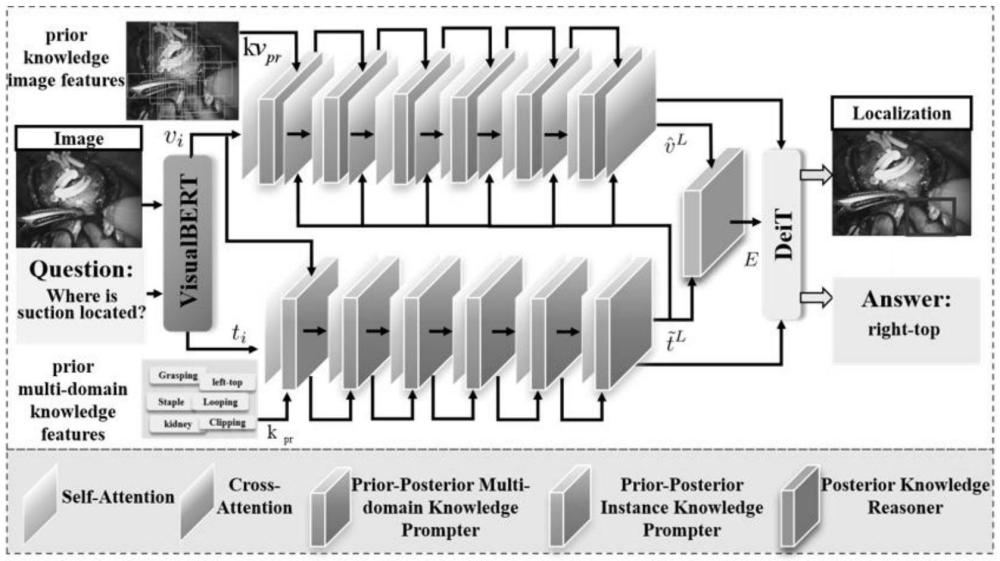
4、步驟1:給定一個(gè)手術(shù)場(chǎng)景i,通過預(yù)訓(xùn)練網(wǎng)絡(luò)模型rsenet18提取視覺特征v,同時(shí),由預(yù)訓(xùn)練分詞器提取文本特征t;視覺特征v和文本特征t通過自注意力機(jī)制處理,以提煉視覺特征v和文本特征t中有效的后驗(yàn)知識(shí)視覺特征vi和后驗(yàn)知識(shí)文本特征ti;
5、步驟2:利用cat-vil?deit模型吸收數(shù)據(jù)集中隱藏的先驗(yàn)知識(shí),隨后使用cat-vildeit模型提取與當(dāng)前手術(shù)場(chǎng)景中實(shí)例位置相關(guān)的潛在特征kvpr和與當(dāng)前手術(shù)場(chǎng)景中標(biāo)簽相關(guān)的潛在特征,整合kvpr和ktpr來構(gòu)建全面的先驗(yàn)多領(lǐng)域知識(shí)表示kpr,并利用先驗(yàn)-后驗(yàn)多領(lǐng)域知識(shí)提示模塊ppmp得到提示的后驗(yàn)知識(shí)文本特征
6、步驟3:利用先驗(yàn)-后驗(yàn)實(shí)例知識(shí)提示模塊ppip位數(shù)實(shí)例整合有價(jià)值的見解,從而在信息交互的動(dòng)態(tài)過程中保留與十九和文本特征相關(guān)的細(xì)節(jié),生成提示的后驗(yàn)知識(shí)視覺特征
7、步驟4:利用后驗(yàn)知識(shí)推理器,將后驗(yàn)知識(shí)文本特征和后驗(yàn)知識(shí)視覺特征整合,生成融合的嵌入特征e,將融合的嵌入特征e輸入到預(yù)訓(xùn)練的deit-base模塊中,以學(xué)習(xí)聯(lián)合表示,隨后聯(lián)合表示分別與和通過殘差連接合并,進(jìn)一步精煉關(guān)系;
8、步驟5:最后,使用來自檢測(cè)與變換器的分類頭,通過前饋網(wǎng)絡(luò)預(yù)測(cè)與問題相關(guān)的實(shí)例邊界框和答案。
9、通過利用先驗(yàn)知識(shí)補(bǔ)充后續(xù)信息,在步驟1中對(duì)視覺特征和文本特征采用自注意力機(jī)制處理提煉有效后驗(yàn)知識(shí)特征,以及在后續(xù)步驟中構(gòu)建先驗(yàn)多領(lǐng)域知識(shí)表示并與后驗(yàn)知識(shí)特征整合,能夠更加精準(zhǔn)地定位手術(shù)場(chǎng)景中的相關(guān)區(qū)域。借助先驗(yàn)-后驗(yàn)知識(shí)提示模塊(ppmp和ppip)以及后驗(yàn)知識(shí)推理器,在整合多模態(tài)知識(shí)的基礎(chǔ)上進(jìn)行推理預(yù)測(cè)答案,能夠充分考慮到手術(shù)場(chǎng)景中的各種因素,使模型對(duì)于手術(shù)相關(guān)問題的答案預(yù)測(cè)更加準(zhǔn)確。利用cat-vil?deit模型吸收數(shù)據(jù)集中隱藏的先驗(yàn)知識(shí),構(gòu)建全面的先驗(yàn)多領(lǐng)域知識(shí)表示,使得模型不再局限于單一手術(shù)場(chǎng)景的局部信息,而是能夠?qū)?dāng)前場(chǎng)景置于更廣泛的手術(shù)知識(shí)體系中進(jìn)行理解。在步驟3中先驗(yàn)-后驗(yàn)實(shí)例知識(shí)提示模塊ppip能夠在信息交互動(dòng)態(tài)過程中保留與實(shí)例和文本特征相關(guān)的細(xì)節(jié),生成提示的后驗(yàn)知識(shí)視覺特征,有助于模型在關(guān)注整體手術(shù)場(chǎng)景的同時(shí),不忽略局部關(guān)鍵信息的細(xì)節(jié)特征,將局部信息與全球知識(shí)有機(jī)結(jié)合。
10、進(jìn)一步的,步驟2具體包括:
11、步驟2.1:首先,專門為手術(shù)環(huán)境中的檢測(cè)和問答任務(wù)優(yōu)化了cat-vil?deit模型,旨在吸收訓(xùn)練數(shù)據(jù)集中隱含的先驗(yàn)知識(shí)。隨后,使用預(yù)訓(xùn)練的cat-vil?deit模型提取與當(dāng)前手術(shù)場(chǎng)景中實(shí)例位置和標(biāo)簽相關(guān)的潛在特征kvpr和ktpr。最終,整合這些潛在特征以構(gòu)建全面的先驗(yàn)多領(lǐng)域知識(shí)表示kpr。
12、步驟2.2:利用先驗(yàn)-后驗(yàn)多領(lǐng)域知識(shí)提示模塊ppmp從先驗(yàn)-后驗(yàn)視覺知識(shí)對(duì)齊和文本知識(shí)對(duì)齊中學(xué)習(xí)有意義的多領(lǐng)域知識(shí)提示。學(xué)習(xí)到的多領(lǐng)域知識(shí)通過殘差方法逐步集成到后驗(yàn)知識(shí)特征空間中。通過交叉注意力機(jī)制的支持,這種方法使得先驗(yàn)-后驗(yàn)知識(shí)提示與后驗(yàn)知識(shí)之間能夠進(jìn)行指引性的信息交互。為了避免過度引導(dǎo)并保持平衡,該過程重復(fù)多次,最終精煉提示的后驗(yàn)知識(shí)文本特征過程如下:
13、
14、其中:ppmpl(·)表示第l次的先驗(yàn)-后驗(yàn)多領(lǐng)域知識(shí)提示模塊,作為提示的后驗(yàn)知識(shí)文本特征分別表示第l次的后驗(yàn)知識(shí)和先驗(yàn)多領(lǐng)域知識(shí),分別表示第l-1次的后驗(yàn)知識(shí)和先驗(yàn)多領(lǐng)域知識(shí);且且其中cat(·)表示拼接操作。
15、步驟2.3:將先驗(yàn)多領(lǐng)域知識(shí)表示kpr通過自注意力機(jī)制進(jìn)行編碼后得到編碼的先驗(yàn)多領(lǐng)域知識(shí)特征kpre,kpre經(jīng)過上采樣操作以確保與每個(gè)領(lǐng)域后驗(yàn)知識(shí)特征的空間維度對(duì)齊。隨后,后驗(yàn)知識(shí)文本特征ti、后驗(yàn)知識(shí)視覺特征vi和編碼的先驗(yàn)多領(lǐng)域知識(shí)特征kpre通過縮放的點(diǎn)積方法投影到兩個(gè)聯(lián)合特征空間中融合,通過殘差結(jié)構(gòu)融合這些表示,有助于先驗(yàn)知識(shí)和后驗(yàn)知識(shí)的對(duì)齊。最后,融合特征經(jīng)過上采樣操作,以匹配每個(gè)領(lǐng)域后驗(yàn)知識(shí)特征的特征維度,輸出對(duì)齊的融合特征a:
16、
17、其中:kpre=fsa(kpri)表示編碼的先驗(yàn)多領(lǐng)域知識(shí)特征,fsa(·)表示自注意力機(jī)制,kpri表示輸入的先驗(yàn)多領(lǐng)域知識(shí)特征,fu1和fu2表示上采樣操作,dt和dv是可學(xué)習(xí)參數(shù),t表示矩陣轉(zhuǎn)置;上述過程僅在第一次迭代中執(zhí)行;
18、步驟2.4:在交叉注意力機(jī)制下,對(duì)齊的融合特征a學(xué)習(xí)先驗(yàn)知識(shí)特征和后驗(yàn)知識(shí)文本特征之間的依賴關(guān)系,并借助殘差結(jié)構(gòu)更新特圖:
19、to=fc(kpri,ti,ti)+ti
20、kpro=fc(ti,kpri,kpri)
21、其中:fc表示交叉注意力機(jī)制,to表示更新后的后驗(yàn)知識(shí)文本特征,kpro表示更新后的先驗(yàn)多領(lǐng)域知識(shí)特征,ti表示輸入的后驗(yàn)知識(shí)文本特征,kpri表示先驗(yàn)多領(lǐng)域知識(shí)特征;第一次迭代中kpri=a,其他迭代中kpri=kpre。
22、進(jìn)一步的,步驟3具體包括:
23、步驟3.1:先驗(yàn)-后驗(yàn)實(shí)例知識(shí)提示模塊ppip通過對(duì)齊先驗(yàn)和后驗(yàn)知識(shí)的視覺特征,為實(shí)例整合有價(jià)值的見解,以在信息交互的動(dòng)態(tài)過程中保留與視覺和文本特征相關(guān)的細(xì)節(jié),重復(fù)執(zhí)行上述過程,最終生成提示的后驗(yàn)知識(shí)視覺特征
24、
25、其中:ppipl(·)表示第l次的先驗(yàn)-后驗(yàn)實(shí)例知識(shí)模塊,作為提示的后驗(yàn)知識(shí)視覺特征表示第l次的后驗(yàn)知識(shí)視覺特征,表示手術(shù)場(chǎng)景中與實(shí)例位置相關(guān)的潛在特征;表示第l-1次的后驗(yàn)知識(shí)視覺特征,表示手術(shù)場(chǎng)景中與實(shí)例位置相關(guān)的潛在特征;且且其中表示后驗(yàn)知識(shí)視覺特征;
26、步驟3.2:先驗(yàn)知識(shí)視覺特征和后驗(yàn)知識(shí)視覺特征通過自注意力機(jī)制和空間聚焦模塊增強(qiáng)空間位置信息,隨后,對(duì)編碼的先驗(yàn)知識(shí)視覺特征執(zhí)行下采樣操作,然后,通過交叉注意力機(jī)制促進(jìn)先驗(yàn)知識(shí)視覺特征和后驗(yàn)知識(shí)視覺特征之間依賴關(guān)系的學(xué)習(xí),集成增強(qiáng)的后驗(yàn)知識(shí)視覺特征與增強(qiáng)的先驗(yàn)知識(shí)視覺特征,最后,通過殘差結(jié)構(gòu)更新先驗(yàn)知識(shí)視覺特征和后驗(yàn)知識(shí)視覺特征:
27、vo=fc(kve,fsf(vi),fsf(vi))+vi
28、kvo=fc(fsf(vi),kve,kve)
29、其中:vo表示更新后的后驗(yàn)知識(shí)視覺特征,kvo表示更新后的先驗(yàn)知識(shí)視覺特征,vi表示輸入的后驗(yàn)知識(shí)視覺特征,kve表示從輸入的先驗(yàn)知識(shí)視覺特征獲得的增強(qiáng)先驗(yàn)知識(shí)視覺特征;在第一次迭代中kvo=fd(fsa(kvpr)),在其他迭代中kve=fsa(kvo);fsa(·)表示自注意力機(jī)制,fd表示。
30、進(jìn)一步的,步驟4具體包括:
31、首先,將和整合,通過一個(gè)融合模塊,該模塊包括兩個(gè)迭代注意特征融合(iaff)模塊,生成融合的嵌入特征e:
32、
33、其中fia1和fia2表示兩個(gè)iaff模塊。然后,將融合的嵌入特征e輸入到預(yù)訓(xùn)練deit-base模塊中,以學(xué)習(xí)聯(lián)合表示。隨后,聯(lián)合表示分別與和通過殘差連接合并,進(jìn)一步精煉每個(gè)領(lǐng)域內(nèi)特征之間的關(guān)系。最終,使用來自檢測(cè)與變換器的分類頭,通過前饋網(wǎng)絡(luò)預(yù)測(cè)與問題相關(guān)的實(shí)例邊界框和答案。
34、本發(fā)明的有益效果包括:
35、本發(fā)明提出了一種基于多模態(tài)的先驗(yàn)-后驗(yàn)知識(shí)提示與推理方法,通過結(jié)合手術(shù)過程中的豐富先驗(yàn)知識(shí),幫助模型更好地理解手術(shù)圖像中的場(chǎng)景。通過多領(lǐng)域知識(shí)對(duì)齊和實(shí)例知識(shí)提示模塊,有效提高了對(duì)手術(shù)場(chǎng)景中具體目標(biāo)區(qū)域的識(shí)別和定位能力,確保生成的答案更加準(zhǔn)確、符合實(shí)際情況。此外,該方法在推理過程中逐步融合圖像視覺信息和文本知識(shí),使得模型能夠更好地處理復(fù)雜的手術(shù)場(chǎng)景,從而提高整體推理的準(zhǔn)確性和一致性。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!