獲取HIP核函數基本塊調用關系的控制流圖表示方法及系統
所屬的技術人員能夠理解,本發明的各個方面可以實現為系統、方法或程序產品。因此,本發明的各個方面可以具體實現為以下形式,即:完全的硬件實施方式、完全的軟件實施方式(包括固件、微代碼等),或硬件和軟件方面結合的實施方式,這里可以統稱為“電路”、“模塊”或“平臺”。實施例2本發明提供一種獲取hip核函數基本塊調用關系的控制流圖表示系統,該系統能夠用于實現上述獲取hip核函數基本塊調用關系的控制流圖表示方法,具體的,該獲取hip核函數基本塊調用關系的控制流圖表示系統包括劃分模塊、遍歷模塊、函數模塊、調用模塊以及輸出模塊。其中,劃分模塊,提取hip程序的核函數,并將核函數編譯為llvm?ir中間代碼,llvm?ir中間代碼將核函數劃分為多個基本塊,每個基本塊內部包含一個有序的指令序列;遍歷模塊,遍歷劃分的基本塊,為每個基本塊分配唯一的序號,并保存各基本塊與其后繼基本塊的調用關系,向基本塊及其后繼的跳轉邊上插入一個表示調用關系的新基本塊,作為邊基本塊并分配唯一的序號;函數模塊,構建基本塊級的核函數控制流圖,核函數的每個原始基本塊都作為一個節點被添加到圖結構中,根據控制流關系向基本塊與其所有后繼基本塊之間添加有向邊,邊的方向表示程序執行流的方向;調用模塊,通過llvm插樁pass,對新加入的邊基本塊插入對計數函數的調用指令,得到插樁后的llvm?ir代碼,在后續執行時輸出原基本塊對其后繼基本塊的調用次數;輸出模塊,設計輕量化線程插樁模式,第一種只分析一個cta,第二種只分析一個wavefront;編譯并運行輕量化插樁后的llvm?ir中間代碼,得到基本塊之間的調用次數,收集每條邊的執行次數,并將得到的執行次數作為控制流圖cfg中邊的權重,生成一個帶有動態信息的、基本塊級的hip程序核函數控制流圖cfg。實施例3本發明提供了一種終端設備,該終端設備包括處理器以及存儲器,所述存儲器用于存儲計算機程序,所述計算機程序包括程序指令,所述處理器用于執行所述計算機存儲介質存儲的程序指令。處理器可能是中央處理單元(central?processing?unit,cpu),還可以是其他通用處理器、圖形處理器(graphics?processing?unit,gpu)、張量處理器(tensorprocessing?unit,tpu)、數字信號處理器(digital?signal?processor,dsp)、專用集成電路(application?specific?integrated?circuit,asic)、現場可編程門陣列(field-programmable?gate?array,fpga)或者其他可編程邏輯器件、分立門或者晶體管邏輯器件、分立硬件組件等,其是終端的計算核心以及控制核心,其適于實現一條或一條以上指令,具體適于加載并執行一條或一條以上指令從而實現相應方法流程或相應功能;本發明實施例所述的處理器可以用于獲取hip核函數基本塊調用關系的控制流圖表示方法的操作,包括:提取hip程序的核函數,并將核函數編譯為llvm?ir中間代碼,llvm?ir中間代碼將核函數劃分為多個基本塊,每個基本塊內部包含一個有序的指令序列;遍歷劃分的基本塊,為每個基本塊分配唯一的序號,并保存各基本塊與其后繼基本塊的調用關系,向基本塊及其后繼的跳轉邊上插入一個表示調用關系的新基本塊,作為邊基本塊并分配唯一的序號;構建基本塊級的核函數控制流圖,核函數的每個原始基本塊都作為一個節點被添加到圖結構中,根據控制流關系向基本塊與其所有后繼基本塊之間添加有向邊,邊的方向表示程序執行流的方向;通過llvm插樁pass,對新加入的邊基本塊插入對計數函數的調用指令,得到插樁后的llvm?ir代碼,在后續執行時輸出原基本塊對其后繼基本塊的調用次數;設計輕量化線程插樁模式,第一種只分析一個cta,第二種只分析一個wavefront;編譯并運行輕量化插樁后的llvm?ir中間代碼,得到基本塊之間的調用次數,收集每條邊的執行次數,并將得到的執行次數作為控制流圖cfg中邊的權重,生成一個帶有動態信息的、基本塊級的hip程序核函數控制流圖cfg。請參閱圖5,終端設備為計算機設備,該實施例的計算機設備60包括:處理器61、存儲器62以及存儲在存儲器62中并可在處理器61上運行的計算機程序63,該計算機程序63被處理器61執行時實現實施例中的獲取hip核函數基本塊調用關系的控制流圖表示方法,為避免重復,此處不一一贅述。或者,該計算機程序63被處理器61執行時實現實施例獲取hip核函數基本塊調用關系的控制流圖表示系統中各模型/單元的功能,為避免重復,此處不一一贅述。計算機設備60可以是桌上型計算機、筆記本、掌上電腦及云端服務器等計算設備。計算機設備60可包括,但不僅限于,處理器61、存儲器62。本領域技術人員可以理解,圖5僅僅是計算機設備60的示例,并不構成對計算機設備60的限定,可以包括比圖示更多或更少的部件,或者組合某些部件,或者不同的部件,例如計算機設備還可以包括輸入輸出設備、網絡接入設備、總線等。所稱處理器61可以是中央處理單元(central?processing?unit,cpu),還可以是其它通用處理器、圖形處理器(graphics?processing?unit,gpu)、張量處理器(tensorprocessing?unit,tpu)、數字信號處理器(digital?signal?processor,dsp)、專用集成電路(application?specific?integrated?circuit,asic)、現場可編程門陣列(field-programmable?gate?array,fpga)或者其它可編程邏輯器件、分立門或者晶體管邏輯器件、分立硬件組件等。通用處理器可以是微處理器或者該處理器也可以是任何常規的處理器等。存儲器62可以是計算機設備60的內部存儲單元,例如計算機設備60的硬盤或內存。存儲器62也可以是計算機設備60的外部存儲設備,例如計算機設備60上配備的插接式硬盤,智能存儲卡(smart?media?card,smc),安全數字(secure?digital,sd)卡,閃存卡(flash?card)等。進一步地,存儲器62還可以既包括計算機設備60的內部存儲單元也包括外部存儲設備。存儲器62用于存儲計算機程序以及計算機設備所需的其它程序和數據。存儲器62還可以用于暫時地存儲已經輸出或者將要輸出的數據。請參閱圖6,終端設備為電子設備600,電子設備600以通用計算設備的形式表現。電子設備的組件可以包括但不限于:至少一個處理單元610、至少一個存儲單元620、連接不同平臺組件(包括存儲單元620和處理單元610)的總線630、顯示單元640等。其中,存儲單元存儲有程序代碼,程序代碼可以被處理單元610執行,使得處理單元610執行本說明書上述方法部分中描述的根據本發明各種示例性實施方式的步驟。例如,處理單元610可以執行如圖1中所示的步驟。存儲單元620可以包括易失性存儲單元形式的可讀介質,例如隨機存取存儲單元(ram)6201和/或高速緩存存儲單元6202,還可以進一步包括只讀存儲單元(rom)6203。存儲單元620還可以包括具有一組(至少一個)程序模塊6205的程序/實用工具6204,這樣的程序模塊6205包括但不限于:操作系統、一個或者多個應用程序、其它程序模塊以及程序數據,這些示例中的每一個或某種組合中可能包括網絡環境的實現。總線630可以為表示幾類總線結構中的一種或多種,包括存儲單元總線或者存儲單元控制器、外圍總線、圖形加速端口、處理單元或者使用多種總線結構中的任一總線結構的局域總線。電子設備600也可以與一個或多個外部設備700(例如鍵盤、指向設備、藍牙設備等)通信,還可與一個或者多個使得用戶能與該電子設備600交互的設備通信,和/或與使得該電子設備600能與一個或多個其它計算設備進行通信的任何設備(例如路由器、調制解調器等等)通信。這種通信可以通過輸入/輸出接口650進行。并且,電子設備600還可以通過網絡適配器660與一個或者多個網絡(例如局域網,廣域網和/或公共網絡,例如因特網)通信。網絡適配器660可以通過總線630與電子設備600的其它模塊通信。應當明白,盡管圖中未示出,可以結合電子設備600使用其它硬件和/或軟件模塊,包括但不限于:微代碼、設備驅動器、冗余處理單元、外部磁盤驅動陣列、raid系統、磁帶驅動器以及數據備份存儲平臺等。實施例4本發明還提供了一種存儲介質,具體為計算機可讀存儲介質,所述計算機可讀存儲介質是終端設備中的記憶設備,用于存放程序和數據。可以理解的是,此處的計算機可讀存儲介質既可以包括終端設備中的內置存儲介質,當然也可以包括終端設備所支持的擴展存儲介質,可以是任何包含或存儲程序的有形介質,該程序可以被指令執行系統、裝置或者器件使用或者與其結合使用。計算機可讀存儲介質提供存儲空間,該存儲空間存儲了終端的操作系統。并且,在該存儲空間中還存放了適于被處理器加載并執行的一條或一條以上的指令,這些指令可以是一個或一個以上的計算機程序(包括程序代碼)。需要說明的是,此處的計算機可讀存儲介質的更具體的例子包括:具有一個或多個導線的電連接、便攜式盤、硬盤、隨機存取存儲器、只讀存儲器、可擦式可編程只讀存儲器、光纖、便攜式緊湊盤只讀存儲器、光存儲器件、磁存儲器件、或者上述的任一合適的組合。計算機可讀存儲介質還包括在基帶中或者作為載波一部分傳播的數據信號,其中承載了可讀程序代碼。這種傳播的數據信號可以采用多種形式,包括但不限于電磁信號、光信號或上述的任一合適的組合。可讀存儲介質還可以是可讀存儲介質以外的任何可讀介質,該可讀介質可以發送、傳播或者傳輸用于由指令執行系統、裝置或者器件使用或者與其結合使用的程序。可讀存儲介質上包含的程序代碼可以用任何適當的介質傳輸,包括但不限于無線、有線、光纜、射頻等等,或者上述的任一合適的組合。可以以一種或多種程序設計語言的任一組合來編寫用于執行本發明操作的程序代碼,程序設計語言包括面向對象的程序設計語言—諸如java、c++等,還包括常規的過程式程序設計語言—諸如“c”語言或類似的程序設計語言。程序代碼可以完全地在用戶計算設備上執行、部分地在用戶設備上執行、作為一個獨立的軟件包執行、部分在用戶計算設備上部分在遠程計算設備上執行、或者完全在遠程計算設備或服務器上執行。在涉及遠程計算設備的情形中,遠程計算設備可以通過任一種類的網絡,包括局域網或廣域網,連接到用戶計算設備,或者,可以連接到外部計算設備(例如利用因特網服務提供商來通過因特網連接)。可由處理器加載并執行計算機可讀存儲介質中存放的一條或一條以上指令,以實現上述實施例中有關獲取hip核函數基本塊調用關系的控制流圖表示方法的相應步驟;計算機可讀存儲介質中的一條或一條以上指令由處理器加載并執行如下步驟:提取hip程序的核函數,并將核函數編譯為llvm?ir中間代碼,llvm?ir中間代碼將核函數劃分為多個基本塊,每個基本塊內部包含一個有序的指令序列;遍歷劃分的基本塊,為每個基本塊分配唯一的序號,并保存各基本塊與其后繼基本塊的調用關系,向基本塊及其后繼的跳轉邊上插入一個表示調用關系的新基本塊,作為邊基本塊并分配唯一的序號;構建基本塊級的核函數控制流圖,核函數的每個原始基本塊都作為一個節點被添加到圖結構中,根據控制流關系向基本塊與其所有后繼基本塊之間添加有向邊,邊的方向表示程序執行流的方向;通過llvm插樁pass,對新加入的邊基本塊插入對計數函數的調用指令,得到插樁后的llvm?ir代碼,在后續執行時輸出原基本塊對其后繼基本塊的調用次數;設計輕量化線程插樁模式,第一種只分析一個cta,第二種只分析一個wavefront;編譯并運行輕量化插樁后的llvm?ir中間代碼,得到基本塊之間的調用次數,收集每條邊的執行次數,并將得到的執行次數作為控制流圖cfg中邊的權重,生成一個帶有動態信息的、基本塊級的hip程序核函數控制流圖cfg。為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。通常在此處附圖中的描述和所示的本發明實施例的組件可以通過各種不同的配置來布置和設計。因此,以下對在附圖中提供的本發明的實施例的詳細描述并非旨在限制要求保護的本發明的范圍,而是僅僅表示本發明的選定實施例。基于本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明保護的范圍。通過對國產dcu平臺上運行的hip程序進行輕量化插樁分析,構建一個帶有動態信息的基本塊級控制流圖(cfg)。此實驗將分為多個步驟,涉及llvm?ir中間代碼的編譯、基本塊的劃分、邊基本塊插樁、執行動態分析等環節。step1:獲取hip程序并轉化為llvm?ir獲取hip程序:獲取目標國產dcu平臺上的hip程序,程序包括主機端代碼與設備端代碼。使用hipcc編譯器:使用hipcc編譯器將hip程序的設備端核函數提取并轉化為llvm?ir中間代碼,確保該中間代碼無關硬件架構,以便后續分析。基本塊劃分:通過編譯生成的llvm?ir代碼,提取核函數,劃分出各個基本塊。每個基本塊將被唯一編號(block?1,?block?2,...)。step2:生成基本塊調用關系保存調用關系:遍歷所有基本塊,記錄每個基本塊及其所有后繼基本塊的調用關系。調用關系為基本塊控制流之間的跳轉路徑。插入邊基本塊:針對每對基本塊及其后繼基本塊的跳轉關系,插入新創建的邊基本塊。為每個新插入的邊基本塊分配唯一編號(edge1_2)。插樁輕量化:在新插入的邊基本塊中插入對計數函數的調用指令,用于記錄基本塊之間的跳轉次數。step3:構建控制流圖(cfg)構建圖結構:將所有原始基本塊作為節點添加到控制流圖中,保存每個基本塊的指令序列。添加有向邊:根據記錄的基本塊調用關系,為每對基本塊之間添加有向邊。邊的方向表示程序的執行流,形成完整的控制流。處理循環和回環:如果程序存在循環,確保在圖中處理回環路徑,正確反映基本塊的執行順序。step4:插樁llvm?ir插入計數函數:對新插入的邊基本塊進行輕量化插樁,插入計數函數的調用,跟蹤基本塊執行次數。生成插樁后的llvm?ir:最終生成的llvm?ir代碼將包括計數函數調用指令,這將用于跟蹤每個邊基本塊的調用次數。step5:輕量化線程插樁模式profilecta:僅對一個線程塊(cta)進行插樁,選取網格中心位置的線程塊進行分析。這種方式平衡了開銷與準確性。profilewavefront:僅分析一個wavefront,選取線程塊中wavefront內的中心線程進行插樁分析,減少插樁開銷。通過公式計算,使用不同的插樁模式(profilecta?或?profilewavefront)來計算基本塊與其后繼基本塊的調用次數。step6:執行與收集動態信息執行插樁后的代碼:編譯并運行插樁后的llvm?ir代碼,收集各基本塊之間的執行次數。構建帶動態信息的控制流圖:根據收集到的動態執行數據(調用次數),更新控制流圖的邊權重,生成最終的帶動態信息的基本塊級控制流圖。仿真實驗數據分析與結果展示控制流圖的可視化:通過圖形化工具展示基本塊級控制流圖。每個基本塊作為節點,連接的有向邊表示控制流的方向,邊的權重表示執行次數。通過對比不同插樁模式下的開銷與準確性,優化插樁策略,選擇最適合的分析方法。通過對hip程序進行動態分析,構建帶有動態信息的控制流圖,并通過輕量化插樁降低性能開銷。通過對每個基本塊和后繼基本塊之間的控制流分析,結合不同的插樁模式,獲得精確的執行信息,進而優化核函數的執行效率。綜上所述,本發明一種獲取hip核函數基本塊調用關系的控制流圖表示方法及系統,通過輕量化插樁分析獲取基本塊間動態調用次數,并將其作為控制流圖的邊權,生成帶有動態信息的基本塊級cfg,精確反映程序的動態行為,為性能建模提供了準確依據,有效識別性能瓶頸和熱點區域。本發明設計了兩種輕量化插樁模式(profilecta和profilewavefront),同時僅對新插入的邊基本塊進行插樁,顯著降低了插樁開銷。結合國產dcu平臺的設備端與主機端插樁流程,利用hipcc、opt等工具優化編譯和插樁過程,提高了性能數據采集效率。本發明通過基本塊級的圖表示降低了圖規模和內存占用,提高了圖處理效率,適用于超算平臺上的大規模并行計算任務,為后續的程序性能建模與分析提供了高效支持。所屬領域的技術人員可以清楚地了解到,為了描述的方便和簡潔,僅以上述各功能單元、模塊的劃分進行舉例說明,實際應用中,可以根據需要而將上述功能分配由不同的功能單元、模塊完成,即將所述裝置的內部結構劃分成不同的功能單元或模塊,以完成以上描述的全部或者部分功能。實施例中的各功能單元、模塊可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中,上述集成的單元既可以采用硬件的形式實現,也可以采用軟件功能單元的形式實現。另外,各功能單元、模塊的具體名稱也只是為了便于相互區分,并不用于限制本技術的保護范圍。上述系統中單元、模塊的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。在上述實施例中,對各個實施例的描述都各有側重,某個實施例中沒有詳述或記載的部分,可以參見其它實施例的相關描述。本領域普通技術人員可以意識到,結合本發明中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬件、或者計算機軟件和電子硬件的結合來實現。這些功能究竟以硬件還是軟件方式來執行,取決于技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的范圍。在本發明所提供的實施例中,應該理解到,所揭露的裝置/終端和方法,可以通過其它的方式實現。例如,以上所描述的裝置/終端實施例僅僅是示意性的,例如,所述模塊或單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通訊連接可以是通過一些接口,裝置或單元的間接耦合或通訊連接,可以是電性,機械或其它的形式。所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以采用硬件的形式實現,也可以采用軟件功能單元的形式實現。所述集成的模塊/單元如果以軟件功能單元的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明實現上述實施例方法中的全部或部分流程,也可以通過計算機程序來指令相關的硬件來完成,所述的計算機程序可存儲于一計算機可讀存儲介質中,該計算機程序在被處理器執行時,可實現上述各個方法實施例的步驟。其中,所述計算機程序包括計算機程序代碼,所述計算機程序代碼可以為源代碼形式、對象代碼形式、可執行文件或某些中間形式等。所述計算機可讀介質可以包括:能夠攜帶所述計算機程序代碼的任何實體或裝置、記錄介質、u盤、移動硬盤、磁碟、光盤、計算機存儲器、只讀存儲器(read-only?memory,rom)、隨機存取存儲器(random-access?memory,ram)、電載波信號、電信信號以及軟件分發介質等,需要說明的是,所述計算機可讀介質包含的內容可以根據司法管轄區內立法和專利實踐的要求進行適當的增減,例如在某些司法管轄區,根據立法和專利實踐,計算機可讀介質不包括是電載波信號和電信信號。本技術是參照根據本技術實施例的方法、設備、和計算機程序產品的流程圖和/或方框圖來描述的。應理解可由計算機程序指令實現流程圖和/或方框圖中的每一流程和/或方框、以及流程圖和/或方框圖中的流程和/或方框的結合。可提供這些計算機程序指令到通用計算機、專用計算機、嵌入式處理機或其他可編程數據處理設備的處理器以產生一個機器,使得通過計算機或其他可編程數據處理設備的處理器執行的指令產生用于實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的裝置。這些計算機程序指令也可存儲在能引導計算機或其他可編程數據處理設備以特定方式工作的計算機可讀存儲器中,使得存儲在該計算機可讀存儲器中的指令產生包括指令裝置的制造品,該指令裝置實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能。這些計算機程序指令也可裝載到計算機或其他可編程數據處理設備上,使得在計算機或其他可編程設備上執行一系列操作步驟以產生計算機實現的處理,從而在計算機或其他可編程設備上執行的指令提供用于實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的步驟。以上內容僅為說明本發明的技術思想,不能以此限定本發明的保護范圍,凡是按照本發明提出的技術思想,在技術方案基礎上所做的任何改動,均落入本發明權利要求書的保護范圍之內。
背景技術:
1、在高性能計算(hpc)領域,性能建模是優化和提升計算系統效率的關鍵技術。特別是在超算平臺上,如何精確預測程序的執行時間,以便合理分配計算資源,是性能建模的核心任務之一。hip作為一種跨平臺的編程模型,廣泛應用于gpu計算。由于hip程序在國產dcu平臺上運行效率最高且使用廣泛,因此選擇對hip程序構建性能模型。
2、控制流圖(cfg)是程序分析中常用的圖模型,通過節點和邊的關系直觀地表示程序的控制流結構。這種圖模型能夠有效抽象并簡化程序的執行流程,從而為后續的程序性能建模與分析提供支持。通過將hip程序表示為圖結構進行動態分析,能夠清晰捕捉程序中復雜的控制流關系,進而深入識別性能瓶頸、內存訪問模式以及控制流中的熱點區域,為后續的性能優化和改進提供科學依據。
3、傳統的靜態程序分析主要側重于代碼結構和潛在優化機會的識別,但無法充分反映程序在運行時的動態行為。因此,靜態分析方法存在一定的局限性,且在準確性和精度方面較為不足。
4、目前,大多數研究集中于nvidia?gpu平臺的性能優化,采用cuda編程模型,通過ptx中間代碼進行性能建模。這些方法通常具有較強的平臺依賴特性。然而,hip程序無法直接轉換為ptx中間代碼,這使得在該編程模型上進行性能建模面臨較大挑戰。
5、此外,盡管許多插樁分析方法在gpu上取得了一定的成功,但它們通常依賴于復雜且全面的插樁技術,導致較高的存儲開銷和計算成本。
6、在現有的llvm?ir圖表示的工具中,如programl等構建的是基于指令級別的靜態圖,這種方法生成的圖結構較大,處理速度較慢并且占用較多內存資源。
技術實現思路
1、本發明所要解決的技術問題在于針對上述現有技術中的不足,提供一種獲取hip核函數基本塊調用關系的控制流圖表示方法及系統,用于解決現有方法無法準確捕捉hip程序動態行為、生成高效且輕量化的控制流圖以及為后續適配國產dcu平臺進行性能建模的技術問題。
2、本發明采用以下技術方案:
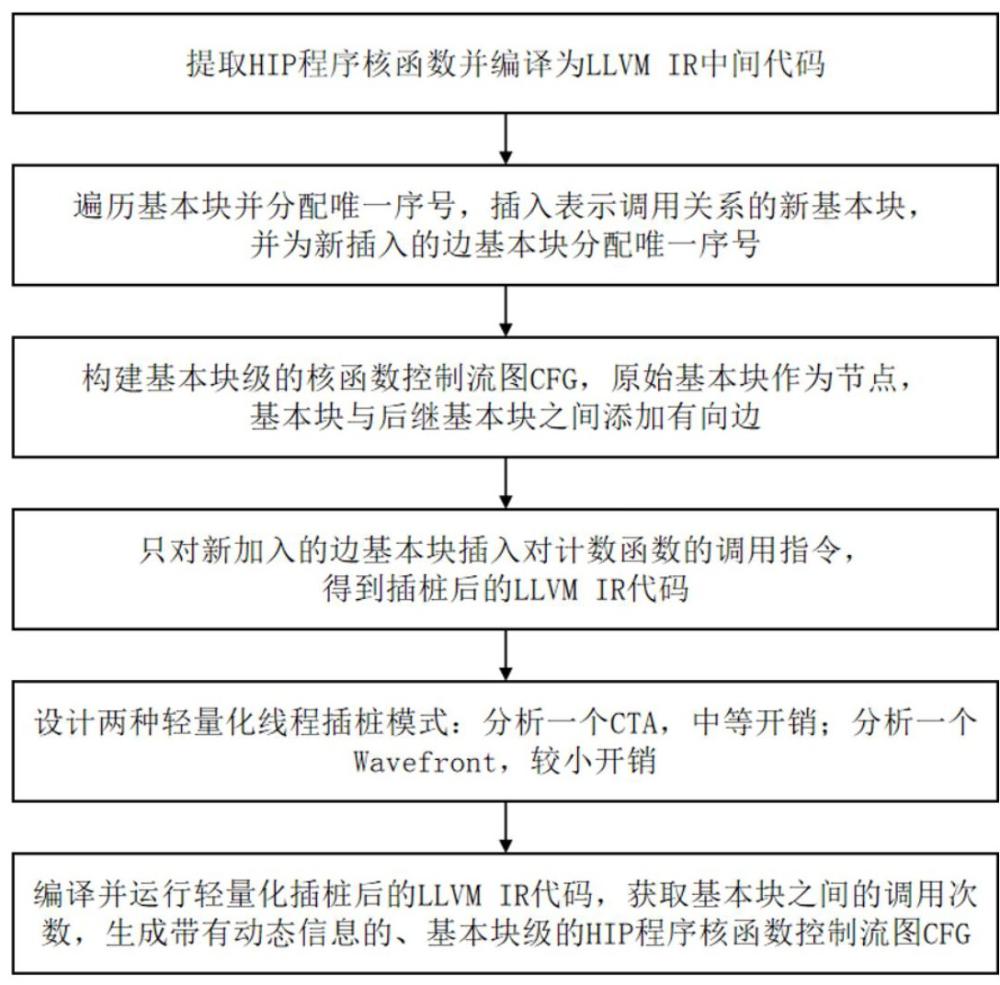
3、獲取hip核函數基本塊調用關系的控制流圖表示方法,包括以下步驟:
4、s1、提取hip程序的核函數,并將核函數編譯為llvm?ir中間代碼,llvm?ir中間代碼將核函數劃分為多個基本塊,每個基本塊內部包含一個有序的指令序列;
5、s2、遍歷劃分的基本塊,為每個基本塊分配唯一的序號,并保存各基本塊與其后繼基本塊的調用關系,向基本塊及其后繼的跳轉邊上插入一個表示調用關系的新基本塊,作為邊基本塊并分配唯一的序號;
6、s3、構建基本塊級的核函數控制流圖,核函數的每個原始基本塊都作為一個節點被添加到圖結構中,根據控制流關系向基本塊與其所有后繼基本塊之間添加有向邊,邊的方向表示程序執行流的方向;
7、s4、通過llvm插樁pass,對新加入的邊基本塊插入對計數函數的調用指令,得到插樁后的llvm?ir代碼,在后續執行時輸出原基本塊對其后繼基本塊的調用次數;
8、s5、設計輕量化線程插樁模式,第一種只分析一個cta,第二種只分析一個wavefront;
9、s6、編譯并運行輕量化插樁后的llvm?ir中間代碼,得到基本塊之間的調用次數,收集每條邊的執行次數,并將得到的執行次數作為控制流圖cfg中邊的權重,生成一個帶有動態信息的、基本塊級的hip程序核函數控制流圖cfg。
10、優選地,步驟s2具體為:
11、s201、遍歷hip程序核函數llvm?ir代碼中的所有基本塊,為每個基本塊分配唯一的序號,從而區分原基本塊與后續新加入的邊基本塊;
12、s202、保存各基本塊與其所有后繼基本塊的調用關系;
13、s203、向基本塊及其后繼基本塊的跳轉邊上插入新的基本塊表示調用關系,被稱為邊基本塊,并為每個新插入的邊基本塊分配唯一的序號;
14、s204、遍歷每個新插入的邊基本塊,只對邊基本塊插入計數函數調用指令,在插樁程序后續執行時,得到基本塊之間的調用關系與調用次數。
15、優選地,將原始基本塊依次命名為block?1、block?2至block?n;每個新插入的邊基本塊分配一個唯一的序號,將邊基本塊依次命名為edgei_j,表示在原基本塊block?i和其后繼基本塊block?j的跳轉邊上新插入的邊基本塊。
16、優選地,步驟s3的控制流圖中,每個原始基本塊作為一個圖節點,每個圖節點以基本塊的唯一序號作為標識符;添加有向邊時,如果基本塊存在多個后繼基本塊,則為每對基本塊之間添加單獨的有向邊,形成完整分支結構;如果基本塊的后繼中包含自身或某前驅路徑回到該基本塊,形成環狀結構。
17、優選地,步驟s4具體為:
18、s401、提取出原ir代碼的設備端核函數及其各類信息,克隆設備端核函數并添加基本塊列表、bank數量和插樁粒度;
19、s402、根據步驟s2得到插入邊基本塊后的llvm?ir代碼;
20、s403、遍歷所有的邊基本塊,并在每個邊基本塊的開頭插入計數函數調用語句;
21、s404、生成插樁后的llvm?ir代碼,實現對邊基本塊的輕量化插樁計數。
22、優選地,步驟s403中,計數函數包括存儲各基本塊計數結果的計數器、邊基本塊的序號、bank數量和插樁粒度。
23、優選地,步驟s5中,輕量化線程插樁模式包括:
24、profilecta:僅對一個線程塊cta進行插樁分析,選取線程塊網格中心位置的線程塊;
25、profilewavefront:分析一個wavefront,選取中心位置線程塊的中心wavefront內的所有線程進行插樁分析。
26、優選地,基本塊對其后繼基本塊的調用次數定義如下:
27、
28、其中,表示網格大小,表示在原基本塊i和其后繼基本塊j的跳轉邊上新插入的邊基本塊,表示邊基本塊中計數函數的計數大小,表示線程塊大小,是加速器調度并執行的最小線程數量,表示采用profilecta線程插樁模式,表示采用profilewavefront線程插樁模式。
29、優選地,步驟s6具體為:
30、s601、將國產dcu平臺上運行的hip程序通過hipcc編譯器生成設備端的llvm?ir文件,通過opt工具生成插樁后的設備端ir文件,再通過llvm-link工具鏈接插樁后的設備端ir文件和設備端運行時文件;
31、s602、經過國產dcu的編譯器dcc、鏈接器ld.lld和clang-bundle編譯成設備端二進制文件hipfb,以供主機端調用;
32、s603、主機端代碼必須使用dcc編譯,通過-fcuda-include-gpubinary參數,將設備端代碼加入到主機端llvm?ir文件中;
33、s604、再執行與設備端相同的流程,得到設備端插樁和主機端插樁后的總體llvmir文件,通過編譯器dcc和鏈接器ld完成編譯;
34、s605、遍歷hip程序核函數的每個原基本塊,將原基本塊作為節點添加到圖結構中;
35、s606、根據控制流關系,向基本塊與其所有后繼基本塊之間添加有向邊,邊的方向表示程序執行流的方向;
36、s607、收集每個新加入的邊基本塊內的計數大小,根據設置的線程插樁模式,得到基本塊之間的調用次數;
37、s608、將基本塊對其后繼基本塊的調用次數作為動態信息加入cfg中,作為邊的權重,生成最終的hip程序核函數控制流圖。
38、第二方面,本發明實施例提供了獲取hip核函數基本塊調用關系的控制流圖表示系統,包括:
39、劃分模塊,提取hip程序的核函數,并將核函數編譯為llvm?ir中間代碼,llvm?ir中間代碼將核函數劃分為多個基本塊,每個基本塊內部包含一個有序的指令序列;
40、遍歷模塊,遍歷劃分的基本塊,為每個基本塊分配唯一的序號,并保存各基本塊與其后繼基本塊的調用關系,向基本塊及其后繼的跳轉邊上插入一個表示調用關系的新基本塊,作為邊基本塊并分配唯一的序號;
41、函數模塊,構建基本塊級的核函數控制流圖,核函數的每個原始基本塊都作為一個節點被添加到圖結構中,根據控制流關系向基本塊與其所有后繼基本塊之間添加有向邊,邊的方向表示程序執行流的方向;
42、調用模塊,通過llvm插樁pass,對新加入的邊基本塊插入對計數函數的調用指令,得到插樁后的llvm?ir代碼,在后續執行時輸出原基本塊對其后繼基本塊的調用次數;
43、輸出模塊,設計輕量化線程插樁模式,第一種只分析一個cta,第二種只分析一個wavefront;編譯并運行輕量化插樁后的llvm?ir中間代碼,得到基本塊之間的調用次數,收集每條邊的執行次數,并將得到的執行次數作為控制流圖cfg中邊的權重,生成一個帶有動態信息的、基本塊級的hip程序核函數控制流圖cfg。
44、第三方面,一種計算機設備,包括存儲器、處理器以及存儲在所述存儲器中并可在所述處理器上運行的計算機程序,所述處理器執行所述計算機程序時實現上述獲取hip核函數基本塊調用關系的控制流圖表示方法的步驟。
45、第四方面,本發明實施例提供了一種計算機可讀存儲介質,包括計算機程序,所述計算機程序被處理器執行時實現上述獲取hip核函數基本塊調用關系的控制流圖表示方法的步驟。
46、第五方面,一種芯片,包括存儲器、處理器以及存儲在所述存儲器中并可在所述處理器上運行的計算機程序,所述處理器執行所述計算機程序時實現上述獲取hip核函數基本塊調用關系的控制流圖表示方法的步驟。
47、第六方面,本發明實施例提供了一種電子設備,包括計算機程序,所述計算機程序被電子設備執行時實現上述獲取hip核函數基本塊調用關系的控制流圖表示方法的步驟。
48、與現有技術相比,本發明至少具有以下有益效果:
49、獲取hip核函數基本塊調用關系的控制流圖表示方法,通過輕量化插樁分析獲得的動態調用次數作為邊的權重,生成一個帶有動態信息的、基本塊級的hip程序核函數cfg,使得控制流圖不僅反映程序的靜態結構,還能夠反映程序在執行過程中的實際動態行為。相比傳統的靜態分析方法,能夠更加準確地捕捉程序的實際執行情況,為后續的性能建模提供了更加準確的依據,能夠更有效地識別性能瓶頸和熱點區域,通過在國產dcu平臺上同時對設備端和主機端進行插樁,并結合hipcc、opt、llvm-link、dcc等工具,精簡了整體編譯與插樁流程。該流程不僅保證了設備端與主機端性能數據的同步性,還提高了整個性能建模與優化過程的效率,適用于大規模并行計算任務,特別是在高性能計算平臺上,通過基本塊級的控制流圖表示方法,顯著減少了圖結構的規模,降低了內存占用并提高了圖處理速度。這使得本發明能夠在大規模計算任務中,尤其是在超算平臺上,提供更高的效率和更低的資源消耗。
50、進一步的,相比programl等傳統的基于指令級別的靜態圖分析方法,本發明設計了一種基于基本塊級的控制流圖表示方法,將圖結構規模縮小了十倍以上,大幅降低了內存占用,同時顯著提升了圖處理速度。這使得本發明在大規模計算任務中,尤其是在超算平臺上,能夠提供更高的效率和更低的資源消耗。
51、進一步的,通過構建基本塊級控制流圖,以唯一序號標識節點,并精細添加有向邊,完整描述分支和循環結構。該設計減少了圖結構的規模和冗余,降低了內存占用和計算成本,為性能建模提供了精準數據基礎。
52、進一步的,設計了兩種輕量化線程插樁模式(profilecta和profilewavefront),有效減少了插樁過程中的存儲和計算開銷。同時,只對新插入的邊基本塊進行插樁,進一步降低了插樁分析帶來的額外計算開銷。與傳統全分析方法相比,采用這些模式能夠在不犧牲分析精度的前提下,顯著降低性能分析的額外成本,在高并發計算任務中尤為重要。
53、進一步的,本發明提出了一種插樁方法,在國產dcu平臺上同時對設備端和主機端進行插樁,并結合hipcc、opt、llvm-link、dcc等工具,精簡并封裝了整體的編譯與插樁流程。該方法不僅確保了設備端與主機端性能數據的同步,還顯著提升了性能建模與優化過程的效率。
54、可以理解的是,上述第二方面的有益效果可以參見上述第一方面中的相關描述,在此不再贅述。
55、綜上所述,本發明有效降低了插樁開銷,提高了動態調用關系的獲取效率,為高性能計算和程序優化提供了有力支持。
56、下面通過附圖和實施例,對本發明的技術方案做進一步的詳細描述。
- 還沒有人留言評論。精彩留言會獲得點贊!