基于跨模型泛化和擴散模型的數據集蒸餾方法和裝置
本公開涉及計算機,具體涉及一種基于跨模型泛化和擴散模型的數據集蒸餾方法、裝置、電子設備和存儲介質。
背景技術:
1、數據集蒸餾是一種數據集濃縮技術,其目的是將一個擁有n個樣本的目標數據集t,濃縮成擁有m個樣本的替代數據集s(m遠小于n,且m個樣本一般是不同于n個樣本的新樣本)。替代數據集s可以用于深度學習模型訓練,且其訓練成本遠低于目標數據集t,進一步的,基于s訓練得到的模型性能和基于t訓練得到的模型性能基本相當。
2、然而,相關技術中的數據集蒸餾方法無法兼顧數據集蒸餾的優異性能和不同結構模型的良好泛化能力。
技術實現思路
1、本公開示例性實施例提供的基于跨模型泛化和擴散模型的數據集蒸餾方法、裝置、電子設備和存儲介質,可以至少解決上述技術問題和上文未提及的其它技術問題。
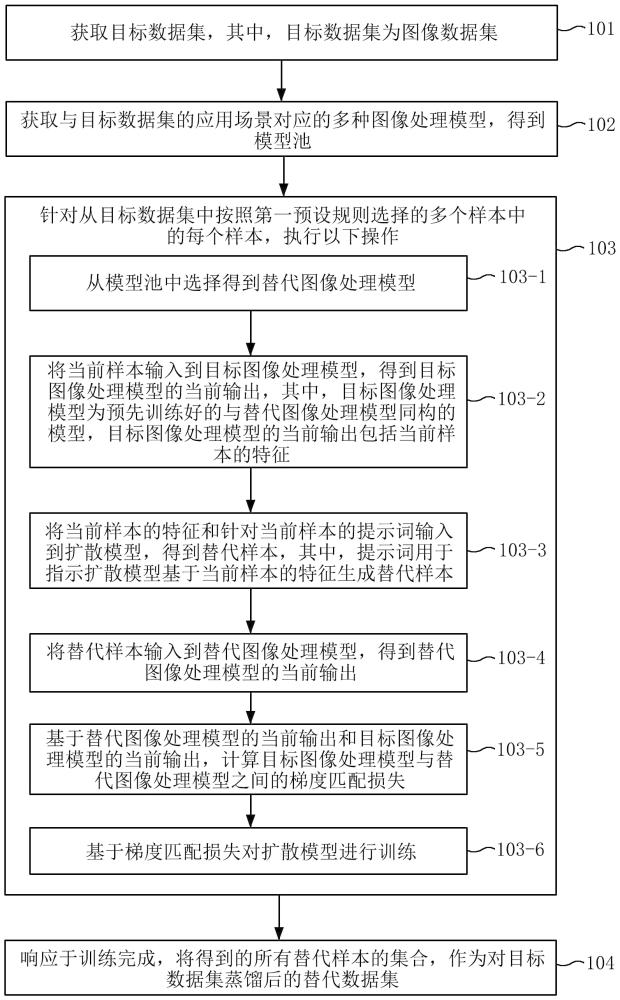
2、根據本公開的一個方面,提供一種基于跨模型泛化和擴散模型的數據集蒸餾方法,所述方法包括:獲取目標數據集,其中,所述目標數據集為圖像數據集;獲取與所述目標數據集的應用場景對應的多種圖像處理模型,得到模型池;針對從所述目標數據集中按照第一預設規則選擇的多個樣本中的每個樣本,執行以下操作:從所述模型池中選擇得到替代圖像處理模型;將所述當前樣本輸入到目標圖像處理模型,得到所述目標圖像處理模型的當前輸出,其中,所述目標圖像處理模型為預先訓練好的與所述替代圖像處理模型同構的模型,所述目標圖像處理模型的當前輸出包括所述當前樣本的特征;將所述當前樣本的特征和針對所述當前樣本的提示詞輸入到擴散模型,得到替代樣本,其中,所述提示詞用于指示所述擴散模型基于所述當前樣本的特征生成所述替代樣本;將所述替代樣本輸入到所述替代圖像處理模型,得到所述替代圖像處理模型的當前輸出;基于所述替代圖像處理模型的當前輸出和所述目標圖像處理模型的當前輸出,計算所述目標圖像處理模型與所述替代圖像處理模型之間的梯度匹配損失;基于所述梯度匹配損失對所述擴散模型進行訓練;響應于訓練完成,將得到的所有替代樣本的集合,作為對所述目標數據集蒸餾后的替代數據集。
3、可選的,所述方法還包括:基于第二預設規則對所述模型池中的模型進行篩選,得到第一模型池,其中,所述第二預設規則為,對于基礎架構相同的多個圖像處理模型,在其網絡層數差異小于第一預設閾值的情況下,選取其中網絡層數最少的圖像處理模型。
4、可選的,所述方法還包括:對于所述第一模型池中的每個圖像處理模型,將每個圖像處理模型中的子網絡分別進行嵌入映射后,計算每個圖像處理模型兩兩之間的相似度,其中,所述每個圖像處理模型兩兩之間的相似度通過計算兩個圖像處理模型間預設層數的子網絡之間的相似度得到,所述預設層數為兩個圖像處理模型間網絡層數較少的圖像處理模型的網絡層數;從所述第一模型池的每組圖像處理模型中選取網絡層數最少的圖像處理模型,得到第二模型池,其中,所述每組圖像處理模型包含至少兩個相似度大于第二預設閾值的圖像處理模型。
5、可選的,所述替代圖像處理模型為從所述第二模型池中選擇得到的多個圖像處理模型,所述目標圖像處理模型為預先訓練好的與所述替代圖像處理模型同構的多個圖像處理模型;其中,所述計算所述目標圖像處理模型與所述替代圖像處理模型之間的梯度匹配損失,包括:針對多個目標圖像處理模型和多個替代圖像處理模型組成的多組同構的目標圖像處理模型和替代圖像處理模型中的每組同構的目標圖像處理模型和替代圖像處理模型,計算該組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失;基于多組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失,計算得到總的梯度匹配損失。
6、可選的,在對所述擴散模型進行訓練的第一階段,所述替代圖像處理模型為從所述第二模型池中隨機選擇得到的多個圖像處理模型;在對所述擴散模型進行訓練的第二階段,基于所述第二模型池中每個圖像處理模型各自對應的梯度匹配損失的大小,確定所述第二模型池中每個圖像處理模型各自對應選擇概率,基于所述第二模型池中每個圖像處理模型各自對應的選擇概率,在所述第二模型池中選擇得到多個圖像處理模型,作為所述替代圖像處理模型。
7、可選的,所述基于多組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失,計算得到總的梯度匹配損失,包括:對多組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失進行相加,得到所述總的梯度匹配損失。
8、可選的,所述基于多組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失,計算得到總的梯度匹配損失,包括:對多組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失進行加權相加,得到所述總的梯度匹配損失。
9、根據本公開的另一方面,還提供一種基于跨模型泛化和擴散模型的數據集蒸餾裝置,所述裝置包括:目標數據集獲取單元,被配置為:獲取目標數據集,其中,所述目標數據集為圖像數據集;模型池生成單元,被配置為:獲取與所述目標數據集的應用場景對應的多種圖像處理模型,得到模型池;數據蒸餾單元,被配置為:針對從所述目標數據集中按照第一預設規則選擇的多個樣本中的每個樣本,執行以下操作:從所述模型池中選擇得到替代圖像處理模型;將所述當前樣本輸入到目標圖像處理模型,得到所述目標圖像處理模型的當前輸出,其中,所述目標圖像處理模型為預先訓練好的與所述替代圖像處理模型同構的模型,所述目標圖像處理模型的當前輸出包括所述當前樣本的特征;將所述當前樣本的特征和針對所述當前樣本的提示詞輸入到擴散模型,得到替代樣本,其中,所述提示詞用于指示所述擴散模型基于所述當前樣本的特征生成所述替代樣本;將所述替代樣本輸入到所述替代圖像處理模型,得到所述替代圖像處理模型的當前輸出;基于所述替代圖像處理模型的當前輸出和所述目標圖像處理模型的當前輸出,計算所述目標圖像處理模型與所述替代圖像處理模型之間的梯度匹配損失;基于所述梯度匹配損失對所述擴散模型進行訓練;數據生成單元,被配置為:響應于訓練完成,將得到的所有替代樣本的集合,作為對所述目標數據集蒸餾后的替代數據集。
10、可選的,所述裝置還包括:第一模型池篩選單元,被配置為:基于第二預設規則對所述模型池中的模型進行篩選,得到第一模型池,其中,所述第二預設規則為,對于基礎架構相同的多個圖像處理模型,在其網絡層數差異小于第一預設閾值的情況下,選取其中網絡層數最少的圖像處理模型;其中,所述數據蒸餾單元被配置為:從所述第一模型池中選擇得到所述替代圖像處理模型。
11、可選的,所述裝置還包括:第二模型池篩選單元,被配置為:對于所述第一模型池中的每個圖像處理模型,將每個圖像處理模型中的子網絡分別進行嵌入映射后,計算每個圖像處理模型兩兩之間的相似度,其中,所述每個圖像處理模型兩兩之間的相似度通過計算兩個圖像處理模型間預設層數的子網絡之間的相似度得到,所述預設層數為兩個圖像處理模型間網絡層數較少的圖像處理模型的網絡層數;從所述第一模型池的每組圖像處理模型中選取網絡層數最少的圖像處理模型,得到第二模型池,其中,所述每組圖像處理模型包含至少兩個相似度大于第二預設閾值的圖像處理模型;其中,所述數據蒸餾單元被配置為:從所述第二模型池中選擇得到所述替代圖像處理模型。
12、可選的,所述替代圖像處理模型為從所述第二模型池中選擇得到的多個圖像處理模型,所述目標圖像處理模型為預先訓練好的與所述替代圖像處理模型同構的多個圖像處理模型;其中,所述數據蒸餾單元被配置為:針對多個目標圖像處理模型和多個替代圖像處理模型組成的多組同構的目標圖像處理模型和替代圖像處理模型中的每組同構的目標圖像處理模型和替代圖像處理模型,計算該組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失;基于多組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失,計算得到總的梯度匹配損失。
13、可選的,所述裝置還包括:模型選擇單元,被配置為:在對所述擴散模型進行訓練的第一階段,所述替代圖像處理模型為從所述第二模型池中隨機選擇得到的多個圖像處理模型;在對所述擴散模型進行訓練的第二階段,基于所述第二模型池中每個圖像處理模型各自對應的梯度匹配損失的大小,確定所述第二模型池中每個圖像處理模型各自對應的選擇概率,基于所述第二模型池中每個圖像處理模型各自對應的選擇概率,在所述第二模型池中選擇得到多個圖像處理模型,作為所述替代圖像處理模型。
14、可選的,所述數據蒸餾單元被配置為:對多組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失進行相加,得到所述總的梯度匹配損失。
15、可選的,所述數據蒸餾單元被配置為:對多組同構的目標圖像處理模型和替代圖像處理模型之間的梯度匹配損失進行加權相加,得到所述總的梯度匹配損失。
16、根據本公開實施例的另一方面,還提供一種電子設備,包括:至少一個處理器;至少一個存儲計算機可執行指令的存儲器,其中,所述計算機可執行指令在被所述至少一個處理器運行時,促使所述至少一個處理器執行如上任一所述的基于跨模型泛化和擴散模型的數據集蒸餾方法。
17、根據本公開實施例的另一方面,還提供一種存儲指令的計算機可讀存儲介質,當所述指令被至少一個處理器運行時,促使所述至少一個處理器執行如上任一所述的基于跨模型泛化和擴散模型的數據集蒸餾方法。
18、根據本公開實施例的另一方面,還提供一種包括至少一個計算裝置和至少一個存儲指令的存儲裝置的系統,其中,所述指令在被所述至少一個計算裝置運行時,促使所述至少一個計算裝置執行如上任一所述的基于跨模型泛化和擴散模型的數據集蒸餾方法。
19、根據本公開實施例的另一方面,還提供一種計算機程序產品,包括計算機程序/指令,所述計算機程序/指令被處理器執行時實現如上任意一項所述的基于跨模型泛化和擴散模型的數據集蒸餾方法。
20、本公開實施例提供的技術方案至少帶來以下有益效果:
21、根據本公開的基于跨模型泛化和擴散模型的數據集蒸餾方法、裝置、電子設備和存儲介質,通過結合梯度匹配方法和擴散模型,通過一次訓練,即可得到通用于大量網絡結構的替代數據集,并且,基于替代數據集進行訓練的模型性能能夠達到優異的性能;該方法的通用能力提升顯著,訓練成本大幅降低,且模型訓練性能大幅提升,能夠在實際應用中得到部署和推廣。
22、另外,通過引入多專家約束能夠對不同的模型達到良好泛化能力。
- 還沒有人留言評論。精彩留言會獲得點贊!