一種基于核功率密度的無線信道多徑分簇方法與流程
本發(fā)明涉及一種基于核功率密度的無線信道多徑分簇方法,用于無線通信系統(tǒng)中面向傳播信道建模,屬于無線移動通信領(lǐng)域。
背景技術(shù):
信道建模是無線通信中一個重要的研究方向,因為準確的信道模型是開展任意無線通信系統(tǒng)設(shè)計與性能分析的前提。信道建模的主要目的在于準確刻畫不同環(huán)境中的多徑信號的統(tǒng)計分布規(guī)律。在描述無線信道多徑統(tǒng)計分布規(guī)律的模型中,抽頭延遲線(Tapped Delay Line,TDL)模型頗具代表性,該模型在時延域?qū)⑿诺烂枋鰹橛纱罅慷鄰蒋B加而形成,并且包含了小尺度衰落特性。TDL模型在較長時間內(nèi)被廣泛使用,并且在早期的無線通信系統(tǒng),如COST 207模型中被采納為標準化信道模型。
然而,3G、4G以及下一代通信系統(tǒng)需要更高的帶寬以及更大維度的多天線(multiple-input-multiple-output,MIMO)陣列。基于此,信道多徑分量在時延域與角度域具有更高的分辨率,從而使得可以更詳細地刻畫多徑分量的統(tǒng)計分布特征。然而,這同時也意味著在對大量多徑分量進行統(tǒng)計建模過程更復(fù)雜。
大量的MIMO信道測量數(shù)據(jù)顯示,在實際環(huán)境中多徑分量是成簇分布的。多徑成簇這一特性可以在信道建模過程中加以利用,從而在保持建模準確性的前提下降低模型復(fù)雜度。最早出現(xiàn)的涵蓋多徑簇結(jié)構(gòu)的信道模型是SV(Saleh-Valenzuela)模型,在該模型中,多徑分量基于實測數(shù)據(jù)在時延域被分成了不同的簇。此外,有學者提出了一種更適合MIMO信道的幾何的隨機信道模型(GSCM),將SV模型中多徑時延簇延伸到了時延與角度兩個維度中。在過去20年中,多徑成簇的現(xiàn)象在許多環(huán)境中被廣泛觀測到,同時基于簇結(jié)構(gòu)的信道模型也被廣泛地應(yīng)用于標準化信道模型中,例如COST 259、COST 2100、3GPP空間分布信道模型(SCM)以及WINNER模型中。
雖然多徑成簇的概念在信道建模中被廣泛認可,但是建立合適的多徑分簇算法依舊是一個熱門的課題。在過去,通過人體肉眼鑒別開展多徑分簇的方法使用了很長一段時間。然而,即便人體視覺可以有效地從噪聲中鑒別多徑的結(jié)構(gòu)與模式,但是,這一方法面對海量測量數(shù)據(jù)則顯得過于繁瑣。因此,基于簇結(jié)果的信道建模需要一種通過精密設(shè)計的自動分簇算法。
雖然分簇算法(在機器學習領(lǐng)域多稱為“聚類算法”)在機器學習領(lǐng)域一直以來都是一個熱門研究課題,但在無線通信領(lǐng)域中信道多徑分簇問題仍屬于新興學科。由于描述實際傳播信道中多徑分量的參數(shù)有很多,包括功率、時延、角度等,并且這些參數(shù)都具有真實的物理含義以及不同的統(tǒng)計特性,因此,多徑分簇最大的挑戰(zhàn)就在于如何將這些參數(shù)的影響考慮在分簇算法內(nèi)。當只考慮功率和時延信息的情況下,存在一些多徑分簇算法,然而,此類算法僅在多徑分量的時延域范圍內(nèi)適用,無法用于MIMO信道(涵蓋多徑角度域分布特征)多徑分簇。
當前,考慮了所有多徑參數(shù)(功率、時延、角度)、適用于MIMO信道多徑分簇的算法主要歸納如下:在一文獻中,見N.Czink,P.Cera,J.Salo,E.Bonek,J.-P.Nuutinen,and J.Ylitalo,“A framework for automatic clustering of parametric MIMO channel data including path powers,”in Proc.IEEE VTC’06,2006,pp.1–5,K-Power-Means(KPM)算法被提出,該算法將多徑功率的影響在計算簇中心的過程中考慮了進來,并且使用了多徑距離來定義不同多徑分量之間的相似性。在另外一文獻中,見C.Schneider,M.Bauer,M.Narandzic,W.Kotterman,and R.S.Thoma,“Clustering of MIMO channel parameters-performance comparison,”in Proc.IEEE VTC’09,2009,pp.1–5,F(xiàn)uzzy c-means算法被改進并用于多徑分簇,研究表明,該算法在隨機初始化的條件下性能優(yōu)于KPM算法。
雖然過去十年對于無線信道多徑自動分簇算法的研究取得了一些進展,但是現(xiàn)有工作依舊具有以下局限性:
●多徑分量的許多參數(shù)的統(tǒng)計特征并未考慮在分簇算法中。不同于機器學習中人為生成的數(shù)據(jù),實際場景中的多徑信號是由物理環(huán)境所產(chǎn)生,并且具有確定的內(nèi)在物理特征。這些多徑分量的物理規(guī)律應(yīng)該在分簇算法中考慮進來。例如,許多測量顯示多徑簇的角度分布通常服從拉普拉斯分布,然而,該特性并未在現(xiàn)有的分簇算法設(shè)計中被考慮進來。
●既有算法中多徑簇的數(shù)目通常需要作為已知信息以輸入分簇算法。雖然存在許多驗證指標可以對簇的數(shù)目開展估計,但是任何指標都無法保證總能正確預(yù)測多徑簇數(shù)目。大多數(shù)的研究依舊運用視覺識別的方式在環(huán)境中得到最佳的簇數(shù)目,這大大降低了自動分簇算法的效率。
●大多數(shù)的分簇算法依舊需要許多人工輸入的預(yù)設(shè)參數(shù)。例如,在KPM算法中,簇的初始信息(時延和角度)需要被定義,并且時延與角度的權(quán)重參數(shù)也需要反復(fù)調(diào)整從而獲得合理的輸出結(jié)果,這些參數(shù)的定義往往非常主觀。此外,在實際的測量數(shù)據(jù)中找出合理的初始化參數(shù)本身也具有很高的難度。因此,有必要建立一種人為預(yù)設(shè)參數(shù)更少、更易于調(diào)整的多徑分簇算法。
技術(shù)實現(xiàn)要素:
本發(fā)明的目的是提供一種基于核功率密度的無線信道多徑分簇方法,其是一種全新的MIMO信道多徑分簇方法.
為此,本發(fā)明的目的是提供一種基于核功率密度的無線信道多徑分簇方法,信號由發(fā)射機歷經(jīng)多徑到達接收機,MIMO信道被建模為雙方向性信道,并且雙方向性脈沖響應(yīng)包括多徑的功率α、時延τ、離開角ΩT以及達到角ΩR,信道中的多徑信號呈現(xiàn)成簇現(xiàn)象,在同一個簇中的多徑信號擁有相似的功率、時延以及角度參數(shù),其特征在于,所有的多徑參數(shù)都利用高分辨率算法(例如,MUSIC、CLEAN、SAGE、RiMAX)從實際測試數(shù)據(jù)中進行估計,考慮在一個時間時刻內(nèi)M個簇中的T條多徑分量,而這些多徑分量由功率α、時延τ、DODΩT以及DOAΩR進行表示。
根據(jù)本發(fā)明,核密度考慮了多徑分量的統(tǒng)計特性,并且也考慮了多徑功率;
根據(jù)本發(fā)明,在密度估計過程中僅考慮了K個最近的多徑分量,從而能夠更好地識別多徑分量的本地密度變化,該方法可以有效服務(wù)于MIMO信道的多徑分簇,并且不需要簇的先驗信息(例如簇的數(shù)目以及初始位置等);
根據(jù)本發(fā)明,具有相對較低的計算復(fù)雜度,能夠滿足未來無線通信領(lǐng)域面向簇結(jié)構(gòu)的信道建模需求。
現(xiàn)有技術(shù)中,從來沒有人考慮過“多徑分量的統(tǒng)計分布特性”,這并非是因為以往受到計算手段(例如曾經(jīng)的計算尺、算盤、采用穿孔帶進行數(shù)據(jù)輸入的單板機、計算器、電子管計算機、以及IBM工作站等)的能力限制,而是因為“本領(lǐng)域的技術(shù)人員”一直沒有找到合適的方法去考慮它,不清楚如何在聚類問題中對它進行描述,也不清楚如果將它與聚類問題相結(jié)合。本發(fā)明創(chuàng)造性地提出了“核函數(shù)”這個解決技術(shù)問題的手段,才把“多徑分量的統(tǒng)計分布特性”成功地考慮了進來,即巧妙、又有效地解決了實時通訊領(lǐng)域的技術(shù)問題。
現(xiàn)有技術(shù)中,“多徑分量功率”的考慮方法方式與本發(fā)明截然不同,是在描述多徑信號空間間距的過程中把功率因子加權(quán)進來的,而本發(fā)明是在核函數(shù)里面引入了功率變量,變成了核功率密度。
因此,本發(fā)明同時考慮“多徑分量的統(tǒng)計分布特性”和“多徑分量功率”解決技術(shù)問題的兩個必要手段;而現(xiàn)有技術(shù)中沒有、也無法這樣做。
現(xiàn)有技術(shù)中,多徑分量的許多參數(shù)的統(tǒng)計特征并未考慮在分簇算法中,不是計算機技術(shù)沒有現(xiàn)在發(fā)達,以往數(shù)值計算能力有限(例如打算盤、穿孔紙帶計算機、單板機、計算器、386等),數(shù)學模型中考慮的參數(shù)多了無法得到數(shù)值解,必須對數(shù)學模型進行簡化,而是因為“本領(lǐng)域的技術(shù)人員”一直沒有認識到多徑信號參數(shù)的統(tǒng)計特征和物理規(guī)律,因此,現(xiàn)有技術(shù)的方法、體系有缺陷,無法想到本發(fā)明的技術(shù)方案。
現(xiàn)有技術(shù)中,多徑簇的數(shù)目通常需要作為已知信息輸入分簇算法;而本發(fā)明是基于密度的聚類算法,不需要知道簇的數(shù)目的初始值,不需要輸入簇的數(shù)目作為先驗信息。
采用“核功率密度”作為解決技術(shù)問題的手段是本發(fā)明首次提出的,實現(xiàn)本發(fā)明的技術(shù)構(gòu)思的難點至少包括:
1)核函數(shù)的引入:解決了多徑聚類中多徑統(tǒng)計特征無法涵蓋進來的問題;
2)核功率的加權(quán):通過在核函數(shù)中引入功率密度,實現(xiàn)了核功率密度這一概念的建立;
3)基于核功率密度的分簇方法設(shè)計:包括相對密度的計算,多徑核心點的搜索、基于高密度近鄰的分簇、基于連接圖的簇合并等。
總之,提出本發(fā)明的技術(shù)方案,需要付出創(chuàng)造性的勞動,克服一系列技術(shù)難關(guān);而且,本發(fā)明的技術(shù)方案確實產(chǎn)生了預(yù)料不到的技術(shù)效果。
附圖說明
圖1a-1d是基于仿真生成的信道下KPD多徑分簇算法實施過程示意圖。
圖2a-2d是基于仿真生成的信道下KPD多徑分簇算法實施過程示意圖。
圖3a-3d是基于仿真生成的信道下多徑分簇算法驗證示意圖。
圖4示出了多徑簇數(shù)目對F-測度的影響分析。
圖5示出了多徑簇內(nèi)角度擴展對F-測度的影響分析。
圖6a-6b示出了KPD算法參數(shù)對F-測度的影響分析。
圖7示出了本發(fā)明在信道探測儀中的實施流程。
具體實施方式
圖1a示出了原始仿真信道中的多徑信號,內(nèi)含5個多徑簇,分別標注為不同形狀;
圖1b是多徑密度ρ的示意圖,樣本點的亮度表示ρ值大小;
圖1c是多徑相對密度ρ*的示意圖,樣本點的亮度表示ρ*值大小,其中,5個實心正方形表示多徑核心點,即滿足ρ*=1的樣本點;
圖1d示出了基于KPD算法的多徑分簇結(jié)果,其中不同簇用不同形狀表示。
圖2a示出了原始仿真信道中的多徑信號,內(nèi)含7個多徑簇,分別標注為不同形狀;
圖2b是多徑密度ρ的示意圖,樣本點的亮度表示ρ值大小;
圖2c是多徑相對密度ρ*的示意圖,樣本點的亮度表示ρ*值大小,其中,7個實心正方形表示多徑核心點,即滿足ρ*=1的樣本點;
圖2d示出了基于KPD算法的多徑分簇結(jié)果,其中不同簇用不同形狀表示。
圖3a示出了原始仿真信道生成的多徑簇,不同簇分別標注為不同形狀;
圖3b是基于KPD算法的多徑分簇結(jié)果;
圖3c是基于KPM算法的多徑分簇結(jié)果;
圖3d是基于DBSCAN算法的多徑分簇結(jié)果。
(1)無線信道描述
首先,對無線信道及信道多徑參數(shù)進行描述。在任何無線信道中,信號通常由發(fā)射機歷經(jīng)多徑到達接收機。MIMO信道可以被建模為雙方向性信道,并且可以由雙方向性脈沖響應(yīng)進行描述,該脈沖響應(yīng)包括了多徑的功率α、時延τ、離開角(Direction of Departure,DOD)ΩT以及達到角(Direction of Arrival,DOA)ΩR。如技術(shù)背景中所述,信道中的多徑信號呈現(xiàn)成簇現(xiàn)象,在同一個簇中的多徑信號擁有相似的功率、時延以及角度參數(shù)。對于任意時刻,涵蓋簇結(jié)構(gòu)的雙方向性MIMO信道脈沖響應(yīng)h可以表示為:
其中,M為簇的數(shù)目,Nm為第m個簇中多徑的數(shù)目,am,n與φm,n分別是第m個簇中第n條多徑的幅度和相位,τm、ΩT,m、ΩR,m分別是第m個簇的時延、DOD與DOA,而τm,n、ΩT,m,n與ΩR,m,n則分別是第m個簇中第n條多徑的附加時延、附加DOD與附加DOA。δ(·)是脈沖函數(shù),t是時間。
在公式(1)中,所有的多徑參數(shù)都可以利用高分辨率算法(例如,MUSIC、CLEAN、SAGE、RiMAX)從實際測試數(shù)據(jù)中進行估計。如公式(1)所示,考慮的是在一個時間時刻內(nèi)M個簇中的T條多徑分量,而這些多徑分量則可以由功率α、時延τ、DODΩT以及DOAΩR進行表示。一個時間時刻內(nèi)所有多徑分量的集合表示為Φ,每一個多徑分量則用x來代替。
(2)基于核功率密度(Kernel-Power-Density,KPD)的信道多徑分簇算法
為了克服現(xiàn)有多徑分簇算法的不足,本發(fā)明提出了基于核功率密度(Kernel-Power-Density,KPD)的多徑分簇算法。KPD算法的具體內(nèi)容如下所示。
a)針對每一個多徑樣本x,利用距離它最近的K個多徑分量計算其密度ρ:
其中,y是任意的一個多徑分量并且y≠x。Kx是距離多徑x的K個最近的多徑的集合。σ(·),y∈Kx表示在(·)域中K個最近的多徑分量的標準差。在(2)中,在時延域采用了高斯核密度,因為物理信道中的時延并未呈現(xiàn)某種特定的分布;在角度域采用了拉普拉斯核密度,因為大量實際測試表明多徑信號在角度域呈現(xiàn)拉普拉斯分布。(2)中的項exp(α)表明多徑分量的功率越強,密度越大,這也符合信道的物理特征。exp(α)項可以將不同多徑分量之間的功率差放大到一個合理的水平,并且,在核密度中考慮了功率后,分簇結(jié)果中的多徑簇心也更加靠近功率較強的點。
b)針對每一個多徑樣本點,利用它的K個最近的多徑分量計算其相對密度ρ*:
利用相對密度,可以在不同區(qū)域?qū)Χ鄰矫芏冗M行歸一化,從而確保不同的簇具有相似的密度值,因而可以更好地識別出功率相對較弱的簇。由(3)可知ρ*∈[0,1]。
c)對于每一個多徑樣本x,如果ρ*=1,則把它標記為多徑核心點因此可以得到多徑核心點的集合如下:
多徑核心點可以被設(shè)定為初始的多徑簇心。
d)對每一個多徑樣本x,定義其高密度最近鄰為:
其中,d代表歐式距離。與DBSCAN算法中的密度可達概念相似,將每一個多徑分量與其高密度最近鄰相互連接,并建立如下映射路徑:
因此,可進一步得到如下連接圖ξ1:
ξ1:={px|x∈Φ} (7)
需要指出兩個多徑分量可以通過多條映射路徑相互連接。不同的多徑分量如果在連接圖ξ1中與同一個多徑核心點相連通,則它們被分到同一個多徑簇中。
e)對于任意一個多徑分量,將其與它的K個最近的多徑分量相互連接,則可建立如下映射路徑:
qx:={x→y,y∈Kx} (8)
因此,可進一步得到如下連接圖ξ2:
ξ2:={qx|x∈Φ} (9)
如果:i)兩個多徑核心點在連接圖ξ2中相互可達;ii)在這兩個多徑核心點相互連通的任意路徑上,存在某條路徑上的樣本點始終滿足ρ*>χ(其中χ為密度門限),就將這兩個多徑核心點所對應(yīng)的簇合并為一個簇。
在KPD算法中,需要定義兩個參數(shù):K和χ。其中,參數(shù)K決定了在計算密度的過程中要使用多少本地多徑信號從而獲得連接圖ξ2。K越小,則本地多徑密度的波動對于分簇結(jié)果的敏感性就越大,這等效于縮小了本地區(qū)間的范圍。本算法使用并給出了一種啟發(fā)式的解釋:總體來講,每一個簇內(nèi)有個樣本點,然而,本發(fā)明算法要求在每個簇中的任意兩個多徑分量在ξ2上可達,從而使得簇具有一定的緊湊度。然而,通常很難達到這一效果(即每個簇中的任意兩個多徑分量在ξ2無法保證可達),因此,使用了來減小本地區(qū)域從而確保簇具有一定的緊湊度。
參數(shù)χ決定了兩個簇是否可以被合并。χ越大,簇的數(shù)目就越多。簡單來講,建議將χ設(shè)定為0.8,從而在驗證過程中具有最合理的分簇性能,這是因為較大的x可以確保簇與簇之間的分離度較高。
(3)KPD算法原理分析及討論
(3.1)為什么使用核密度
對聚類分析中的目標樣本點,每一個數(shù)據(jù)點的變化規(guī)律可以用波動函數(shù)進行建模,因此,基于波動函數(shù)的累加所建立起的密度函數(shù)可以使得所產(chǎn)出的分簇結(jié)果具有與波動函數(shù)相似的數(shù)學規(guī)律。在無線信道多徑分簇中,可以利用核函數(shù)將多徑在某個維度的分布規(guī)律融入分簇過程中,所產(chǎn)出的多徑分簇結(jié)果在相應(yīng)空間內(nèi)的分布規(guī)律也會趨近于核函數(shù)的表現(xiàn)形式。值得指出的是,(2)中所定義的多徑核密度具有非常靈活性的表現(xiàn)形式:在3D MIMO測量的條件下,可以再在(2)中加入俯仰角所對應(yīng)的核密度因子;如果多徑的角度信息無法從信道數(shù)據(jù)中獲得,也可以將相應(yīng)的核密度因子從(2)中刪除。
(3.2)為什么在多徑密度計算中僅考慮K個最近的多徑分量
原因在于,要保證估計的多徑密度對于局部區(qū)域數(shù)據(jù)密度的變化具有足夠的敏感度,換言之,距離目標樣本越近的多徑信號對其密度估計的貢獻越大。
(3.3)為什么在多徑密度計算中使用“相對密度”
原因與使用K個最近的多徑分量相類似:相對密度有助于更清晰的反映本地區(qū)域多徑密度的變化情況,從而使得每個多徑簇更易于辨識。
(3.4)為什么需要進行簇的合并
真實環(huán)境中的多徑簇都存在小尺度衰落,每個簇內(nèi)多徑信號的功率存在一定范圍的動態(tài)變化。基于多徑核心點所確立的初始多徑簇往往數(shù)量過多。因此,需要將彼此距離相對較近的簇進行合并,以克服由于多徑簇能量衰落所造成分簇數(shù)量過多的情況。
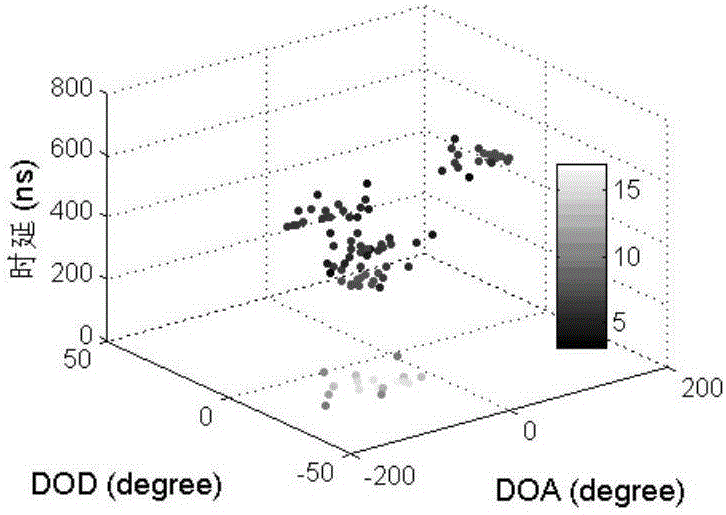
(4)算法驗證
本發(fā)明利用基于實測數(shù)據(jù)所建立的SCME MIMO信道仿真模型生成原始信道數(shù)據(jù),對KPD算法進行驗證。SCME信道模型被用于生成涵蓋功率、時延、角度信息的多徑分量。出于簡化考慮,在信道仿真中忽略掉多徑俯仰角維度的信息。
圖1a-1d和圖2a-2d顯示了基于仿真生成的信道下KPD多徑分簇算法實施的過程和處理細節(jié)。在圖1a-1d中,基于SCME MIMO信道模型仿真生成了5個多徑簇,其中簇3和簇4離的較近。如圖1b所示,密度ρ的動態(tài)范圍較大,很難基于ρ的變化識別出簇1和簇3。然而,通過對本地多徑密度的歸一化(即相對密度ρ*的計算),可以很容易地借助多徑核心點識別出不同的簇(如圖1c所示)。最終的分簇結(jié)果如圖1d所示,其準確度達到100%。
在圖2a-2d中,基于SCME MIMO信道模型仿真生成了7個多徑簇,其中簇4、簇5、簇6、簇7彼此離的較近。如圖2b和圖2c所示,局部區(qū)域多徑密度的變化特征可以從相對密度值ρ*中較好地提取出來。借助KPD算法,圖2a-2d中所有的7個多徑簇均被成功找出。
圖3a-3d顯示了基于SCME MIMO原始仿真信道生成的多徑簇以及采用不同算法的分簇結(jié)果,生成了10個擁有不同時延與角度特征的多徑簇。從圖3a-3d中可以看到,在KPM算法中DOD為-150至-100度以及DOA為0至180度的多徑信號分簇結(jié)果不正確;而在DBSCAN算法中多徑簇的數(shù)目判定錯誤;如圖3b所示,本發(fā)明中的KPD算法分簇準確率達到100%。
此外,還在不同的多徑簇分布特征下測試了分簇算法的性能。考慮了以下兩個條件:多徑簇的數(shù)目、簇的角度擴展。直觀來看,簇的數(shù)目以及簇的角度擴展越大,分簇算法的性能則會降低。本發(fā)明使用魯棒性較好的分簇結(jié)果評價指標“F-測度”來評估分簇算法的性能。這里,定義“簇”來代表原始信號中真實存在的簇,定義“類”來代表分簇算法輸出的分簇結(jié)果。因此,F(xiàn)-測度可定義為:
其中,li為類i里元素的數(shù)目,并且:
P(i,j)=lij/lj (11)
這里,R(i,j)和P(i,j)代表簇i和簇j的召回率和精確率,lij代表簇j中類i內(nèi)元素的數(shù)目,lj代表簇j中元素的數(shù)目。F-測度的值介于0和1之間,該值越大代表分簇性能越好。
首先,檢驗了簇的個數(shù)對于分簇算法準確性的影響。依然使用SCME MIMO信道模型來生成多徑信號,并且在仿真中使用了不同的簇的數(shù)目。對于每一個簇的數(shù)目,仿真了300個隨機的多徑信道以獲得更具普適性的結(jié)果。圖4給出了三種分簇算法的性能對比。從圖4中可以看出,本發(fā)明提出的KPD算法F-測度數(shù)值最高,因此具有最好的分簇性能,同時,在簇的數(shù)目逐漸增大的情況下,F(xiàn)-測度的值僅有輕微的降低。KPM和DBSCAN算法僅在原始簇的數(shù)目較小的情況下具有較好的性能,當簇的數(shù)目增大,它們的F-測度值顯著減小。
其次,測試了多徑簇的角度擴展對分簇準確性的影響。在仿真中,將信道內(nèi)多徑簇的數(shù)目固定為6個,通過在多徑的DOA和DOD中加入方差為{1°,2°,...,30°}的高斯噪聲,得到了具有不同角度擴展的多徑簇。對于每一種情況同樣仿真了300個隨機信道以獲得更具普適性的結(jié)果。圖5給出了簇的角度擴展對于F-測度的影響。從圖5中可以發(fā)現(xiàn),隨著簇角度擴展的增大,F(xiàn)-測度值逐漸減小。而KPD算法對不同大小的簇均具有較好的分簇性能,這是因為,在KPD算法中使用了拉普拉斯核密度以反映多徑在角度域的分布規(guī)律,而SCME標準模型同樣也假設(shè)多徑在角度維度服從拉普拉斯分布。
接下來,討論KPD算法中參數(shù)K和參數(shù)χ的選取對于分簇性能的影響。圖6a顯示了選取不同的K值對分簇結(jié)果F-測度的影響(SCME MIMO仿真基于300個隨機生成的信道,且簇的數(shù)目固定為6)。從圖6a中可以看出,F(xiàn)-測度隨著K值的增加先增大、后減小。這是因為,較小的K無法正確反應(yīng)局部區(qū)域的多徑密度,而較大的K則會過度平均掉本地區(qū)域內(nèi)多徑密度的變化特征。在圖6a的仿真中,的情況對應(yīng)著較大的F-測度值,因此,在KPD算法中建議采用作為參數(shù)預(yù)設(shè)值。圖6b給出了不同χ值對于分簇結(jié)果F-測度的影響(SCME MIMO仿真基于300個隨機生成的信道,且簇的數(shù)目固定為12)。從圖6b中可以看出,F(xiàn)-測度隨著χ的增加基本呈現(xiàn)遞增的趨勢。這是因為,較大的χ值減少了不同簇之間錯誤的合并。大量仿真驗證表明,當χ>0.8時F-測度的值比較穩(wěn)定。因此,建議在KPD算法中使用x=0.8。
最后,使用計算機處理時間討論不同分簇算法的計算復(fù)雜度。對于圖3中一個時間片段下多徑信號分簇的處理,KPD、KPM、DBSCAN算法的處理時間分別為0.40秒、1.14秒、0.25秒(使用Matlab 2012,4 GB RAM電腦)。這表明KPD算法具有相對較低的復(fù)雜度。雖然DBSCAN算法擁有最低的計算復(fù)雜度,但其同樣擁有最差的分簇準確度。
綜上所述,本發(fā)明所提出的KPD分簇算法具有最高的分簇準確度以及相對較低的計算復(fù)雜度。
針對無線通信中信道內(nèi)的多徑信號,本發(fā)明公開了一種基于核功率密度的多徑分簇算法,即KPD算法,服務(wù)于多徑信號簇結(jié)構(gòu)統(tǒng)計模型的開發(fā)。主要特征如下:
1)它使用核密度的方式將多徑的統(tǒng)計分布特征與分簇過程相融合,具有較好的靈活性;
2)在對多徑密度進行估計的過程中,KPD引入相對密度的定義,并且僅考慮K近鄰內(nèi)的多徑信號,這使得算法可以更為有效地識別局部區(qū)域多徑密度的變化特征;
3)KPD采用了多徑簇合并機制,有效地改善了多徑分簇性能;
4)KPD算法的預(yù)設(shè)參數(shù)較少并且魯棒性較好,當環(huán)境中多徑簇數(shù)目較多并且簇內(nèi)的多徑分布較為離散時,KPD算法性能依然保持在較高的水準;
5)算法的計算復(fù)雜度較低。
本發(fā)明算法的性能得到了基于實測數(shù)據(jù)所建立的仿真模型的驗證。
本發(fā)明可以用于對信道數(shù)據(jù)分簇研究的開展以及4G、5G通信中基于簇結(jié)構(gòu)信道模型的開發(fā)。
該發(fā)明可以應(yīng)用于信道探測儀(channel sounder),實現(xiàn)對信道探測儀設(shè)備所采集的信道數(shù)據(jù)的實時處理。信道探測儀可以用內(nèi)部FPGA芯片,借助本發(fā)明實時地分析所采集多徑數(shù)據(jù)的成簇效應(yīng),輸出分簇結(jié)果,并依據(jù)分簇結(jié)果實現(xiàn)設(shè)備內(nèi)對信道統(tǒng)計特征的計算、分析、顯示等功能。
下面結(jié)合上述發(fā)明內(nèi)容對該分簇算法在信道探測儀設(shè)備中的實施方式作詳細說明。應(yīng)該強調(diào)的是,下述說明和參數(shù)選取僅僅是示例性的,而不是為了限制本方法的范圍及其應(yīng)用。
以配置有多天線的信道探測儀為例,本發(fā)明具體實施步驟如下(實施流程如圖7所示):
步驟1:利用多天線信道探測儀設(shè)備對某一場景下的信道數(shù)據(jù)進行實時采集,通過數(shù)字下變頻和模數(shù)轉(zhuǎn)換操作,獲得連續(xù)時刻下信道沖激響應(yīng)數(shù)據(jù),通過先入先出(FIFO)的方式實時地存放在“磁盤陣列A區(qū)”中。
步驟2:首先對“磁盤陣列A區(qū)”中的原始采樣數(shù)據(jù)進行串-并轉(zhuǎn)換,然后通過E個“參數(shù)估計”處理器同時對E路并行的基帶原始數(shù)據(jù)進行參數(shù)估計,獲得每一路并行數(shù)據(jù)(其對應(yīng)步驟1中不同時刻的測試數(shù)據(jù))所對應(yīng)的多徑樣本信號,之后進行并-串轉(zhuǎn)換,存放在“磁盤陣列B區(qū)”中。由于使用了多個“參數(shù)估計處理器”,使得有新數(shù)據(jù)進入“磁盤陣列A區(qū)”時,“參數(shù)估計1”處理器已經(jīng)完成了對之前數(shù)據(jù)的估計處理,這樣保證了系統(tǒng)處理的實時性。此外,經(jīng)并-串轉(zhuǎn)換后存放在“磁盤陣列B區(qū)”中的只是多徑參數(shù),它比原始信道數(shù)據(jù)占用空間更小,更易于實時處理。
若信道探測器配置有多天線射頻單元,則所存儲的多徑樣本包含多徑的幅度、時延、角度3方面信息;若信道探測儀配置僅為單天線射頻單元,則所存儲的多徑樣本包含多徑的幅度、時延2方面信息。本章節(jié)以配置有多天線射頻單元的信道探測儀所存儲的數(shù)據(jù)為例,對本發(fā)明的實施方法進行說明;本發(fā)明在單天線射頻單元的信道探測儀上的實施方法可以以此類推。
步驟3:在信道探測儀內(nèi)部的處理器中預(yù)先分配出8個處理單元,用于后續(xù)FPGA分簇計算處理。前后處理單元之間利用移位寄存器傳遞數(shù)據(jù),各處理單元共享系統(tǒng)時鐘且并行處理。
步驟4:將“磁盤陣列B區(qū)”中的多徑信號讀入信道探測儀內(nèi)部“處理單元1”,以矩陣單元的形式依次存放。假設(shè)“處理單元1”里所存放的多徑信號總數(shù)目為T,這些信號均獨立地存放在“處理單元1”里的T個不同的矩陣單元中。將每一個矩陣單元中的多徑信號映射到功率-時延-角度的三維邏輯空間中,并在“處理單元2”中存儲每個多徑數(shù)據(jù)的空間坐標。
步驟5:在“處理單元2”中設(shè)置一個計數(shù)器,其初值為0。在“處理單元2”所存儲的這個邏輯空間內(nèi),對任意一個多徑信號x以歐氏距離的方式依次搜索距離它最近的多徑信號,每搜到一個多徑信號,則將其存入“處理單元3”中,同時令“處理單元2”中計數(shù)器加1。若“處理單元2”中計數(shù)器值等于則停止對“處理單元2”中數(shù)據(jù)的搜索。
步驟6:利用“處理單元3”中所存放的所有多徑信號以及“處理單元2”中多徑信號x數(shù)據(jù),計算x的原始核功率密度,存儲在信道探測儀內(nèi)“處理單元4”中。
步驟7:基于“處理單元3”中的數(shù)據(jù)在內(nèi)部處理器中計算x的相對核功率密度,刪除掉“處理單元4”中原先存放的原始核功率密度數(shù)據(jù),將新的相對核功率密度數(shù)據(jù)存放在“處理單元4”中。所存儲的相對核功率密度代表了該多徑信號在后處理中的重要程度,其值越大,表明該多徑信號在后續(xù)信道探測儀的內(nèi)部處理中所占的權(quán)重越大。
步驟8:將“處理單元2”中的計數(shù)器值歸零,重復(fù)步驟5-7,直至完成對“處理單元2”中所有多徑信號相對核功率密度的計算。將所獲得的相對核功率密度數(shù)據(jù)全部存放在“處理單元4”中。
步驟9:在“處理單元4”中搜索相對核功率密度為1的多徑信號。將所有這些相對核功率密度為1的多徑信號的編號以及其在“處理單元2”中所對應(yīng)的空間坐標存儲在“處理單元5”里。這些多徑信號是后續(xù)處理中建立多徑成簇關(guān)系的初始中心點,稱之為“初始多徑核心點單元”。
步驟10:在信道探測儀的“處理單元2”里,借助空間坐標及“處理單元4”數(shù)據(jù)搜索任意多徑信號x附近,距離它最近、相對核功率密度又比它大的多徑信號,將這個多徑信號稱之為x的高密度最近鄰信號,二者存在“邏輯連通關(guān)系”,并將其編號存放在“處理單元6”的高密度最近鄰矩陣中。
步驟11:重復(fù)步驟10,直至完成對“處理單元2”里所有數(shù)據(jù)的計算,將所有獲得的高密度最近鄰信號編號及“邏輯連通關(guān)系”編號存放在“處理單元6”的高密度最近鄰矩陣中。
步驟12:通過數(shù)據(jù)檢索的方法,對每一個存放在存儲器里的多徑數(shù)據(jù)進行排查判決,建立存儲器中所有存放的多徑信號之間的初始成簇關(guān)系。設(shè)備處理器內(nèi)部的判決依據(jù)如下:“處理單元2”中不同的多徑信號如果可以依照“處理單元6”中的高密度最近鄰邏輯連通關(guān)系找到一條通往“處理單元5”中同一個“初始多徑核心點單元”的邏輯通路,那么,這些多徑信號屬于這個“初始多徑核心點單元”的內(nèi)部數(shù)據(jù)。這樣,完成了對“處理單元2”中所有多徑信號歸屬關(guān)系的初始分簇。將每一個多徑信號的分簇編號存放在“處理單元7”中。
步驟13:繼續(xù)通過數(shù)據(jù)檢索的方法,對“處理單元7”中的每個多徑信號的分簇編號進行更新。設(shè)備處理器內(nèi)部的更新依據(jù)如下:如果“處理單元5”中的兩個“初始多徑核心點單元”在步驟5所描述的“邏輯鄰域”中相互存在相連關(guān)系,且二者的相連關(guān)系中存在一條邏輯連接路徑上每一個多徑信號數(shù)據(jù)節(jié)點的相對核功率密度值均大于0.8,那么就將這兩個“初始多徑核心點單元”所對應(yīng)的全部元素在“處理單元7”中的值更新為同一個新的編號值。
步驟14:找出“處理單元7”中所有出現(xiàn)的編號值,統(tǒng)計它們的總個數(shù),并重新將它們按順序序列編排,刪除不連續(xù)的序號。將所得結(jié)果存入“處理單元8”中。
步驟15:分簇算法結(jié)束,將信道探測儀“處理單元8”中的結(jié)果存入“磁盤陣列C區(qū)”中,并在處理器中依據(jù)“磁盤陣列B區(qū)”和“磁盤陣列C區(qū)”中數(shù)據(jù)對多徑信號的分簇結(jié)果進行圖示化處理(類似于圖1、圖2),實時地顯示在信道探測儀的顯示屏窗口中。
根據(jù)本發(fā)明,通過核密度函數(shù)將真實環(huán)境中多徑分量的統(tǒng)計分布特性以及多徑分量功率同時考慮進來,很好地解決了傳統(tǒng)算法多徑簇的先驗信息未知的難題,進而服務(wù)于基于簇結(jié)構(gòu)的無線通信信道建模以及通信系統(tǒng)的設(shè)計,具有很強的適用性及實用性。
以上所述,僅為本發(fā)明較佳的實施方式,但本發(fā)明的保護范圍并不局限于此,本領(lǐng)域的技術(shù)人員在本發(fā)明描述的技術(shù)范圍內(nèi),可輕易想到的變化或替換,都應(yīng)涵蓋在本發(fā)明的保護范圍之內(nèi)。因此,本發(fā)明的保護范圍應(yīng)該以所附權(quán)利要求書的保護范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!
- 定轉(zhuǎn)子安裝結(jié)構(gòu)和風機系統(tǒng)的制造方法與工藝
- 一種永磁電機轉(zhuǎn)子沖片結(jié)構(gòu)的制造方法與工藝
- 定子安裝裝置、定子安裝結(jié)構(gòu)和風機系統(tǒng)的制造方法
- 一種混合儲能電源瞬時功率控制系統(tǒng)的制造方法與工藝
- 硅碳復(fù)合材料及其制備方法和應(yīng)用與流程
- 一種納米Ag復(fù)合焊膏LED光源的陶瓷基板及制備方法與流程
- 一種復(fù)合鈍化層柵場板GaN HEMT元胞結(jié)構(gòu)及器件的制造方法與工藝
- 一種疊層封裝雙面散熱功率模塊的制造方法與工藝
- 一種低寄生電感功率模塊及雙面散熱低寄生電感功率模塊的制造方法與工藝
- 一種超級電容器電極材料及其制備方法與流程
- 一種應(yīng)用于高功率密度場合的高頻交流電源供配電系統(tǒng)的制作方法與工藝
- 一種高功率密度的容錯永磁游標直線電機的制作方法與工藝
- 一種高功率密度的鋅鎳二次電池的制備方法與流程
- 一種高功率密度pemfc電堆專用極板制造方法
- 一種結(jié)合了參考長度和用戶功率譜密度的上行功率下調(diào)方法
- 數(shù)字用戶線收發(fā)器發(fā)送功率譜密度整形方法
- 優(yōu)化遠程部署線路的發(fā)射功率譜密度(psd),確保頻譜兼容性的制作方法
- 用于提高電力貓功率譜密度的家用電器外部前端濾波器的制造方法
- 通過測量功率譜密度(psd)和循環(huán)譜檢測包含正弦波成分的信號的制作方法
- 一種解決ofdma系統(tǒng)終端功率譜密度不可控的方法