基于k段分解的低復(fù)雜度極化碼折疊硬件構(gòu)架的實(shí)現(xiàn)方法與流程
本發(fā)明涉及極化碼折疊硬件構(gòu)架的實(shí)現(xiàn)方法,特別是涉及基于k段分解的低復(fù)雜度極化碼折疊硬件構(gòu)架的實(shí)現(xiàn)方法。
背景技術(shù):
Ar1kan提出,極性碼是信道編碼的第一類,幾乎可實(shí)現(xiàn)對(duì)稱的二進(jìn)制輸入離散無記憶信道的容量(B-DMCs)。由于其較低的計(jì)算復(fù)雜度為O(NlogN),其中N為極化碼長(zhǎng)度;以及快速傅氏變換Fast Fourier Transformation(FFT)形式的譯碼結(jié)構(gòu),串行抵消譯碼successive cancellation(SC)算法已經(jīng)成為最有效的極化譯碼算法之一。大多數(shù)極化碼譯碼方案都已SC為基礎(chǔ)進(jìn)行譯碼處理。
然而SC譯碼算法遵循的基本譯碼原則是利用以譯出的比特信息最為反饋信息按照順序逐個(gè)比特進(jìn)行譯碼,這樣的譯碼操作帶來了巨大的硬件資源消耗問題。對(duì)于N比特碼長(zhǎng)的極化碼,其所需的計(jì)算單元為N log2N,經(jīng)過現(xiàn)有的時(shí)序硬件優(yōu)化設(shè)計(jì),在帶有預(yù)計(jì)算的混合節(jié)點(diǎn)硬件構(gòu)架中,共需要的硬件處理單元數(shù)為N-1。由此可以看出,當(dāng)極化碼的碼長(zhǎng)數(shù)量級(jí)較大時(shí),譯碼所需的硬件處理單元與碼長(zhǎng)處于同一數(shù)量級(jí)。這樣的硬件配置消耗了大量的硬件資源。根據(jù)極化碼本身的性質(zhì),極化碼在碼長(zhǎng)趨于無窮的時(shí)候才能達(dá)到逼近香濃線的性質(zhì)。當(dāng)我們的硬件平臺(tái)資源占有限的時(shí)候,傳統(tǒng)的SC譯碼硬件設(shè)計(jì)成為了制約極化碼碼長(zhǎng)的致命因素。
技術(shù)實(shí)現(xiàn)要素:
發(fā)明目的:本發(fā)明的目的是提供一種能夠有效降低硬件資源消耗的基于k段分解的低復(fù)雜度極化碼折疊硬件構(gòu)架的實(shí)現(xiàn)方法。
技術(shù)方案:為達(dá)到此目的,本發(fā)明采用以下技術(shù)方案:
本發(fā)明所述的基于k段分解的低復(fù)雜度極化碼折疊硬件構(gòu)架的實(shí)現(xiàn)方法,包括以下步驟:
S1:將n級(jí)SC譯碼算法分解為k段,k是n的因子,滿足n=kp的關(guān)系式,p為整數(shù),極化碼的碼長(zhǎng)為N,且N=2n;
S2:對(duì)于已分解的k段SC譯碼算法,配置(k-1)個(gè)次級(jí)譯碼器,每個(gè)譯碼器的譯碼級(jí)數(shù)為p級(jí),根據(jù)式(1)計(jì)算各段的折疊集:
......
式(1)中,Si為第i段的折疊集,1≤i≤(k-1),令w為各折疊集的總操作數(shù),即Si中具有w個(gè)元素,則x1=w/2p-1-2n-p,為每段的折疊操作向量,表示第i段的第m個(gè)折疊操作,
S3:根據(jù)步驟S2得到的各段折疊集搭建極化碼折疊硬件構(gòu)架。
進(jìn)一步,所述步驟S1包括以下步驟:
S1.1:確定輸入:對(duì)于一幀極化碼的N個(gè)輸入數(shù)據(jù)[y1,y2,...,yN],求得對(duì)應(yīng)的LLR值,記為其中為中q=0、r=1的情況,1≤t≤N,q表示譯碼器第i級(jí)輸出的LLR,r表示原始譯碼器中第r次并進(jìn)節(jié)點(diǎn)計(jì)算結(jié)果;確定待譯碼的碼長(zhǎng)為N,所需分段的段數(shù)為k;
S1.2:按照以下步驟建立分段解碼函數(shù):
S1.2.1:設(shè)n=log2N,且p=n/k;
S1.2.2:判斷段數(shù)k是否為1:若k=1,則將輸入進(jìn)碼長(zhǎng)為2p的解碼器進(jìn)行傳統(tǒng)的解碼計(jì)算,得到2p比特譯碼結(jié)果并將作為解碼函數(shù)的輸出,結(jié)束本輪的操作;否則,設(shè)變量h=1,然后進(jìn)入步驟S1.2.3;
S1.2.3:如果h≤2p/2,則令變量j=2h-1,i=1,然后進(jìn)入步驟S1.2.4;否則,進(jìn)入步驟S1.2.9;
S1.2.4:如果i≤2n-p,則將輸入碼長(zhǎng)為2p的解碼器進(jìn)行傳統(tǒng)的解碼計(jì)算,計(jì)算第j位對(duì)應(yīng)的LLR值然后進(jìn)入步驟S1.2.5;否則,進(jìn)入步驟S1.2.6;
S1.2.5:變量i的數(shù)值加一,并進(jìn)入步驟S1.2.4;
S1.2.6:調(diào)用分段解碼函數(shù)將分段解碼函數(shù)的輸出賦給變量
S1.2.7:調(diào)用分段解碼函數(shù)將分段解碼函數(shù)的輸出賦給變量
S1.2.8:變量h的數(shù)值加一,并進(jìn)入步驟S1.2.3;
S1.2.9:得到N比特譯碼結(jié)果并將作為分段解碼函數(shù)的輸出,結(jié)束本輪操作。
有益效果:本發(fā)明公開了一種基于k段分解的低復(fù)雜度極化碼折疊硬件構(gòu)架的實(shí)現(xiàn)方法,針對(duì)原本長(zhǎng)碼極化碼硬件資源消耗高的問題,首先將SC譯碼算法分解為k段,每一段都可以通過碼長(zhǎng)為2p的短碼譯碼步驟組合完成。然后在相對(duì)應(yīng)的硬件構(gòu)架設(shè)計(jì)上,通過短碼極化碼構(gòu)架的迭代折疊,實(shí)現(xiàn)長(zhǎng)碼譯碼。極大降低了硬件復(fù)雜度,降低了硬件資源消耗,提升了節(jié)點(diǎn)資源利用率。
附圖說明
圖1為傳統(tǒng)的SC譯碼算法的8比特SC譯碼流程圖;
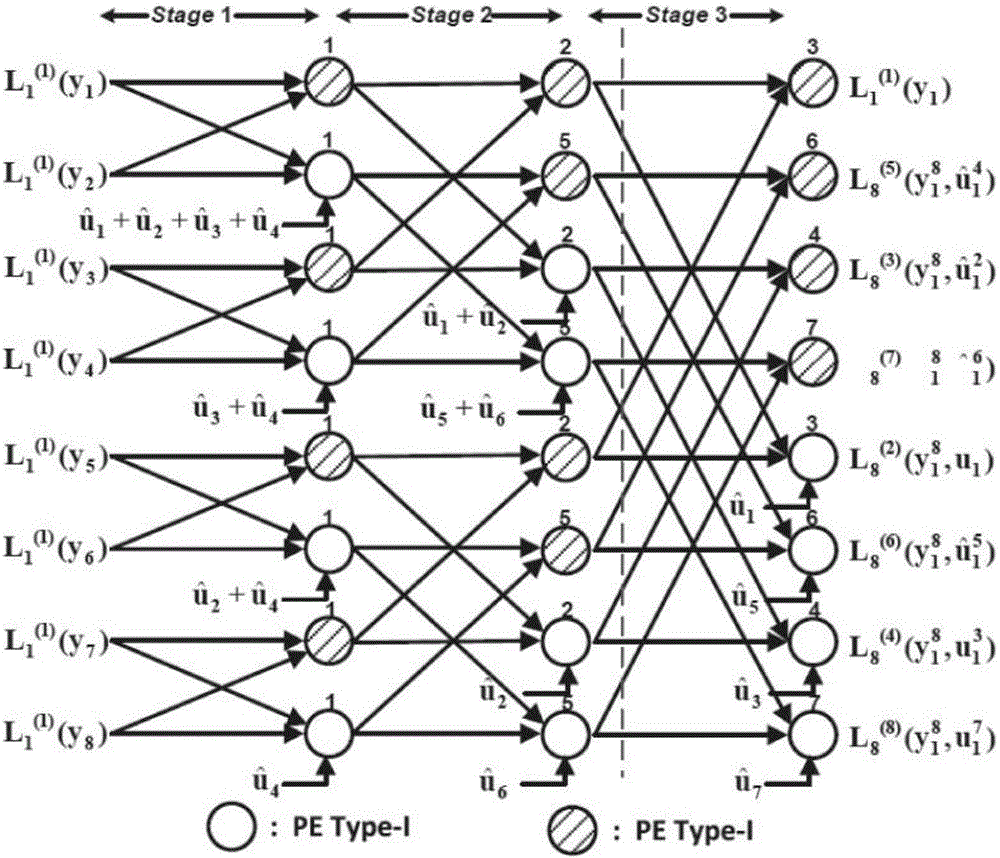
圖2為本發(fā)明具體實(shí)施方式的基于k=3段分解的8比特SC譯碼折疊硬件構(gòu)架的示意圖;
圖3為本發(fā)明具體實(shí)施方式的基于k=3段分解的64比特SC譯碼折疊硬件構(gòu)架的示意圖。
具體實(shí)施方式
下面結(jié)合具體實(shí)施方式對(duì)本發(fā)明的技術(shù)方案作進(jìn)一步的介紹。
首先介紹一下傳統(tǒng)的SC譯碼算法。
考慮一個(gè)極化碼(N,K,A),其中N表示極化碼的碼長(zhǎng),K表示極化碼中有效信息數(shù),A表示有效信息比特集合。設(shè)接收端接收到的待譯碼向量為yi=(y1,...,yN),接收端的譯碼結(jié)果表示為如果ui不是有效信息比特,我們將置零。否則譯碼比特可以表示為:
其中,定義了信道傳輸概率。解碼運(yùn)算中使用LLR(log-likelihood ratio)來計(jì)算,LLR的定義如下:
LLR的運(yùn)算法則滿足下列遞推關(guān)系式:
傳統(tǒng)的SC譯碼器符合FFT碟形譯碼規(guī)則。
蝶形譯碼流程度見圖1。圖1給出了一個(gè)8比特SC譯碼流程圖,在這個(gè)譯碼流程一共包含了3級(jí)(3=log8)。
下面介紹一下本具體實(shí)施方式的基于k段分解的低復(fù)雜度極化碼折疊硬件構(gòu)架的實(shí)現(xiàn)方法,包括以下步驟:
S1:將n級(jí)SC譯碼算法分解為k段,k是n的因子,滿足n=kp的關(guān)系式,p為整數(shù),極化碼的碼長(zhǎng)為N,且N=2n;
步驟S1包括以下步驟:
S1.1:確定輸入:對(duì)于一幀極化碼的N個(gè)輸入數(shù)據(jù)[y1,y2,...,yN](即譯碼器的輸入數(shù)據(jù)),求得對(duì)應(yīng)的LLR值,記為其中為中q=0、r=1的情況,1≤t≤N,q表示譯碼器第i級(jí)輸出的LLR,r表示原始譯碼器中第r次并進(jìn)節(jié)點(diǎn)計(jì)算結(jié)果;確定待譯碼的碼長(zhǎng)為N,所需分段的段數(shù)為k;
S1.2:按照以下步驟建立分段解碼函數(shù):
S1.2.1:設(shè)n=log2N,且p=n/k;
S1.2.2:判斷段數(shù)k是否為1:若k=1,則將輸入進(jìn)碼長(zhǎng)為2p的解碼器進(jìn)行傳統(tǒng)的解碼計(jì)算,得到2p比特譯碼結(jié)果并將作為解碼函數(shù)的輸出,結(jié)束本輪的操作;否則,設(shè)變量h=1,然后進(jìn)入步驟S1.2.3;
S1.2.3:如果h≤2p/2,則令變量j=2h-1,i=1,然后進(jìn)入步驟S1.2.4;否則,進(jìn)入步驟S1.2.9;
S1.2.4:如果i≤2n-p,則將輸入碼長(zhǎng)為2p的解碼器進(jìn)行傳統(tǒng)的解碼計(jì)算,計(jì)算第j位對(duì)應(yīng)的LLR值然后進(jìn)入步驟S1.2.5;否則,進(jìn)入步驟S1.2.6;
S1.2.5:變量i的數(shù)值加一,并進(jìn)入步驟S1.2.4;
S1.2.6:調(diào)用分段解碼函數(shù)將分段解碼函數(shù)的輸出賦給變量
S1.2.7:調(diào)用分段解碼函數(shù)將分段解碼函數(shù)的輸出賦給變量
S1.2.8:變量h的數(shù)值加一,并進(jìn)入步驟S1.2.3;
S1.2.9:得到N比特譯碼結(jié)果并將作為分段解碼函數(shù)的輸出,結(jié)束本輪操作。
S2:對(duì)于已分解的k段SC譯碼算法,配置譯碼器。如果每一段都分配一個(gè)譯碼器硬件構(gòu)架,那么一共需要k個(gè)p級(jí)譯碼器完成原本的n級(jí)譯碼器設(shè)計(jì)。在每一段中,由于只分配一個(gè)譯碼器,則要完成該段原本的譯碼任務(wù)需要進(jìn)行不同次數(shù)的折疊復(fù)用。下表給出了每一段完成一次原始操作所需p級(jí)譯碼器的折疊次數(shù)。
表1各段完成一次原始操作所需p級(jí)譯碼器的折疊次數(shù)
從上表的折疊次數(shù)可以發(fā)現(xiàn),隔段之間存在并行操作的可能。例如,第i段譯碼輸出了第一組2p個(gè)LLR的譯碼結(jié)果,則第i+1段可以開始工作,與此同時(shí),第i段依舊在工作狀態(tài)進(jìn)行著下一組2p個(gè)LLR的譯碼。由此我們?cè)诿慷紊隙荚O(shè)定一個(gè)短碼譯碼器是合理的。但需要注意的是,最后一段的折疊次數(shù)是一,也就是說最后兩段之間是不存在并行計(jì)算的,那么我們將最后兩段合并為一個(gè)p級(jí)譯碼器。這樣本具體實(shí)施方式最終的譯碼器設(shè)定為(k-1)個(gè)p級(jí)譯碼器。根據(jù)式(4)計(jì)算各段的折疊集:
......
式(4)中,Si為第i段的折疊集,1≤i≤(k-1)令w為各折疊集的總操作數(shù),即Si中具有w個(gè)元素,則x1=w/2p-1-2n-p,為每段的折疊操作向量,表示第i段的第m個(gè)折疊操作,
S3:根據(jù)步驟S2得到的各段折疊集搭建極化碼折疊硬件構(gòu)架。
除此之外,對(duì)于每一段的折疊操作,可以采用流水線的形式來計(jì)算。因?yàn)槎蝺?nèi)的折疊不涉及到互相反饋信息,所以段內(nèi)折疊操作可以采用流水線形式來大大縮短因折疊而帶來的延時(shí)增長(zhǎng)。
采用帶有預(yù)計(jì)算功能的極化碼SC譯碼構(gòu)架作為折疊的基礎(chǔ)。每個(gè)次級(jí)譯碼器遵從該構(gòu)架的設(shè)計(jì)基礎(chǔ)。圖2給出了基于三段分解的8-比特譯碼器硬件構(gòu)架圖。原始的帶有預(yù)計(jì)算功能的8比特譯碼器需要7個(gè)混合節(jié)點(diǎn)模塊。8比特對(duì)應(yīng)了3級(jí)譯碼。在本具體實(shí)施方式中,我們先將原始的三級(jí)譯碼算法分為三段,則每段由級(jí)數(shù)為1的次級(jí)譯碼器完成,再根據(jù)硬件設(shè)計(jì)中后兩段折疊合并的規(guī)則,最終通過兩個(gè)次級(jí)譯碼器完成所有操作。每個(gè)次級(jí)譯碼器為2-比特譯碼器。則最終的折疊構(gòu)架只需要兩個(gè)混合節(jié)點(diǎn)模塊,相比于原來的7個(gè)混合節(jié)點(diǎn)模塊,本設(shè)計(jì)大大縮短了原始的硬件復(fù)雜度。
圖3給出了基于三段分解的64-比特譯碼器硬件構(gòu)架圖。原始的帶有預(yù)計(jì)算功能的64比特譯碼器需要63個(gè)混合節(jié)點(diǎn)模塊。64比特對(duì)應(yīng)了6級(jí)譯碼。在本設(shè)計(jì)中,我們先將原始的六級(jí)譯碼算法分為三段,則每段由級(jí)數(shù)為2的次級(jí)譯碼器完成,再根據(jù)硬件設(shè)計(jì)中后兩段折疊合并的規(guī)則,最終通過兩個(gè)次級(jí)譯碼器完成所有操作。每個(gè)次級(jí)譯碼器為4-比特譯碼器。則最終的折疊構(gòu)架只需要6個(gè)混合節(jié)點(diǎn)模塊,相比于原來的63個(gè)混合節(jié)點(diǎn)模塊,本具體實(shí)施方式大大縮短了原始的硬件復(fù)雜度。
為了更好的對(duì)比分析本設(shè)計(jì)帶來的硬件優(yōu)勢(shì),定義指標(biāo)“硬件資源利用率”為譯碼所需計(jì)算單元數(shù)與硬件實(shí)際提供的計(jì)算單元數(shù)之比。在SC譯碼算法中,譯碼所需的計(jì)算單元數(shù)為N log2N,而不同的硬件設(shè)計(jì)下,實(shí)際的計(jì)算單元數(shù)為硬件架構(gòu)本身包括的計(jì)算模塊數(shù)量乘以譯完一幀所消耗的延時(shí)周期。
根據(jù)本具體實(shí)施方式(k-1)個(gè)次級(jí)譯碼器的設(shè)計(jì)思路,很容易得到本設(shè)計(jì)構(gòu)架所消耗的計(jì)算單元數(shù)M如下:
根據(jù)折疊集的分布,以及各段中的流水線操作,可以計(jì)算出本設(shè)計(jì)所消耗的延時(shí)數(shù)量L如下:
由此可以計(jì)算出本設(shè)計(jì)的硬件資源利用率(HUR):
根據(jù)HUR的計(jì)算公式,可以對(duì)不同的碼長(zhǎng)N與不同的分段情況k進(jìn)行構(gòu)架分析,分析結(jié)果列表如下:
表2不同N與k取值下的HUR對(duì)比表
當(dāng)k=1時(shí),表示一共只有1段,也就是沒有進(jìn)行段分解操作,換句話說就是原始的譯碼構(gòu)架沒有進(jìn)行段內(nèi)折疊。從上表中看出,當(dāng)k不為1時(shí)本具體實(shí)施方式提出的折疊架構(gòu)在硬件資源利用率上有了明顯的提高,這說明本具體實(shí)施方式的設(shè)計(jì)是有效的。
下面進(jìn)行硬件資源消耗分析:
本具體實(shí)施方式的核心旨在降低SC譯碼的硬件復(fù)雜度。換句話說,本具體實(shí)施方式的核心是保證了硬件資源有限的情況下依舊能夠完成長(zhǎng)碼的SC譯碼需求。本具體實(shí)施方式主要針對(duì)譯碼計(jì)算單元進(jìn)行了折疊。折疊后,根據(jù)譯碼計(jì)算單元數(shù)來表達(dá)硬件資源消耗。下表分析展示了本具體實(shí)施方式所需的譯碼計(jì)算單元數(shù):
表3不同N與k取值下的硬件架構(gòu)計(jì)算單元資源對(duì)比表
從表3可以看出,當(dāng)k=1時(shí),表示一共只有1段,也就是沒有進(jìn)行段分解操作,換句話說就是原始的譯碼構(gòu)架沒有進(jìn)行段內(nèi)折疊。從表3可以看出,當(dāng)k不為1時(shí)本具體實(shí)施方式提出的折疊架構(gòu)在硬件資源消耗上有了明顯的降低,這說明本具體實(shí)施方式的設(shè)計(jì)是有效的。
下面進(jìn)行VLSI實(shí)測(cè)分析:
根據(jù)本具體實(shí)施方式的思想,發(fā)明人在Altera Stratix V上實(shí)現(xiàn)了不同N與k的各規(guī)格譯碼器,其資源消耗如下:
表4不同極化碼規(guī)格下的譯碼器硬件實(shí)現(xiàn)資源消耗對(duì)比
表4給出了兩組碼長(zhǎng)的對(duì)比。對(duì)于8-比特的譯碼器,進(jìn)行了2段分解后的譯碼器的資源消耗是未進(jìn)行分段的一半。對(duì)于024-比特的譯碼器,進(jìn)行了3段分解后的譯碼器的資源消耗是未進(jìn)行分段的十分之一。硬件實(shí)現(xiàn)的真實(shí)數(shù)據(jù)再次證明了本具體實(shí)施方式的有效性。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!
- 一種基于子窗合并的信號(hào)檢測(cè)方法與流程
- 一種多參數(shù)優(yōu)化方法與流程
- 一種基于代碼圈復(fù)雜度度量的軟件演化評(píng)估方法與流程
- 混流焊裝系統(tǒng)復(fù)雜度計(jì)算算法及復(fù)雜度源識(shí)別診斷方法與流程
- 基于強(qiáng)氧化與多級(jí)循環(huán)生化處理細(xì)雜皮生產(chǎn)廢水的方法與流程
- 用于動(dòng)態(tài)地更新分類器復(fù)雜度的方法與流程
- 一種基于改進(jìn)的KLT和卡爾曼濾波的電子穩(wěn)像方法與流程
- 目標(biāo)對(duì)象的處理方法和裝置與流程
- 基于改進(jìn)了適用范圍的卡爾曼濾波的靜態(tài)PET圖像重建方法與流程
- 一種支持全局復(fù)雜檢索的跨地域查詢方法及系統(tǒng)與流程
- 一種營(yíng)銷型網(wǎng)站文檔快速排序系統(tǒng)及排序方法
- 具有低接收器復(fù)雜度的向量信令的制作方法
- 使用低復(fù)雜度發(fā)射機(jī)增加對(duì)噪聲免疫力的感應(yīng)通信系統(tǒng)的制作方法
- 基于復(fù)雜查詢條件下的酒店價(jià)格排序方法
- 基于集團(tuán)度的復(fù)雜網(wǎng)絡(luò)重要節(jié)點(diǎn)排序方法及模型演化方法
- 基于復(fù)雜度均衡的并行編解碼方法、裝置及系統(tǒng)的制作方法
- 基于流水線進(jìn)程的歸并排序方法及使用該方法的閥控裝置的制造方法
- 一種便于排序及計(jì)數(shù)核查的卡片的制作方法
- 用于估計(jì)視頻質(zhì)量評(píng)估的內(nèi)容復(fù)雜度的方法和裝置的制造方法
- 能夠降低復(fù)雜度的基于和均方誤差最小原則的下行多用戶mimo系統(tǒng)預(yù)編碼方法