一種針對細粒度標簽混淆的層次文本分類方法及系統
本發明涉及層次文本分類,更具體的說是涉及一種針對細粒度標簽混淆的層次文本分類方法及系統。
背景技術:
1、層次文本分類(htc)在處理各領域復雜且海量的文本數據中具有重要作用,例如學術文獻、法律文件以及在線內容等。htc是一種將文本歸類到多層級類別結構的復雜方法。與傳統平面分類方法僅關注單一標簽分配不同,htc充分考慮了類別間的從屬關系,構建了從抽象到具體的層級結構。這種層次結構可以采用簡單的兩級結構,也可以采用更復雜、深度嵌套的排列方式,通常被建模為樹或有向無環圖。然而,htc因為數據分布不平衡和層次結構中多個級別之間復雜的依賴關系導致粒度越細的標簽之間的區分度越低——這在某些類別樣例不足的大型數據集中很常見,并且隨著層級越深,標簽之間的混淆程度越高。
2、近些年來,研究者們相繼引入了一些方法來解決htc的難題,例如元學習,強化學習,圖卷積網絡。但是,現有方法都無法徹底解決htc中細粒度標簽的難題。并且,區分深層、細粒度的標簽對于htc的性能至關重要。幸運的是,已有的一些研究表明,對比學習在增強細粒度特征表示方面表現優異,它能夠有效地學習到細粒度標簽之間細微的特征表示,從而提升細粒度標簽之間的區分度。然而,由于復雜的層次結構導致現有的方法在htc中難以為對比學習構建高質量的正負樣本,它們只是在文本角度利用數據增強的方式構建正樣本和簡單的構建低質量的負樣本,沒有涉及到相似的細粒度標簽的處理。
3、因此,如何提供一種針對細粒度標簽混淆的層次文本分類方法及系統,擴大負樣本特征范圍,提高負樣本質量,使模型訓練更加高效,提升層次文本分類效果是本領域技術人員亟需解決的問題。
技術實現思路
1、有鑒于此,本發明提供了一種針對細粒度標簽混淆的層次文本分類方法及系統,從節點和序列兩個角度生成高質量負樣本,擴大的負樣本特征范圍,提高了負樣本質量;在模型訓練過程中動態選擇最困難的負樣本,使模型訓練更加高效;利用高質量負樣本,充分發揮對比學習作用,提升層次文本分類效果。
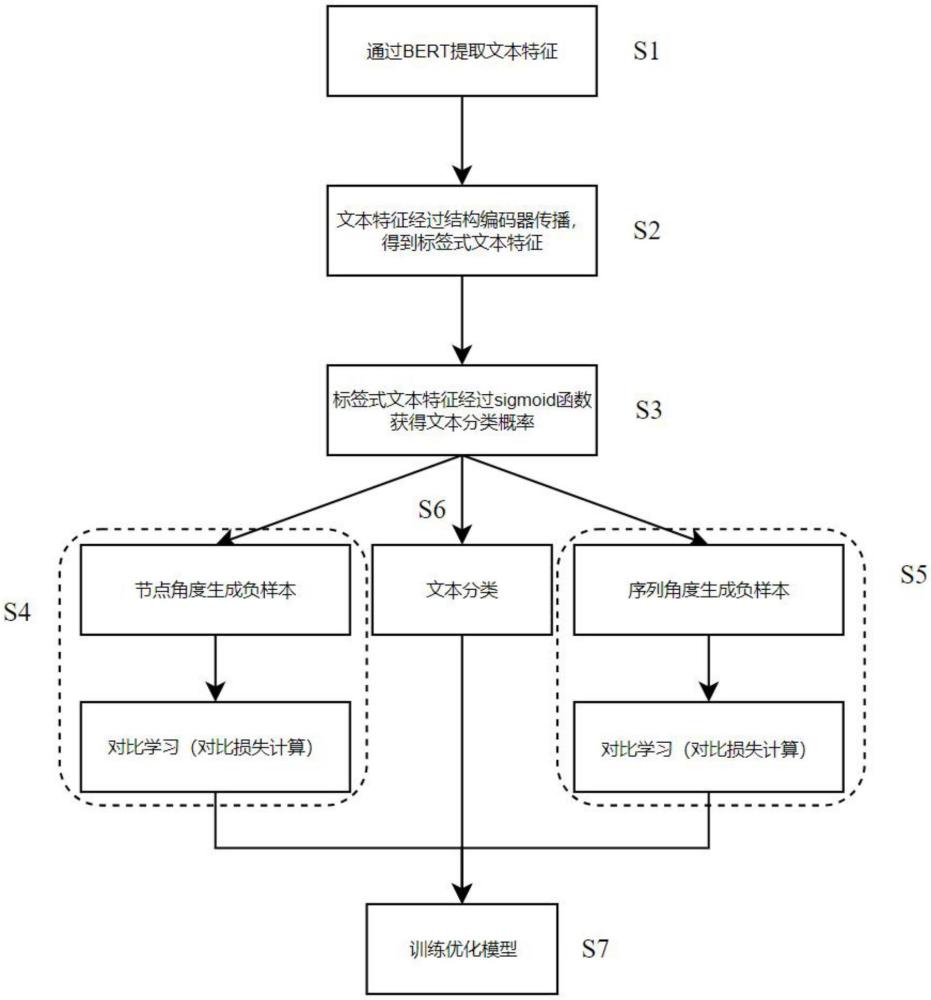
2、為了實現上述目的,本發明采用如下技術方案:一種針對細粒度標簽混淆的層次文本分類方法,包括:
3、獲取待分類文本;
4、對所述待分類文本進行特征提取,處理后得到文本的標簽特征;
5、根據所述標簽特征,得到文本分類概率,基于所述文本分類概率確定節點負樣本和節點正樣本,所述節點正樣本和所述節點負樣本之間進行對比學習,得到第一損失函數;
6、利用標簽結構和深度優先遍歷算法構造多個序列負樣本和序列正樣本,計算序列負樣本和序列正樣本的對比損失,得到第二損失函數;
7、計算多標簽分類的第三損失函數;
8、對所述第一損失函數、所述第二損失函數和所述第三損失函數求和,得到總損失函數;
9、通過優化總損失函數訓練bert模型;
10、根據訓練好的bert模型對待分類文本進行分類,得到文本的分類結果。
11、優選的,選擇非groundtruth中文本分類概率前n的標簽作為節點負樣本,選擇groundtruth中文本分類概率最低的標簽作為節點正樣本。
12、優選的,對所述待分類文本進行特征提取,處理后得到文本的標簽特征,包括:
13、采用bert模型對所述待分類文本進行特征提取,得到文本特征;通過結構編碼器對所述文本特征進行處理,得到文本的標簽特征。
14、優選的,所述節點正樣本和所述節點負樣本之間進行對比學習,包括:
15、lnode=∑i∈smax(0,pg-pi+ε);
16、其中,pg代表節點正樣本的概率,pi代表節點負樣本的概率,ε代表節點正樣本和節點負樣本分類概率之間的差值,s代表整個負樣本集合,lnode表示第一損失函數。
17、優選的,利用標簽結構和深度優先遍歷算法構造多個序列負樣本和序列正樣本,包括:
18、利用深度優先遍歷算法遍歷整個標簽結構,得到所有的標簽路徑;
19、將所有的標簽路徑和groundtruth計算f1分數,將相同f1分數的標簽路徑分為一組;
20、根據文本分類概率,將標簽路徑上的節點求和后取平均,得到整個標簽路徑的平均概率p;
21、將每組平均概率p最大的標簽路徑選出來,構建為序列負樣本,ground?truth作為序列正樣本。
22、優選的,計算序列負樣本和序列正樣本的對比損失,得到第二損失函數,包括:
23、對序列負樣本和序列正樣本之間進行對比損失計算,得到第一子損失函數;
24、對序列負樣本之間進行對比損失計算,得到第二子損失函數;
25、根據所述第一子損失函數和所述第二子損失函數得到第二損失函數。
26、優選的,計算多標簽分類的第三損失函數,包括:
27、所述第三損失函數為交叉熵損失函數,表示為:
28、
29、其中,yij為真實標簽,lc為交叉熵損失,為預測概率。
30、優選的,一種針對細粒度標簽混淆的層次文本分類系統,包括:
31、文本獲取模塊,用于獲取待分類文本;
32、文本標簽特征獲取模塊,用于對所述待分類文本進行特征提取,處理后得到文本的標簽特征;
33、第一損失函數獲取模塊,用于根據所述標簽特征,得到文本分類概率,基于所述文本分類概率確定節點負樣本和節點正樣本,所述節點正樣本和所述節點負樣本之間進行對比學習,得到第一損失函數;
34、第二損失函數獲取模塊,用于利用標簽結構和深度優先遍歷算法構造多個序列負樣本和序列正樣本,計算序列負樣本和序列正樣本的對比損失,得到第二損失函數;
35、第三損失函數獲取模塊,用于計算多標簽分類的第三損失函數;
36、總損失函數獲取模塊,用于對所述第一損失函數、所述第二損失函數和所述第三損失函數求和,得到總損失函數;
37、優化模塊,用于通過優化總損失函數訓練bert模型;
38、分類結果輸出模塊,用于根據訓練好的bert模型對待分類文本進行分類,得到文本的分類結果。
39、經由上述的技術方案可知,與現有技術相比,本發明公開提供了一種針對細粒度標簽混淆的層次文本分類方法及系統,包括:獲取待分類文本;對所述待分類文本進行特征提取,處理后得到文本的標簽特征;根據所述標簽特征,得到文本分類概率,基于所述文本分類概率確定節點負樣本和節點正樣本,所述節點正樣本和所述節點負樣本之間進行對比學習,得到第一損失函數;利用標簽結構和深度優先遍歷算法構造多個序列負樣本和序列正樣本,計算序列負樣本和序列正樣本的對比損失,得到第二損失函數;計算多標簽分類的第三損失函數;對所述第一損失函數、所述第二損失函數和所述第三損失函數求和,得到總損失函數;通過優化總損失函數訓練bert模型;根據訓練好的bert模型對待分類文本進行分類,得到文本的分類結果。本發明具有以下有益效果:(1)從節點和序列兩個角度生成高質量負樣本,擴大了負樣本特征范圍,提高了負樣本質量;(2)本發明在模型訓練過程中動態選擇最困難的負樣本,使模型訓練更加高效;(3)本發明利用高質量負樣本,充分發揮對比學習作用,提升層次文本分類效果。
- 還沒有人留言評論。精彩留言會獲得點贊!