一種去標識化方法、裝置及設備與流程
本發明涉及信息安全,特別涉及一種去標識化方法、裝置及設備。
背景技術:
1、在醫療保健相關領域,通常使用電子健康記錄(ehr,electronic?health?record)來實時更新患者健康信息,對患者健康狀況進行數字化追蹤,從而在不同機構之間共享患者信息,確保患者治療的連貫性。因此,結構化數據在ehr中得到了廣泛應用,但非結構化數據(例如病史、體檢記錄和病理報告)蘊含著更為豐富的患者信息。為了在前沿研究中有效利用這些非結構化數據,亟需采用一些具備可擴展性的去標識化技術。
2、然而,現有技術中的去標識化技術通過模式匹配系統預先定義的規則來識別實體,再對實體進行替換,由于模式匹配系統的規則是固定的,如果文本格式不完全符合預先定義規則,則系統可能出現誤報或檢測錯誤,因此,如何實現高準確率和高效率的去標識化技術成為丞待解決的技術問題。
技術實現思路
1、本發明提供一種去標識化方法、裝置及設備,用以解決現有去標識化技術準確率較低的問題。
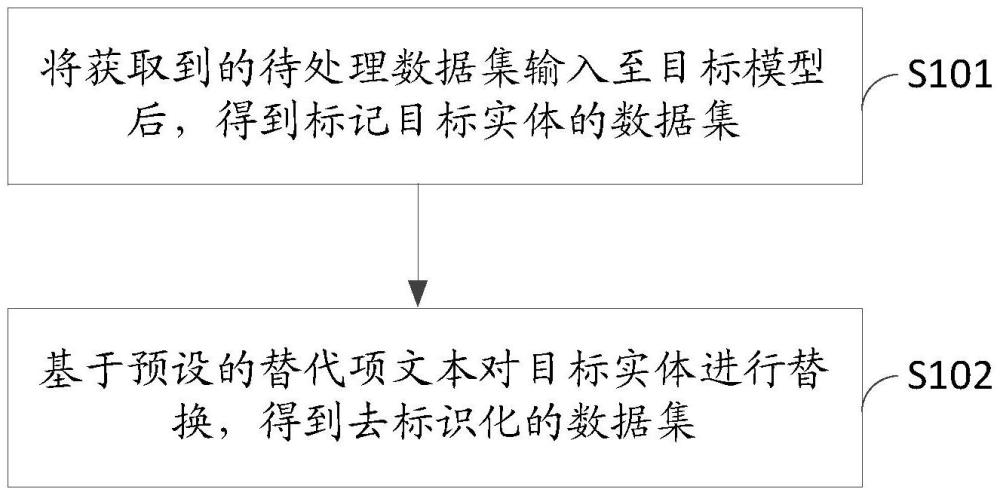
2、第一方面,本技術提供一種去標識化方法,所述方法包括:
3、將獲取到的待處理數據集輸入至目標模型后,得到標記目標實體的數據集;
4、基于預設的替代項文本對所述目標實體進行替換,得到去標識化的數據集;
5、其中,所述目標模型是通過下列方式訓練得到的:
6、基于iob標記法對目標數據集進行第一實體標記,得到第一標記數據集;
7、基于正則表達式和所述第一實體標記,對所述第一標記數據集進行第二實體標記,得到第二標記數據集,并將所述第二標記數據集作為訓練集;
8、基于所述訓練集對多個預訓練子模型進行訓練,在訓練后的子模型的精確率小于精確率閾值的情況下,返回至基于正則表達式和所述第一實體標記,對所述第一標記數據集進行第二實體標記的步驟,直至訓練后的子模型的精確率大于等于所述精確率閾值;在訓練后的子模型的精確率大于等于所述精確率閾值的情況下,確定所述子模型通過訓練,將通過訓練的多個子模型構成的模型作為所述目標模型。
9、在一種可能的實施方式中,所述基于iob標記法對目標數據集進行第一實體標記,得到第一標記數據集,包括:
10、對所述目標數據集進行分詞處理,得到所述目標數據集的多個詞匯;
11、基于iob標記法,針對每個詞匯,在確定所述詞匯為實體的情況下,將所述詞匯的實體開始部分標記為第一標記,將所述詞匯的實體內部部分標記為第二標記;在確定所述詞匯為非實體的情況下,將所述詞匯標記為第三標記;
12、將標記后的所述目標數據集作為所述第一標記數據集
13、在一種可能的實施方式中,所述基于正則表達式和所述第一實體標記,對所述標記數據集進行第二實體標記之前,還包括:
14、統計所述第一標記數據集中第一目標文本的重復率;
15、在確定所述第一目標文本的重復率大于等于重復率閾值的情況下,將所述第一目標文本加入目標集合;
16、基于所述目標集合刪除所述第一標記數據集中的所述第一目標文本。
17、在一種可能的實施方式中,所述正則表達式通過如下方法確定:
18、基于模式匹配方法確定所述第一標記數據集的目標詞匯,并基于預設的第一對應關系將所述目標詞匯的第一實體標記更新為第一替換詞;
19、基于所述第一標記數據集中的第一實體標記,確定所述目標詞匯對應的實體類別;
20、基于所述實體類別和預設的第二對應關系,將所述第一替換詞更新為第二替換詞,并將所述目標詞匯的第一實體標記與所述第二替換詞的第三對應關系作為所述正則表達式。
21、在一種可能的實施方式中,所述基于所述訓練集對多個預訓練子模型進行訓練,包括:
22、向所述訓練集的每個預訓練實體類別分配預訓練子模型;
23、確定所述預訓練子模型中訓練集的目標實體類別,其中,所述目標實體類別是訓練過程中最高置信度對應的實體類別;
24、在所述目標實體類別與所述預訓練實體類別一致的情況下,確定所述預訓練子模型完成訓練;在所述目標實體類別與所述預訓練實體類別不一致的情況下,繼續訓練所述預訓練子模型。
25、在一種可能的實施方式中,所述在訓練后的子模型的精確率小于精確率閾值的情況下,返回至基于正則表達式和所述第一實體標記,對所述標記數據集進行第二實體標記的步驟,之前,還包括:
26、確定所述第二標記數據集中不存在第二實體標記的第二目標文本,將所述第二目標文本加入至所述目標集合;
27、基于所述目標集合刪除所述標記數據集中的所述第二目標文本。
28、在一種可能的實施方式中,所述基于預設的替代項文本對所述目標實體進行替換,得到去標識化的數據集,包括:
29、確定所述目標實體的實體類別和位置;
30、對確定實體類別一致,且實體實例一致的目標實體標記預設標簽;
31、基于所述預設標簽與替代項文本的第四對應關系,將所述目標實體替換為所述替代項文本,得到去標識化的數據集,其中,所述第四對應關系為預先設定的。
32、第二方面,本技術實施例還提供一種去標識化裝置,所述裝置包括:
33、標記單元,用于將獲取到的待處理數據集輸入至目標模型后,得到標記目標實體的數據集;
34、替換單元,用于基于預設的替代項文本對所述目標實體進行替換,得到去標識化的數據集;
35、訓練單元,用于基于iob標記法對目標數據集進行第一實體標記,得到第一標記數據集;基于正則表達式和所述第一實體標記,對所述標記數據集進行第二實體標記,得到第二標記數據集,并將所述第二標記數據集作為訓練集;基于所述訓練集對多個預訓練子模型進行訓練,在訓練后的子模型的精確率小于精確率閾值的情況下,返回至基于正則表達式和所述第一實體標記,對所述標記數據集進行第二實體標記的步驟,直至訓練后的子模型的精確率大于等于所述精確率閾值;在訓練后的子模型的精確率大于等于所述精確率閾值的情況下,確定所述子模型通過訓練,將通過訓練的多個子模型構成的模型作為所述目標模型
36、在一種可能的實施方式中,所述訓練單元具體用于:
37、對所述目標數據集進行分詞處理,得到所述目標數據集的多個詞匯;
38、基于iob標記法,針對每個詞匯,在確定所述詞匯為實體的情況下,將所述詞匯的實體開始部分標記為第一標記,將所述詞匯的實體內部部分標記為第二標記;在確定所述詞匯為非實體的情況下,將所述詞匯標記為第三標記;
39、將標記后的所述目標數據集作為所述第一標記數據集。
40、在一種可能的實施方式中,所述訓練單元具體用于:
41、統計所述第一標記數據集中第一目標文本的重復率;
42、在確定所述第一目標文本的重復率大于等于重復率閾值的情況下,將所述第一目標文本加入目標集合;
43、基于所述目標集合刪除所述第一標記數據集中的所述第一目標文本。
44、在一種可能的實施方式中,所述訓練單元具體用于:
45、基于模式匹配方法確定所述第一標記數據集的目標詞匯,并基于預設的第一對應關系將所述目標詞匯的第一實體標記更新為第一替換詞;
46、基于所述第一標記數據集中的第一實體標記,確定所述目標詞匯對應的實體類別;
47、基于所述實體類別和預設的第二對應關系,將所述第一替換詞更新為第二替換詞,并將所述目標詞匯的第一實體標記與所述第二替換詞的第三對應關系作為所述正則表達式。
48、在一種可能的實施方式中,所述訓練單元具體用于:
49、向所述訓練集的每個預訓練實體類別分配預訓練子模型;
50、確定所述預訓練子模型中訓練集的目標實體類別,其中,所述目標實體類別是訓練過程中最高置信度對應的實體類別;
51、在所述目標實體類別與所述預訓練實體類別一致的情況下,確定所述預訓練子模型完成訓練;在所述目標實體類別與所述預訓練實體類別不一致的情況下,繼續訓練所述預訓練子模型。
52、在一種可能的實施方式中,所述訓練單元還用于:
53、確定所述第二標記數據集中不存在第二實體標記的第二目標文本,將所述第二目標文本加入至所述目標集合;
54、基于所述目標集合刪除所述標記數據集中的所述第二目標文本。
55、在一種可能的實施方式中,所述替換單元具體用于:
56、確定所述目標實體的實體類別和位置;
57、對確定實體類別一致,且實體實例一致的目標實體標記預設標簽;
58、基于所述預設標簽與替代項文本的第四對應關系,將所述目標實體替換為所述替代項文本,得到去標識化的數據集,其中,所述第四對應關系為預先設定的。
59、第三方面,本技術實施例還提供一種去標識化設備,包括至少一個處理器;以及與所述至少一個處理器通信連接的存儲器;其中,所述存儲器存儲有可被所述至少一個處理器執行的指令,所述指令被所述至少一個處理器執行,以使所述至少一個處理器能夠執行第一方面中任一項所述的方法。
60、本發明有益效果如下:
61、本技術提供一種去標識化方法、裝置及設備,本技術將獲取到的待處理數據集輸入至目標模型后,得到標記目標實體的數據集;基于預設的替代項文本對目標實體進行替換,得到去標識化的數據集;其中,目標模型是通過下列方式訓練得到的:基于iob標記法對目標數據集進行第一實體標記,得到第一標記數據集;基于正則表達式和第一實體標記,對標記數據集進行第二實體標記,得到第二標記數據集,并將第二標記數據集作為訓練集;基于訓練集對多個預訓練子模型進行訓練,在訓練后的子模型的精確率小于精確率閾值的情況下,返回至基于正則表達式和第一實體標記,對標記數據集進行第二實體標記的步驟,直至訓練后的子模型的精確率大于等于精確率閾值;在訓練后的子模型的精確率大于等于精確率閾值的情況下,確定子模型通過訓練,將通過訓練的多個子模型構成的模型作為目標模型。本技術通過對多個預訓練子模型分組進行訓練得到目標模型,從而實現目標實體識別的高準確率和高效率,進而實現去標識化的高準確率和高效率。
- 還沒有人留言評論。精彩留言會獲得點贊!