一種聲音在線監測系統超高速采集數據保存方法
本發明涉及智能監測,具體地說,涉及一種聲音在線監測系統超高速采集數據保存方法。
背景技術:
1、聲學檢測技術建立在對聲音產生、傳播和接收機制的深度理解之上,以此為依據對工業對象展開全面評估。系統通常由多個傳感器組成,能夠在不同頻率范圍內捕捉聲學信號,并通過先進的信號處理算法,對捕獲的數據進行分析。在聲紋監測系統中,聲音傳感器的采集頻率通常選擇在10khz到20khz之間,主要是為了捕捉聲紋特征的豐富細節和確保高質量的音頻數據。選擇10khz至20khz的采集頻率可以有效地覆蓋人耳能夠感知的頻率范圍,從而提高監測的準確性和靈敏度。此外,根據奈奎斯特定理,采樣頻率應至少是待檢測信號最高頻率的兩倍,確保在聲紋識別過程中,傳感器能夠準確捕獲到聲波中所有重要的頻率成分,進而提高聲紋匹配和故障檢測的精度。通過監測聲學特征,例如聲壓級、頻率成分及時間波形,可以識別出潛在的故障模式,如軸承磨損、齒輪失效或密封泄漏。與傳統的檢測方法相比,聲學檢測技術具有非侵入性和實時性的優勢,能夠在設備運行過程中持續監控,減少停機時間,提高生產效率。
2、但現有聲音監測系統普遍存在系統算力與采集速率不平衡的問題,一方面,采樣率過低使得系統難以捕捉到一些高頻信號特征,進而影響故障檢測的準確性;另一方面,若采樣率過高,連續記錄的數據將迅速占用大量磁盤空間,導致系統性能下降,甚至可能造成系統卡頓或崩潰。同時,狀態監測系統由于實時性的限制,無法做太多分析,導致聲音監測系統中難以取舍哪些信號該分析,哪些信號該儲存,哪些信號該忽略的問題。
3、鑒于此,我們提出一種聲音在線監測系統超高速采集數據保存方法,在滿足超高采樣速率的同時避免系統算力資源的浪費。通過設置有損耗的數據緩存區與雙重判斷機制,可以實現超高速的數據采集、分析與存儲。
技術實現思路
1、本發明的目的在于提供一種聲音在線監測系統超高速采集數據保存方法,以解決上述背景技術中提出的問題。
2、為實現上述技術問題的解決,本發明的目的在于,提供了一種聲音在線監測系統超高速采集數據保存方法,包括如下步驟:
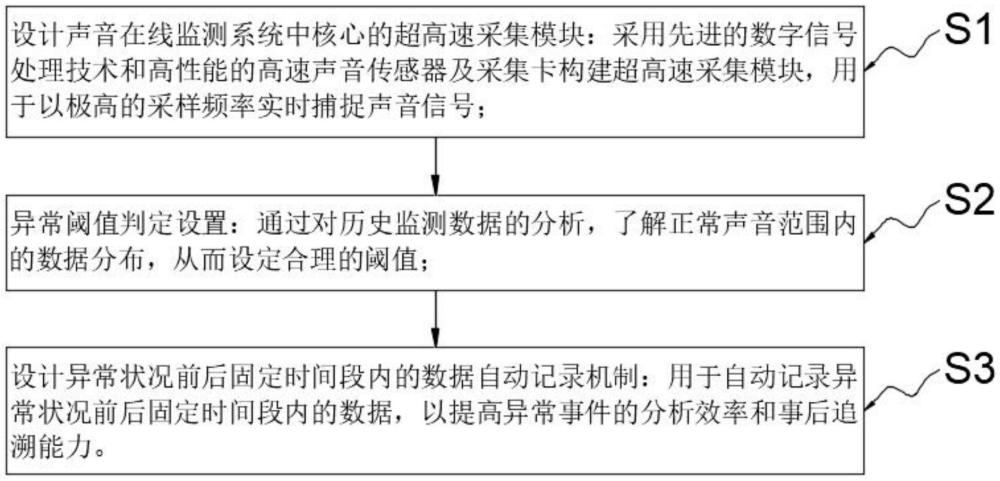
3、s1、設計聲音在線監測系統中核心的超高速采集模塊:采用先進的數字信號處理技術和高性能的高速聲音傳感器及采集卡構建超高速采集模塊,用于以極高的采樣頻率實時捕捉聲音信號;
4、s2、異常閾值判定設置:通過對歷史監測數據的分析,了解正常聲音范圍內的數據分布,從而設定合理的閾值;
5、s3、設計異常狀況前后固定時間段內的數據自動記錄機制:用于自動記錄異常狀況前后固定時間段內的數據,以提高異常事件的分析效率和事后追溯能力。
6、作為本技術方案的進一步改進,所述超高速采集模塊中:
7、高速聲音傳感器選擇:cry2110,其測量范圍為25~130dba,可采集頻率范圍10hz~20khz,以滿足超高速采集要求;
8、采集卡選擇:idaq-801,其通過4通道同步采樣256ks/s,且支持iepe供電。
9、作為本技術方案的進一步改進,所述s2具體包括如下步驟:
10、s2.1、數據收集:收集足夠數量的歷史聲音監測數據,并清理數據中的缺失值;數據量的大小取決于聲音變化的復雜程度和所需精度;數據量越大,模型越準確;
11、s2.2、閾值設定:基于統計分析結果設定初始閾值,并支持用戶自定義閾值設置。
12、作為本技術方案的進一步改進,所述s2.1中,清理數據中的缺失值利用混合改進的優化算法結合隨機森林算法彌補缺失值;混合改進的優化算法為結合灰狼優化算法與淘金者的優化算法;具體算法步驟如下:
13、s2.1.1、利用bernoulli映射減小灰狼算法中隨機初始種群對迭代的影響:
14、
15、式中,a為控制參數,其混沌軌道狀態值范圍為(0,1);xi表述第i次迭代時的灰狼位置、xi+1表示第i+1次迭代時的灰狼位置;
16、s2.1.2、在狩獵過程中,將種群包圍目標的行為定義如下:
17、x(τ+1)=xp(τ)-a·|c·xp(τ)-x(τ)|
18、式中,τ為迭代次數;xp(τ)為獵物位置,x(τ)為灰狼個體位置,x(τ+1)為包圍行動過程中灰狼個體后一次的位置,a、c均為系數向量,如下式表達:
19、
20、式中,r1、r2為[0,1]間的隨機數;a為收斂因子,在迭代過程中由2線性遞減到0;
21、s2.1.3、在對獵物進行圍捕后,β狼、δ狼和ω狼會在α狼的領導下,對獵物目標進行捕捉工作,灰狼個體追捕獵物位置的數學模型描述如下:
22、
23、式中,x1、x2、x3分別表示α狼、β狼、δ狼的位置更新方式,xα、xβ、xδ分別表示α狼、β狼、δ狼的當前位置,cα、cβ、cδ分別表示α狼、β狼、δ狼的系數向量,x表示ω狼的當前位置向量,x(t+1)為個體更新后的位置向量;
24、s2.1.4、灰狼的攻擊獵物過程即為算法的尋優過程,該過程通過收斂因子的遞減變化來完成,收斂因子的更新決定著尋優效果;
25、s2.1.5、通過上述算法尋找隨機森林算法中最大特征數與決策樹數量的最優組合。
26、作為本技術方案的進一步改進,所述s2.1.4中,引入淘金優化算法優化收斂因子,算法如下:
27、s2.1.4.1、借鑒淘金優化算法的參數:
28、
29、式中,l1是一個中間變量,用于在后續的算法步驟中參與對收斂因子或其他相關參數的調整,以影響算法的尋優行為;τ為迭代次數,τmax為最大迭代次數;
30、s2.1.4.2、改進收斂因子迭代方式:
31、
32、s2.1.4.3、在α狼的位置更新公式中引入淘金優化器:
33、
34、cα=2×r2
35、式中,r1、r2為[0,1]之間的隨機數;
36、s2.1.4.4、改進β狼的位置更新方式x2的計算公式:
37、i=round(1+r)
38、x2=xbest+r×(xbest-i×xi,j)
39、式中,r為[0,1]間的隨機數,xbest為最優位置,xi,j為當前位置;i為對進行取整操作獲得,為1或者2。
40、作為本技術方案的進一步改進,所述隨機森林算法彌補缺失值的算法包括:
41、決策樹是隨機森林聚類的基本構成要素,決策樹的每個葉節點對應一個分類,非葉節點對應著某個屬性上的劃分;隨機森林由很多決策樹構成且決策樹間沒有關聯;將數據輸入算法,隨機采樣數據生成多個訓練集,森林中的每棵決策樹就會對其進行判別和分類,得到多個分類結果,在分類結果中那個分類投票最多,那么這個分類結果就是最終的分類結果;
42、針對采集卡每一通道傳感器的數據,取歷史數據作為原始數據集,從中隨機選取n個數據作為訓練集,使用隨機森林算法建立n個預測模型,取其平均值作為最終的預測值;
43、對采集卡4個通道的預測值的準確性作判斷,一共有4n個預測模型,對于有4n個模型的隨機森林算法,相當于有4n棵樹,對任何一個樣本而言,平均或多數表決原則下,當且僅當有d棵以上的樹判斷錯誤的時候,錯誤可能性為:
44、
45、其中,erfc為錯誤可能性的值,i是判斷錯誤的次數,也就是判斷錯誤的樹的數量,ε是一棵樹判斷錯誤的概率,(1-ε)是判斷正確的概率。
46、作為本技術方案的進一步改進,所述s2.2中,初始閾值設置上下限兩個閾值,其中:
47、下限閾值為基于歷史數據的閾值,即以正常狀態下歷史數據庫均方根值的一定比值e為上下限浮動標準,當超過標準時提示一級警報;
48、上限閾值為基于自相關性的閾值,即以本時間段采集數據與上個時間段采集數據的自相關性為標準,當自相關性小于一定比值(1-e)時,提示一級警報;當兩者同時觸發時,提示二級警報;一級警報觸發開始保存該觸發時間前后的高速采集數據;
49、基于歷史數據的閾值設定如下:
50、
51、式中,xrms表示聲音信號有效值,n表示采樣數據點;
52、xmax=(1+e)xrms
53、xmin=(1-e)xrms
54、式中,xmax表示閾值上限,xmin表示閾值下限;
55、基于自相關性的閾值設定如下:
56、
57、式中,ρk為自相關系數,cov表示協方差,rt、rt-m分別表示本時間段采集的數據和上個時間段采集的數據,σ表示標準差,下標t和t-m表示本時間段和上個時間段。
58、作為本技術方案的進一步改進,所述s3具體包括如下步驟:
59、s3.1、異常前的數據存儲:通過結合隊列管理和條件結構,系統以觸發時間前后總計時長t為窗口,通過有損耗的入隊列機制,將最新的高速采集數據輸入緩存區,這樣一來,超過緩存容量的數據將自動替換最舊的數據,確保在異常發生前的重要信息不被遺失;
60、s3.2、異常后的數據存儲:利用閾值判斷結合條件結構,觸發閾值后運行若干次循環結束,保證了異常狀況后的數據存儲;
61、s3.3、雙重判斷機制:設定雙重判斷策略,先判斷閾值條件是否被一直觸發,避免在長時間異常的工況下高速數據一直保存,進而加大硬盤負荷;再通過雙重判斷策略,使得確保即使故障存在較長時間,系統也只記錄一次存儲操作,從而降低對存儲資源的需求,提高數據管理的效率和可靠性。
62、作為本技術方案的進一步改進,所述s3.3中,閾值條件被一直觸發的標準為:當前采集的實時數據一直處于預先設定的閾值范圍外,即當前采集的實時數據一直大于預設的閾值上限或一直小于預設的閾值下限。
63、作為本技術方案的進一步改進,所述s3.3中,雙重判斷策略為:
64、第一重:當前采集的實時數據處于預先設定的閾值范圍外;
65、第二重:當前采集的實時數據處于預先設定的閾值范圍外的持續時間在1s~3s內;
66、當上述雙重條件依次被觸發,則系統采集記錄一次異常數據;當處理完該異常后,持續時間歸零,再次異常則再次記錄,最大限度地保證硬盤空間的利用率。
67、與現有技術相比,本發明的有益效果:
68、1.該聲音在線監測系統超高速采集數據保存方法旨在在滿足超高采樣速率需求的同時,最大限度地避免系統算力資源的浪費;本方法通過設置有損耗的數據緩存區,并結合雙重判斷機制,實現了超高速的數據采集、分析與存儲;不僅提升了數據處理的效率,也確保了監測系統能夠在高負載情況下穩定運行;
69、2.該聲音在線監測系統超高速采集數據保存方法通過優化數據存儲策略,有效解決了傳統聲音監測系統在高速采集過程中的性能瓶頸,為工業故障檢測提供了一個更為可靠和高效的解決方案。
- 還沒有人留言評論。精彩留言會獲得點贊!