一種法律詞典智能生成方法及系統與流程
本技術涉及自然語言數據處理,具體涉及一種法律詞典智能生成方法及系統。
背景技術:
1、在當今數字化與智能化快速發展的時代,法律領域積極引入人工智能技術,旨在打造高效、精準的法律ai系統,以輔助法律實踐以及推動法律研究等工作邁向新的臺階。在信息化建設不斷深化的大背景下,各類法律檢索系統、智能法律咨詢平臺等的應用日益廣泛,然而現有平臺的運行效果高度依賴于法律ai的精準性和有效性,它們需要憑借對輸入內容的準確理解以及輸出高質量的響應,來滿足用戶不同的法律需求。而且在實際應用中,現有法律ai的響應效果常常大打折扣,這很大程度上源于向其提交的內容存在諸多問題,如內容提供時導致輸入的法律問題表述不準確、法律術語使用錯誤,或者存在錯別字,使得關鍵信息模糊不清;又如有些內容是經過其他ai轉譯而來,出現語義偏差、邏輯混亂等情況。
2、上述缺陷使得法律ai難以準確把握用戶意圖,進而無法給出令人滿意的精準回應,極大地限制了法律ai在法律實踐與服務中的價值發揮。倘若能夠構建一個高質量的法律詞典,以此作為基礎,對向法律ai提交或法律文本處理的內容以及其產生的響應內容進行修正和規范,那么就能從源頭上解決輸入內容質量不佳的問題,同時也能優化輸出內容,使其更符合法律專業要求,進而大幅提高精準性,讓法律ai更好地服務于廣大民眾。
3、然而,現有并沒有高效、智能構造法律詞典方案,傳統的法律詞典需要依靠人工生成更新,不僅準確性不高、效率低,且釋義單一只能適用部分專業人員,無法廣泛普及,還無法很好的與平臺或ai等應用結合。此外,現有的一般文本處理方案也不適用法律術語提取,表現存在如下幾個方面:
4、1.結構解析局限:在解析輸入內容語法結構時,往往不夠全面和深入,僅基于簡單的詞性標注或常規的詞法分析,難以有效處理復雜的法律語句結構,尤其是涉及多層嵌套、修飾關系復雜的句子。
5、2.準確性、關聯性把握不足:難以充分考量它們之間的關聯,對于一些復合名詞或通過特定搭配形成的法律短語,孤立地識別單個詞語或簡單按照詞頻統計來判斷其重要性,無法正確識別法律短語,也難以保留低頻詞語,或通過上下文語義依存關系進行合并,難以提取準確的法律術語。
6、3.釋義存在不足:過度依賴某一釋義,導致詞條的準確性存在問題或歧義,一些詞條可能存在釋義錯誤、概念模糊或者與現行法律規定不符的情況。
技術實現思路
1、基于此,本技術針對上述問題,提出了一種法律詞典智能生成方法及系統,旨在智能、高效、準確地解析法律文本并生成法律詞典,并以此進行文本處理生成更符合法律專業要求的文本或輸入,大幅提高平臺的智能性及ai應用的精準性。
2、本技術一方面提供一種法律詞典智能生成方法,所述方法包括:
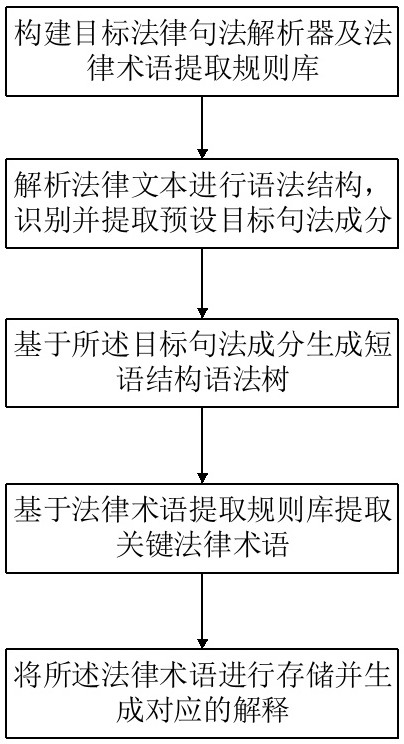
3、構建基于上下文無關法的句法解析器及法律術語提取規則庫;
4、調用所述解析器對法律文本進行語法結構解析,識別并提取包含法律術語結構的目標句法成分;
5、基于所述目標句法成分生成短語結構語法樹;
6、遍歷所述短語結構語法樹,基于所述法律術語提取規則庫提取關鍵法律術語;
7、根據組合信息度對預設相鄰的術語進行合并,和/或,基于所述法律術語提取規則庫對預設的核心語義術語成分進行拆分;
8、生成各法律術語對應的多維度解釋。
9、進一步地,所述方法還包括:
10、讀取法律文本并進行分塊處理;
11、使用分詞模型將分塊文本切分為詞語序列,并標注各詞語的詞性標簽;
12、對分塊文本進行句法分析,得到詞語間語法關聯關系及詞語索引;
13、基于所述詞語、詞性標簽、語法關系及詞語索引進行句法解析并生成短語結構語法樹。
14、更進一步地,所述方法還包括:
15、獲取上下文無關法的目標句法結構;
16、對所述詞語、詞性標簽、語法關系及詞語索引基于右向分枝原則匹配符合所述目標句法結構的目標句法成分;
17、以句子作為根節點,以所述目標句法成分逐層生成對應子節點;
18、將各目標句法成分各詞語、詞性標簽添加至對應子節點。
19、優選地,所述基于所述法律術語提取規則庫提取關鍵法律術語,包括:
20、根據詞語標簽和/或標簽組合識別,提取以下一種或多種目標對象:
21、提取僅含名詞或僅含名詞及形容詞且不包含標點或僅含名詞與預設符號標簽的連續名詞短語序列,和/或,
22、提取獨立的動詞節點或不含嵌套動詞短語且不含量詞的動詞短語,和/或,
23、提取邏輯聚焦名詞短語和動詞短語的核心語義單元,并判斷該名詞短語是否包含預設方位和/或所屬關系修飾成分。
24、進一步地,所述方法還包括:
25、計算連續相鄰名詞或短語的組合信息度:
26、,
27、其中,mi?(n1,n2)為名詞或短語詞語n1、n2的組合信息度,p(n1)、p?(n2)?為詞語n1、n2在預設法律預料庫中出現的概率,p?(n1,n2)?為二者聯合出現的概率,α為調整系數;
28、若所述組合信息度大于預設閾值,則合并所述連續相鄰名詞。
29、優選地,所述方法還包括:
30、獲取各法律術語的第一解釋及第二解釋;
31、提取第一解釋的內容、來源、地域和/時效要素信息,并提取第二解釋的內容、來源、地域、時效和/或沖突解決要素信息;
32、將第一解釋要素信息與第二解釋要素信息按時空多維度分層模型與對應法律術語關聯存儲,和/或,
33、對所述第一解釋內容及第二解釋內容進行向量化處理并存儲于預設向量數據庫,并建立與對應法律術語關聯。
34、本技術第二方面提供一種文本處理方法,基于上述任一項所述方法生成的法律詞典執行,所述文本處理方法包括:
35、獲取目標文本一個或多個待處理術語;
36、將所述待處理術語與所述法律詞典的法律術語進行匹配,和/或,計算所述待處理術語與各法律術語解釋的相似度;
37、獲取最匹配的一個或多個目標解釋和/或對應的目標法律術語;
38、基于所述目標法律術語和/或目標解釋對所述待處理術語進行解釋、校驗或提示。
39、本技術第三方面提供一種法律詞典智能生成系統,所述系統包括:
40、規則構建單元,用于構建基于上下文無關法符合法律文本的句法解析器及法律術語提取規則庫;
41、句法解析單元,用于調用所述解析器對法律文本進行語法結構解析,識別并提取預設目標句法成分;
42、結構生成單元,用于基于所述目標句法成分生成短語結構語法樹;
43、術語提取單元,用于遍歷所述短語結構語法樹,基于所述法律術語提取規則庫提取關鍵法律術語;并根據組合信息度對預設相鄰的關鍵術語進行合并,和/或,基于所述法律術語提取規則庫對預設的核心語義關鍵術語成分進行拆分;
44、解釋生成單元,用于生成與各法律術語對應的多維度解釋。
45、本技術第四方面提供一種計算機可讀存儲介質,存儲有計算機程序,所述計算機程序被處理器執行時,使得所述處理器執行上述任一項所述方法的步驟。
46、本技術第五方面提供一種計算機終端設備,包括存儲器和處理器,所述存儲器存儲有計算機程序,所述計算機程序被所述處理器執行時,使得所述處理器執行上述任一項所述方法的步驟。
47、本技術上述提供的技術方案,通過構建符合上下文無關文法適合處理法律文本的解析器對法律文本進行句法解析及提取目標句法成分,進而生成短語結構語法樹,進一步基于預設法律術語提取規則庫提取關鍵法律術語并生成對應的解釋。本技術方案能夠對法律文本的高效結構化解析與術語精準提取,從而智能、高效、準確地生成法律詞典,并且在跨文檔一致性、領域新詞上也有出色表現,大大提高了法律詞典及其后續平臺或ai應用的準確性、領域適應性、計算效率和可解釋性。
48、進一步地,本技術方案采用多層結構并結合右向分枝匹配以滿足在法律領域常見的同一術語可能存在的不同法律定義情況,進一步提高了法律術語的準確性及效率。并且本技術還將分散、繁雜的法律術語及其解釋數據進行了高度結構化的整合,通過時空維度下的術語分層模型,以及在向量數據庫中有序存儲向量數據,使得原本無序的法律信息變得條理清晰、易于管理和查詢,為后續的各種應用(如沖突解決、檢索、ai等)奠定了良好的數據基礎。
- 還沒有人留言評論。精彩留言會獲得點贊!