基于大模型文檔索引感知的對(duì)話式生成檢索方法及系統(tǒng)
本發(fā)明涉及信息檢索,尤其涉及一種基于大模型文檔索引感知的對(duì)話式生成檢索方法及系統(tǒng)。
背景技術(shù):
1、本部分的陳述僅僅是提供了與本發(fā)明相關(guān)的背景技術(shù)信息,不必然構(gòu)成在先技術(shù)。
2、隨著人工智能和自然語(yǔ)言處理技術(shù)的不斷發(fā)展,對(duì)話式信息檢索系統(tǒng)逐漸成為現(xiàn)代信息檢索領(lǐng)域的重要組成部分。對(duì)話式信息檢索旨在通過(guò)與用戶的自然語(yǔ)言交互,更準(zhǔn)確地理解用戶的需求,并提供相關(guān)的、準(zhǔn)確的信息。這種系統(tǒng)不僅能夠提供更自然、更直觀的搜索體驗(yàn),還能夠根據(jù)用戶的上下文信息和意圖動(dòng)態(tài)調(diào)整檢索結(jié)果,從而提高用戶滿意度和檢索效率。在傳統(tǒng)的信息檢索系統(tǒng)中,用戶通常通過(guò)輸入一個(gè)獨(dú)立的查詢來(lái)獲取信息。然而,在對(duì)話式信息檢索中,用戶的查詢往往是上下文相關(guān)的,這意味著模型需要從對(duì)話歷史中提取關(guān)鍵信息,以理解用戶當(dāng)前的信息需求。這給傳統(tǒng)的即席檢索方法帶來(lái)了獨(dú)特的挑戰(zhàn),促使對(duì)話式檢索技術(shù)不斷發(fā)展和創(chuàng)新,以更好地捕捉用戶的搜索意圖并提高檢索結(jié)果的準(zhǔn)確性。對(duì)話式檢索面臨的兩個(gè)主要挑戰(zhàn)是:首先,用戶查詢可能包含代詞引用。例如,在對(duì)話中,用戶可能會(huì)使用“它”或“后者地方”來(lái)指代之前提到的“敦刻爾克”和“烏爾克”。其次,當(dāng)前查詢的意圖可能會(huì)被無(wú)關(guān)的上下文所掩蓋。例如,在關(guān)于“烏爾克”的最后一個(gè)問(wèn)題中,檢索模型可能會(huì)被與“敦刻爾克”相關(guān)的歷史上下文誤導(dǎo),錯(cuò)誤地將關(guān)于“敦刻爾克”的文檔排名高于那些關(guān)于“烏爾克”的文檔。
3、為了解決上述挑戰(zhàn),目前已經(jīng)開(kāi)發(fā)了兩種主要方法:對(duì)話式查詢重寫(xiě)(contextualquery?rewrite,cqr)和對(duì)話式密集檢索(crash?data?retrieval?,cdr)。對(duì)話式查詢重寫(xiě)的方法旨在訓(xùn)練一個(gè)重寫(xiě)模型,將當(dāng)前查詢基于對(duì)話上下文轉(zhuǎn)換為一個(gè)獨(dú)立的查詢。然而,由于重寫(xiě)過(guò)程與檢索過(guò)程相互獨(dú)立,這些方法在端到端訓(xùn)練方面存在困難,并且受到查詢重寫(xiě)訓(xùn)練數(shù)據(jù)的限制。對(duì)話式密集檢索的方法則訓(xùn)練一個(gè)雙編碼器模型,將所有上下文和文檔嵌入到高維空間中以計(jì)算相關(guān)性得分。盡管一些研究設(shè)計(jì)了復(fù)雜的訓(xùn)練策略來(lái)改進(jìn)上下文表示,但由于密集檢索的限制,對(duì)話式密集檢索的方法無(wú)法實(shí)現(xiàn)最佳的去噪效果。具體來(lái)說(shuō),密集檢索使用固定長(zhǎng)度的編碼來(lái)表示上下文,導(dǎo)致嵌入瓶頸問(wèn)題。此外,監(jiān)督信號(hào)只能通過(guò)這些固定長(zhǎng)度的編碼傳播,限制了模型的學(xué)習(xí)能力。這些固有限制在具有復(fù)雜和嘈雜上下文的對(duì)話式檢索場(chǎng)景中進(jìn)一步加劇。
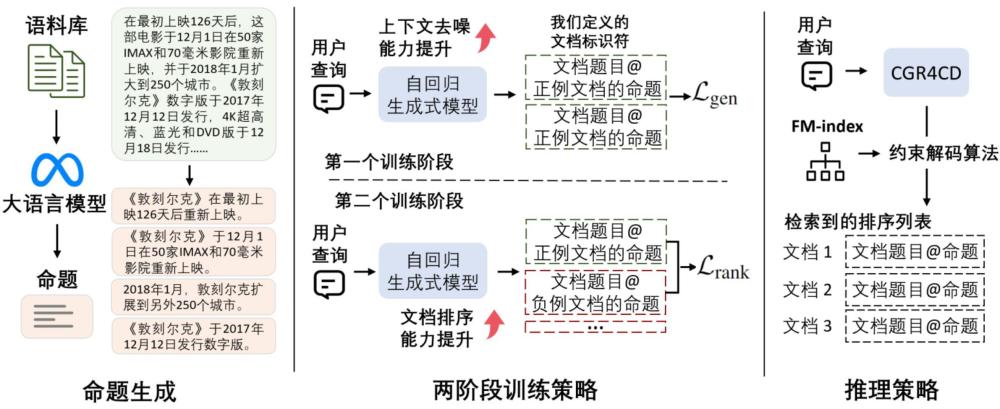
4、為了克服這些限制,生成式檢索是一種新興的檢索范式,利用序列到序列框架生成文檔標(biāo)識(shí)符(docids)以進(jìn)行檢索。與密集檢索相比,生成式檢索的主要優(yōu)勢(shì)在于兩個(gè)方面。首先,生成式檢索實(shí)現(xiàn)了真正的端到端訓(xùn)練,允許監(jiān)督信號(hào)直接傳播到模型參數(shù)。這消除了嵌入瓶頸問(wèn)題,使得模型能夠更有效地學(xué)習(xí)上下文去噪能力。其次生成式檢索gr采用編碼器-解碼器架構(gòu)。在這個(gè)框架中,交叉注意力層促進(jìn)了查詢標(biāo)記和文檔標(biāo)記之間的交互,幫助解碼器更好地理解輸入查詢,這對(duì)于上下文去噪是有益的。盡管已有研究展示了生成式檢索在理解復(fù)雜用戶查詢方面的優(yōu)勢(shì),但先前的方法僅依賴于文檔標(biāo)題,并未考慮文檔的具體內(nèi)容,導(dǎo)致在廣泛使用的對(duì)話式檢索數(shù)據(jù)集上的性能不佳。綜上所述,現(xiàn)有的對(duì)話式檢索方法在處理復(fù)雜上下文和噪聲方面存在局限性。
技術(shù)實(shí)現(xiàn)思路
1、為了解決上述背景技術(shù)中存在的技術(shù)問(wèn)題,本發(fā)明提供一種基于大模型文檔索引感知的對(duì)話式生成檢索方法及系統(tǒng),本發(fā)明旨在基于大模型文檔索引感知,通過(guò)生成式檢索框架提升對(duì)話搜索在具有上下文噪聲情況下的準(zhǔn)確性和魯棒性,以更好地滿足用戶在動(dòng)態(tài)交互過(guò)程中的信息需求。
2、為了實(shí)現(xiàn)上述目的,本發(fā)明采用如下技術(shù)方案:
3、本發(fā)明的第一個(gè)方面提供一種基于大模型文檔索引感知的對(duì)話式生成檢索方法。
4、一種基于大模型文檔索引感知的對(duì)話式生成檢索方法,包括:
5、根據(jù)用戶查詢輸入,采用已訓(xùn)練的大語(yǔ)言模型,輸出與用戶查詢輸入相關(guān)的信息排序列表;
6、其中,大語(yǔ)言模型訓(xùn)練的過(guò)程包括:基于語(yǔ)料庫(kù),采用交叉注意力層,提取上下文的關(guān)鍵信息,得到命題,得到文檔標(biāo)識(shí)符;在第一階段訓(xùn)練中,引入生成損失生成與當(dāng)前查詢相關(guān)的信息,并生成文檔標(biāo)識(shí)符;在第二階段訓(xùn)練中,引入綜合損失優(yōu)化檢索到的文檔標(biāo)識(shí)符的排名列表;通過(guò)束搜索解碼策略,輸出文檔標(biāo)識(shí)符對(duì)應(yīng)的段落排名列表。
7、進(jìn)一步地,所述文檔標(biāo)識(shí)符為文檔標(biāo)題后面加命題的組合。
8、進(jìn)一步地,在所述大語(yǔ)言模型解碼過(guò)程中,采用文檔標(biāo)題作為前綴指導(dǎo)編碼過(guò)程。
9、進(jìn)一步地,所述生成損失采用最大似然估計(jì)損失。
10、進(jìn)一步地,所述綜合損失采用以下公式表示:
11、
12、
13、
14、其中,表示綜合損失,表示生成損失,表示排序損失,表示任意文檔標(biāo)識(shí)符,表示當(dāng)前訓(xùn)練數(shù)據(jù)實(shí)例的第個(gè)困難負(fù)樣本文檔標(biāo)識(shí)符,是邊距超參數(shù),是困難負(fù)樣本文檔標(biāo)識(shí)符的數(shù)量,是用于平衡兩種損失的權(quán)重超參數(shù)。
15、進(jìn)一步地,所述通過(guò)束搜索解碼策略,輸出文檔標(biāo)識(shí)符對(duì)應(yīng)的段落排名列表;方法包括:通過(guò)fm-index約束解碼空間,確保生成的文檔標(biāo)識(shí)符有效,并根據(jù)生成概率對(duì)段落進(jìn)行排名,為用戶提供與用戶查詢輸入最相關(guān)的信息。
16、本發(fā)明的第二個(gè)方面提供一種基于大模型文檔索引感知的對(duì)話式生成檢索系統(tǒng)。
17、一種基于大模型文檔索引感知的對(duì)話式生成檢索系統(tǒng),包括:
18、查詢模塊,其被配置為:根據(jù)用戶查詢輸入,采用已訓(xùn)練的大語(yǔ)言模型,輸出與用戶查詢輸入相關(guān)的信息排序列表;
19、其中,大語(yǔ)言模型訓(xùn)練的過(guò)程包括:基于語(yǔ)料庫(kù),采用交叉注意力層,提取上下文的關(guān)鍵信息,得到命題,得到文檔標(biāo)識(shí)符;在第一階段訓(xùn)練中,引入生成損失生成與當(dāng)前查詢相關(guān)的信息,并生成文檔標(biāo)識(shí)符;在第二階段訓(xùn)練中,引入綜合損失優(yōu)化檢索到的文檔標(biāo)識(shí)符的排名列表;通過(guò)束搜索解碼策略,輸出文檔標(biāo)識(shí)符對(duì)應(yīng)的段落排名列表。
20、本發(fā)明的第三個(gè)方面提供一種計(jì)算機(jī)可讀存儲(chǔ)介質(zhì)。
21、一種計(jì)算機(jī)可讀存儲(chǔ)介質(zhì),其上存儲(chǔ)有計(jì)算機(jī)程序,該程序被處理器執(zhí)行時(shí)實(shí)現(xiàn)如上述第一個(gè)方面所述的基于大模型文檔索引感知的對(duì)話式生成檢索方法中的步驟。
22、本發(fā)明的第四個(gè)方面提供一種計(jì)算機(jī)設(shè)備。
23、一種計(jì)算機(jī)設(shè)備,包括存儲(chǔ)器、處理器及存儲(chǔ)在存儲(chǔ)器上并可在處理器上運(yùn)行的計(jì)算機(jī)程序,所述處理器執(zhí)行所述程序時(shí)實(shí)現(xiàn)如上述第一個(gè)方面所述的基于大模型文檔索引感知的對(duì)話式生成檢索方法中的步驟。
24、本發(fā)明的第五個(gè)方面提供一種計(jì)算機(jī)程序產(chǎn)品或計(jì)算機(jī)程序。
25、本發(fā)明提供了一種計(jì)算機(jī)程序產(chǎn)品或計(jì)算機(jī)程序,該計(jì)算機(jī)程序產(chǎn)品或計(jì)算機(jī)程序包括計(jì)算機(jī)指令,該計(jì)算機(jī)指令存儲(chǔ)在計(jì)算機(jī)可讀存儲(chǔ)介質(zhì)中。計(jì)算機(jī)設(shè)備的處理器從計(jì)算機(jī)可讀存儲(chǔ)介質(zhì)讀取該計(jì)算機(jī)指令,處理器執(zhí)行該計(jì)算機(jī)指令,使得該計(jì)算機(jī)設(shè)備執(zhí)行如上述第一個(gè)方面所述的基于大模型文檔索引感知的對(duì)話式生成檢索方法中的步驟。
26、與現(xiàn)有技術(shù)相比,本發(fā)明的有益效果是:
27、本發(fā)明提出了一種基于大模型文檔索引感知的對(duì)話式生成檢索方法及系統(tǒng),根據(jù)用戶查詢輸入,采用已訓(xùn)練的大語(yǔ)言模型,輸出與用戶查詢輸入相關(guān)的信息排序列表;其中,大語(yǔ)言模型訓(xùn)練的過(guò)程包括:基于語(yǔ)料庫(kù),采用交叉注意力層,提取上下文的關(guān)鍵信息,得到命題,得到文檔標(biāo)識(shí)符;在第一階段訓(xùn)練中,引入生成損失生成與當(dāng)前查詢相關(guān)的信息,并生成文檔標(biāo)識(shí)符;在第二階段訓(xùn)練中,引入綜合損失優(yōu)化檢索到的文檔標(biāo)識(shí)符的排名列表;通過(guò)束搜索解碼策略,輸出文檔標(biāo)識(shí)符對(duì)應(yīng)的段落排名列表。本發(fā)明通過(guò)生成文檔標(biāo)識(shí)符不僅減少了訓(xùn)練負(fù)擔(dān),還能捕捉到段落中的細(xì)粒度信息,為生成式檢索在對(duì)話搜索中的應(yīng)用提供了新的視角,有助于更精準(zhǔn)地定位和檢索相關(guān)信息;通過(guò)兩階段的訓(xùn)練方式大語(yǔ)言模型在上下文去噪和段落排名方面的能力得到了全面提升,在約束搜索解碼策略下為用戶提供最相關(guān)的信息。
- 還沒(méi)有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!