一種混合專家多模態(tài)大模型特征融合方法及系統(tǒng)與流程
本發(fā)明涉及多模態(tài)機器學習領域,具體涉及一種混合專家多模態(tài)大模型特征融合方法及系統(tǒng)。
背景技術:
1、在自然語言處理和多模態(tài)機器學習領域,隨著深度學習技術的迅速發(fā)展,基于transformer架構的大模型已經(jīng)成為應對復雜任務的主要手段。然而,現(xiàn)有的大模型在處理多模態(tài)任務時,往往無法充分捕捉和融合不同模態(tài)間的信息。這種局限性導致模型在處理跨模態(tài)任務時,信息融合效果不佳,進而影響任務的整體性能。例如,在同時處理圖像、文本和語音信息時,現(xiàn)有模型通常難以有效結合這些模態(tài)的信息,從而導致模型在復雜場景中的表現(xiàn)不盡如人意。
2、為了提升模型在多模態(tài)任務中的表現(xiàn),研究人員提出了多種方法,如直接將多模態(tài)數(shù)據(jù)拼接輸入模型或利用簡單的注意力機制進行模態(tài)間的信息交互。然而,這些方法往往難以應對模態(tài)間信息不對齊的問題。具體來說,不同模態(tài)的數(shù)據(jù)在時序、尺度、甚至語義上都可能存在顯著差異,直接進行信息融合可能導致重要信息的丟失或噪聲的引入,從而影響模型的準確性和泛化能力。此外,現(xiàn)有的方法在處理大規(guī)模多模態(tài)數(shù)據(jù)時,也面臨著計算效率和存儲需求方面的挑戰(zhàn),難以在實際應用中廣泛推廣。
3、現(xiàn)有大模型的另一個問題在于其龐大的參數(shù)規(guī)模和計算資源的消耗。雖然大模型在處理復雜任務時展現(xiàn)出了強大的能力,但其巨大的計算開銷和推理時間,使得在資源有限的環(huán)境下難以應用。此外,由于大模型需要處理大量參數(shù),訓練和推理的過程也往往難以進行實時的性能優(yōu)化,無法快速響應任務需求。因此,如何在保持模型性能的同時,減少計算資源的消耗,成為了現(xiàn)有技術的一大挑戰(zhàn)。
4、為了解決這些問題,知識蒸餾方法被提出,將大模型的知識遷移到小模型中,從而在減少參數(shù)規(guī)模的同時,保留模型的性能。然而,傳統(tǒng)的知識蒸餾方法通常只關注模型的整體性能,而忽略了小模型在多模態(tài)任務中的特定表現(xiàn)。由于缺乏針對多模態(tài)任務的蒸餾策略,小模型在實際應用中難以達到預期的效果,尤其是在處理不同模態(tài)間復雜信息交互時,蒸餾后的小模型表現(xiàn)仍然有限。這些問題使得現(xiàn)有的多模態(tài)大模型特征融合方法在應用上存在一定的局限性。
5、如圖1所示,當前基于多模型混合的多模態(tài)特征融合方法在擴展方面面臨著嚴重的挑戰(zhàn)。簡單增加模型參數(shù)或堆疊模型結構雖然能夠在一定程度上提升性能,但卻帶來了計算資源的巨大浪費和性能瓶頸。此外,隨著專家數(shù)量的增加,管理和分配數(shù)據(jù)的難度也顯著上升,導致模型擴展策略缺乏靈活性和實用性。
6、即使在一些情況下能夠成功地擴展小模型,但其落地應用仍然困難重重。這主要是由于小模型在面對多模態(tài)任務時,難以捕捉到細致和關鍵的特征信息。同時,現(xiàn)有的固定門控機制和簡單融合策略往往限制了模型的表現(xiàn),無法充分適應任務需求,從而使得小模型的多模態(tài)特征融合效果不佳。
7、多模態(tài)特征融合的挑戰(zhàn)不僅體現(xiàn)在小模型的擴展上,還表現(xiàn)在融合策略的設計上。簡單的融合策略往往難以應對多模態(tài)任務中的復雜需求,導致模型在這些任務中的表現(xiàn)欠佳。當前的方法在門控機制上過于固定,缺乏靈活性,難以適應動態(tài)的任務變化,最終使得多模態(tài)融合的效果不佳。
技術實現(xiàn)思路
1、有鑒于此,本發(fā)明實施例提供了一種混合專家多模態(tài)大模型特征融合方法及系統(tǒng),用以解決或部分解決上述問題,顯著提升了模型性能、處理效率和任務普適性。
2、實現(xiàn)本發(fā)明目的的技術解決方案為:
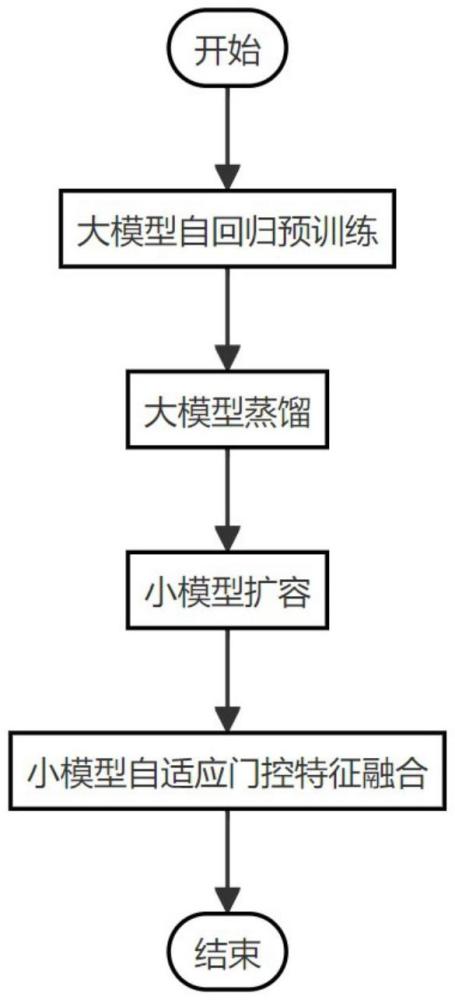
3、一種混合專家多模態(tài)大模型特征融合方法,包括以下步驟:
4、s1,構建多個模態(tài)下的數(shù)據(jù)集,分別對大模型進行自回歸預訓練,得到每個領域?qū)拇竽P停?/p>
5、s2,進行大模型到小模型的蒸餾過程,通過軟標簽將大模型的知識傳遞給小模型,得到每個模態(tài)下的小模型;
6、s3,對每個模態(tài)下的小模型擴容,得到每個模態(tài)下的小模型組;
7、s4,將多個模態(tài)下的小模型組通過軟標簽嵌入的自適應門控網(wǎng)絡進行融合,得到一個適應多模態(tài)的模型。
8、進一步地,進行大模型到小模型的蒸餾過程,得到每個模態(tài)下的小模型,具體包括步驟:
9、s2.1,配置教師模型和學生模型,教師模型為步驟s1訓練好的大模型;令教師模型為學生模型為多種學生模型備選
10、s2.2,調(diào)整溫度參數(shù),通過歸一化指數(shù)函數(shù)softmax獲取教師模型的soft?labels;
11、s2.3,學生模型通過softprediction和soft?labels計算蒸餾損失;
12、s2.4,學生模型通過hardprediction和ground?truth計算損失;
13、s2.5,基于步驟2.3和s2.4的損失,通過權重系數(shù)計算總的損失函數(shù);
14、s2.6,基于損失函數(shù),進行教師模型到學生模型的蒸餾,獲取滿足要求的學生模型,即小模型。
15、進一步地,所述教師模型的soft?labels為:
16、
17、其中,t為溫度參數(shù),zt為教師模型的輸出。
18、進一步地,所述步驟s2.3的蒸餾損失為:
19、
20、其中,ps為學生模型的softprediction,zs為學生模型的輸出,kl(·)為kl散度函數(shù)。
21、進一步地,步驟s2.4的損失為:
22、
23、其中,為均方誤差函數(shù)。
24、進一步地,所述步驟2.5中總的損失函數(shù)為:
25、
26、其中,α為權重系數(shù)。
27、進一步地,所述多個模態(tài)下的小模型組通過自適應門控網(wǎng)絡進行融合,具體包括:
28、每個小模型接收不同模態(tài)的數(shù)據(jù)并生成特征token;
29、通過自適應門控網(wǎng)絡進行融合,根據(jù)每個token的特征和上下文信息,自適應激活對應的專家網(wǎng)絡,即小模型。
30、進一步地,構建多個模態(tài)下的數(shù)據(jù)集具體包括:
31、s1.1,對文本數(shù)據(jù)通過子詞切分算法分詞并token化;
32、s1.2,將圖像數(shù)據(jù)劃分為多個固定大小的patch并編碼為token;
33、s1.3,將語音數(shù)據(jù)分段并轉換為特征向量,再進行token化;
34、s1.4,通過隨機掩碼和序列補全對步驟s1.1-步驟s1.3的數(shù)據(jù)處理,得到數(shù)據(jù)集。
35、一種混合專家多模態(tài)大模型特征融合系統(tǒng),包括:
36、數(shù)據(jù)構建單元,用于構建多個模態(tài)下的數(shù)據(jù)集;
37、大模型訓練單元,通過數(shù)據(jù)集對大模型進行自回歸預訓練,通過軟標簽將大模型的知識傳遞給小模型,得到每個領域?qū)拇竽P停?/p>
38、蒸餾單元,進行大模型到小模型的蒸餾過程,得到每個模態(tài)下的小模型;
39、擴容單元,對每個模態(tài)下的小模型擴容,得到每個模態(tài)下的小模型組;
40、融合單元,將多個模態(tài)下的小模型組通過軟標簽嵌入的自適應門控網(wǎng)絡進行融合,得到一個適應多模態(tài)的模型。
41、本發(fā)明的實施例至少具有如下技術效果:
42、(1)提升多模態(tài)數(shù)據(jù)的精確處理能力。本發(fā)明通過自回歸預訓練,在處理文本、圖像、語音等多模態(tài)數(shù)據(jù)時能夠更精確地預測和生成序列信息;通過多模態(tài)數(shù)據(jù)的聯(lián)合訓練,模型可以捕捉到不同模態(tài)之間的深層關聯(lián),從而在實際應用中提供更準確的結果;這種精確的特征提取和序列預測顯著提升了多模態(tài)任務的處理效果,使得在復雜環(huán)境下的應用更具魯棒性。
43、(2)提高模型推理效率。通過大模型蒸餾為小模型,本發(fā)明顯著提高了模型的推理速度。小模型在保持大模型知識的同時,參數(shù)量大幅減少,推理效率得到顯著提升;這種高效的推理能力使得模型在資源受限的環(huán)境中仍能提供高質(zhì)量的輸出,從而擴展了應用場景的可能性。
44、(3)增強模型的適應性與擴展性。本發(fā)明通過小模型的擴容,提升了模型應對多樣化任務的能力。通過增加專家網(wǎng)絡的數(shù)量并采用自適應門控策略,模型能夠靈活處理不同類型的多模態(tài)數(shù)據(jù),確保各模態(tài)的關鍵信息能夠被有效整合;這種擴展性不僅提高了模型的適應性,還在廣泛任務中展現(xiàn)出卓越的性能。
45、(4)優(yōu)化多模態(tài)特征融合的效率。自適應門控策略在特征融合過程中有效地激活了適合的專家網(wǎng)絡,使得不同模態(tài)的數(shù)據(jù)能夠在更細致的層面上進行融合;通過這種機制,本發(fā)明在多模態(tài)數(shù)據(jù)處理上實現(xiàn)了更高效的信息整合,確保各模態(tài)的重要特征得以充分利用,從而在決策過程中提供更為全面和準確的支持。
46、(5)實現(xiàn)模型性能的動態(tài)優(yōu)化。本發(fā)明在模型擴容階段,通過多組benchmark任務實時衡量擴容效果,自動挑選最佳專家進行模型優(yōu)化;通過這種動態(tài)的實驗調(diào)整,模型在處理不同任務時能夠自動適應,確保始終處于最佳性能狀態(tài);這種自動化的優(yōu)化過程不僅提升了模型的整體質(zhì)量,還減少了人工干預的需求,大大提高了開發(fā)效率。
- 還沒有人留言評論。精彩留言會獲得點贊!