虛擬人臉動畫的生成方法及裝置與流程
本發明屬于人工智能技術領域,尤其涉及一種虛擬人臉動畫的生成方法及裝置。
背景技術:
隨著人工智能技術的進步,虛擬個人助手如Apple Siri、Google Assistant、以及Microsoft Cortana等已逐步參與到人們的生活中。目前大多數的虛擬個人助手都只能單純地使用語音與用戶交流,而沒有一個具體的視覺動畫形象,因此,與真實世界中人與人之間的交流依然存在一定的區別。對于電視機、個人電腦、手機等可提供音視頻輸出的設備而言,創建一個看得見且聽得著的虛擬個人助手將是人工智能技術發展的一個重要趨勢。
現有的虛擬人臉動畫主要基于語音識別技術或基于真實表演者模擬的方式來生成。基于語音識別技術的虛擬人臉動畫生成方法大多只能生成與語音同步的嘴唇運動,真實度較低;基于真實表演者模擬的方式來生成的虛擬人臉動畫,其需要真實表演者的介入,并且還需要提供昂貴、復雜的動作捕捉設備方可實現,因此,此種虛擬人臉動畫的生成方法成本過高,從而導致其應用范圍過于狹窄,難以推廣使用。
綜上,現有的虛擬人臉動畫的生成方法存在真實度較低、成本過高以及應用范圍過于狹窄的問題。
技術實現要素:
本發明實施例提供一種虛擬人臉動畫的生成方法及裝置,旨在解決目前虛擬人臉動畫的真實度較低、成本過高以及應用范圍過于狹窄的問題。
本發明實施例是這樣實現的,一種虛擬人臉動畫的生成方法,包括:
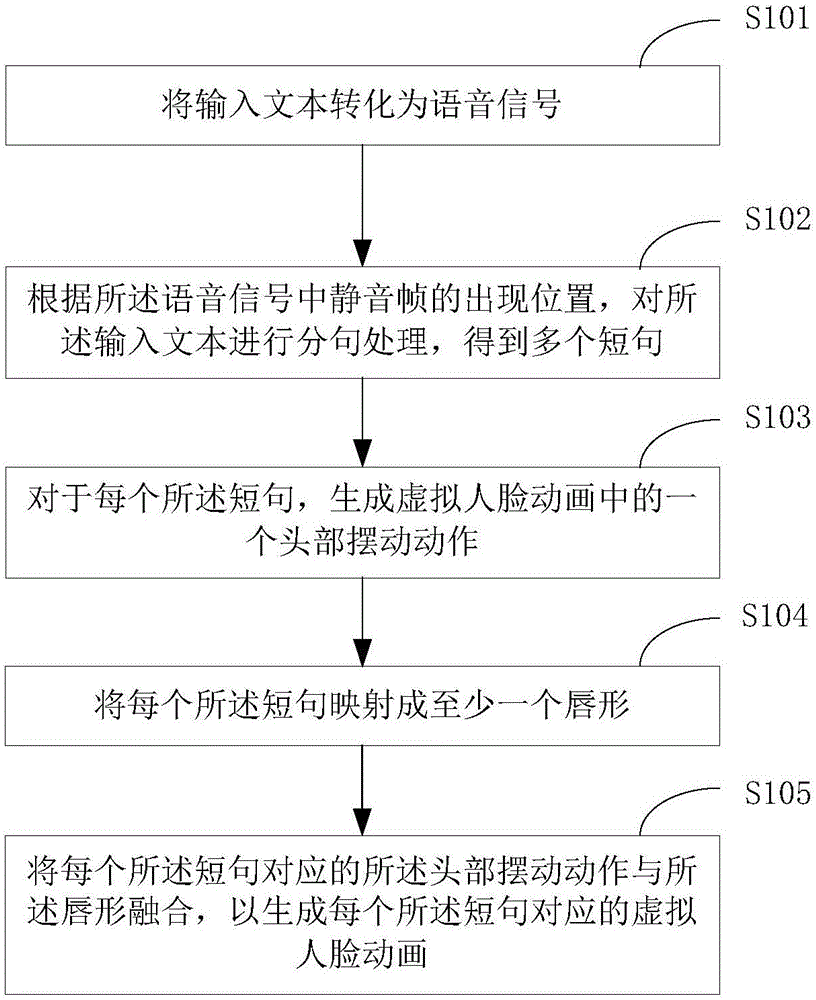
將輸入文本轉化為語音信號;
根據所述語音信號中靜音幀的出現位置,對所述輸入文本進行分句處理,得到多個短句;
對于每個所述短句,生成虛擬人臉動畫中的一個頭部擺動動作;
將每個所述短句映射成至少一個唇形;
將每個所述短句對應的所述頭部擺動動作與所述唇形融合,以生成每個所述短句對應的虛擬人臉動畫。
本發明實施例的另一目的在于提供一種虛擬人臉動畫的生成裝置,包括:
第一獲取單元,用于將輸入文本轉化為語音信號;
分句單元,用于根據所述語音信號中靜音幀的出現位置,對所述輸入文本進行分句處理,得到多個短句;
生成單元,用于對于每個所述短句,生成虛擬人臉動畫中的一個頭部擺動動作;
映射單元,用于將每個所述短句映射成至少一個唇形;
融合單元,用于將每個所述短句對應的所述頭部擺動動作與所述唇形融合,以生成每個所述短句對應的虛擬人臉動畫。
本發明實施例基于文本與語音結合的方式來生成虛擬人臉動畫,根據輸入文本中的每個短句,生成頭部擺動動作以及唇形,為用戶提供了更接近現實的視覺感官效果,避免了最后得到的虛擬人臉動畫僅包含唇形信息,提高了虛擬人臉動畫的真實性。此外,本發明實施例提供的虛擬人臉動畫的生成方法無需依賴昂貴、復雜的設備來實現,從而降低了成本,擴大了虛擬人臉動畫的應用范圍,促進了人工智能技術的發展。
附圖說明
圖1是本發明實施例提供的虛擬人臉動畫的生成方法實現流程圖;
圖2是本發明實施例提供的虛擬人臉動畫的生成方法S102的具體實現流程圖;
圖3是本發明實施例提供的虛擬人臉動畫的生成方法S104的具體實現流程圖;
圖4是本發明另一實施例提供的虛擬人臉動畫的生成方法實現流程圖;
圖5是本發明另一實施例提供的虛擬人臉動畫的生成方法S401的具體實現流程圖;
圖6是經過語音識別模型處理得到的語音幀中各音素的出現概率示意圖;
圖7是本發明又一實施例提供的虛擬人臉動畫的生成方法實現流程圖;
圖8是本發明實施例提供的虛擬人臉動畫的生成裝置的結構框圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
在本發明實施例中,虛擬人臉動畫可以顯示在計算機、筆記本電腦、手機、平板電腦、VR(Virtual Reality)眼鏡等終端中。根據終端所提供的虛擬個人助理(VPA)應用,通過自然語言處理和語義分析技術,可以接受用戶發出的語音請求,以視頻畫面中所顯示的具體人物來回答問題,并提供智能推薦,就像有一個面對面的“真人”在與使用該VPA應用的用戶進行互動。
圖1示出了本發明實施例提供的虛擬人臉動畫的生成方法實現流程圖,詳述如下:
在S101中,將輸入文本轉化為語音信號。
輸入文本,是指以書面形式或以文字表達的方式描繪出來的具體數據信息。一個輸入文本可以是一個詞語、一個句子、一個段落或者一個篇章。
本實施例中,輸入文本為VPA應用在后臺數據庫或存儲器中所存儲的任一訓練文本。VPA應用接收到用戶發出的交互信息時,能夠從預存儲的多個訓練文本中搜索出對應的應答信息,并執行返回,則預存儲的的應答信息即為輸入文本。
除了VPA應用所對應的輸入文本外,本實施例中的輸入文本還可以是任意環境下的文本,例如書本中的一個段落。
得到每個輸入文本后,將基于書面形式的輸入文本轉化為基于音頻形式的語音信息。該語音信息為人造語音,通過機械的、電子的方法而產生。
將輸入文本輸入文-語轉換軟件工具中,可直接輸出上述輸入文本對應的語音信號,實現了文字到語音的轉換功能。該軟件工具例如可以是百度語音、貍窩軟件、TextAloud、語音合成助手等。
在S102中,根據所述語音信號中靜音幀的出現位置,對所述輸入文本進行分句處理,得到多個短句。
在本實施例中,對作為準穩態信號的語音信號進行信號分幀,分幀后得到的每個語音幀為固定長度,如0.1s。
語音幀可分為有效語音幀以及靜音幀。靜音幀無法與輸入文本中的任一字符對應,僅作為一個“空語音”存在。除了靜音幀之外的語音幀皆為有效語音幀。
以時長來表示語音信號的長度時,在每個時間點均能夠對應獲得語音信號中的一個語音幀,則該時間點即為語音幀的出現位置。根據語音信號中每個靜音幀的出現位置,對輸入文本進行分句處理,從而實現將一個輸入文本劃分為多個短句,每個短句包含若干個輸入文本中的連續字符。
作為本發明的一個實施例,S102具體如下:
在S201中,將所述語音信號分解成多個語音幀,所述多個語音幀包括所述靜音幀以及音素幀。
將整段的語音信號切分成長度相同的多個短語音信號,每個短語音信號即為一個語音幀。其中,一個語音幀可能是靜音幀,也可能是音素幀。
在S203中,對所述輸入文本進行分詞處理,并獲取每個分詞對應的多個所述音素幀。
輸入文本可看作一個包含若干字符且各個字符有序排列的字符序列,利用預設的分詞算法,對該字符序列切分成一個一個單獨的字詞。分詞處理完成后,將得到輸入文本中所包含的多個分詞,每個分詞由一個或多個上述字符組成。
在輸入文本對應的語音信號中,由于每個語音幀都是根據輸入文本中字符的音素而自動合成產生的,因此,對于每個分詞,能夠對應地在該語音信號中匹配到多個音素幀。
在S204中,若相鄰的兩個分詞分別對應的多個所述音素幀之間存在一個或多個靜音幀,則獲取所述一個或多個靜音幀的總時長。
依照分詞在輸入文本中出現的先后順序,對上述輸入文本中的每個分詞進行排序。排序后,提取連續出現的兩個分詞,則其為相鄰的兩個分詞,且分別稱為第一分詞、第二分詞。通過S203獲得第一分詞對應的且連續出現的多個語音幀,稱為第一語音幀序列,獲得第二分詞對應的且連續出現的多個語音幀,稱為第二語音幀序列。此時,判斷第一語音幀序列與第二語音序列之間是否存在有靜音幀。
若第一語音幀序列與第二語音序列之間存在靜音幀,則可能是單個靜音幀,也可能是多個連續的靜音幀,因此,需要獲取各個靜音幀的總時長,即靜音時長。
在S205中,當所述總時長大于第一預設閾值時,將相鄰的兩個分詞分別劃分至相鄰的兩個短句中。
在本實施例中,第一預設閾值為一個時間長度值。通常,一個正常人因朗讀文本而發出語音時,在朗讀過程中會具有一定的韻律感,具體表現為在不同的字詞之間會有短暫停頓,則第一預設閾值描述了正常情況下停頓時長的閾值,并預設在系統中。判斷靜音時長是否大于該第一預設閾值,若靜音時長大于該第一預設閾值,則表示此處應當為人造語音中一小段的停頓時間,因此,以靜音幀為分割點,將第一語音幀序列與第二語音幀序列分開,則第一語音幀序列對應的第一分詞與第一語音幀序列對應的第二分詞也能夠相應地被分離。分離后的第一分詞與第二分詞分別位于連續出現的兩個短句中。
其中,任一短句中包含有一個或多個分詞,每個分詞對應的語音幀序列之間并不存在靜音幀,或者靜音時長未超過第一預設閾值。
在S206中,若劃分得到的任意一個所述短句的字符總數大于第二預設閾值,則令所述第一預設閾值減少一個固定值,并重新對該短句進行分句處理,直至得到的每個短句的所述字符總數不大于所述第二預設閾值。
通過S204和S205對每個相鄰的分詞進行處理后,可得到第一次分句處理的結果,此時得到輸入文本被分割后的多個短句。以任一短句為識別對象,識別該短句中包含有多少個字符,即字符總數。若該短句的字符總數大于第二預設閾值,則表示該短句的長度過長,還能夠繼續分割為長度更短的短句,因此,令第一預設閾值減少一個預設的固定值,使得靜音時長的時長判斷標準能夠被縮短,并再次對字符總數超過第二預設閾值的該短句執行分句處理,以該短句中的相鄰分詞為第一分詞以及第二分詞,重新執行S204至S206。
當得到的短句的字符總數小于或等于第二預設閾值時,則該短句無須重復進行分句處理,直接作為輸入文本中的一個短句輸出。
本發明實施例利用語音信號中的靜音幀來對輸入文本進行分句處理,并在得到的任一短句的字符總數不滿足預設條件之下,多次重復執行分句,保證了最后輸出的每個短句,其對應的語音幀序列在虛擬人臉動畫中播放時,能夠具備真實場景中的語言韻律感,因此能夠提高虛擬人臉動畫的真實性。
在S103中,對于每個所述短句,生成虛擬人臉動畫中的一個頭部擺動動作。
實際環境中,當人在說話時,頭部會隨著說話的內容而擺動,例如頭部轉動動作或點頭動作,并且,通常頭部上下擺動的幅度較大。頭部擺動動作的產生時刻與短句之間的韻律感有著極大的關聯。為了較準確地模擬頭部擺動動作的發生時機,在本實施例中,在每一個短句對應的語音幀序列在虛擬人臉動畫中播放時,生成對應的一個頭部擺動動作。
以一個短句對應的語音幀序列的長度作為頭部擺動的周期,即在該語音幀序列播放期間內,剛好完成一個頭部擺動動作。對于點頭這個動作,頭部分別抬到的最低點位置和最高點位置為點頭動作的第一極值點位置和第二極值點位置。為了確定頭部在哪個時刻到達這兩個極值點位置,在一個頭部點頭動作對應的短句中,獲取該短句中具有強調性質的副詞的位置,如“很”、“非常”,或者,獲取該短句中出現的首個音節,則該副詞或者該音節對應的語音幀序列的播放時刻則為頭部抬至第一極值點位置的時刻;獲取該短句中出現的最后一個音節或者包含下降音的音節,則該最后一個音節或者包含下降音的音節對應的語音幀序列的播放時刻則為頭部抬至第二極值點位置的時刻。
在本實施例中,極值點位置的具體高低基于對真實數據的統計分析獲得。另外,除了生成韻律節奏的頭部擺動動作外,還可以加入隨機產生的眼部活動動作等。這些隨機動作的生成頻率以及幅度,依然基于對真實數據的統計分析而獲得。
在S104中,將每個所述短句映射成至少一個唇形。
本實施例以短句中類型有限的音素作為唇形的判斷依據。對于每個短句中的音素,唇形對應的音素并非為單個音素,而是音素的組合。通過采用多個音素對應同一個唇形(多對一)或者多個音素對應多個唇形(多對多)的方式,映射成虛擬人臉動畫中的一個或者多個唇形。
作為本發明的一個實施例,圖3示出了本發明實施例提供的虛擬人臉動畫的生成方法S104的具體實現流程,詳述如下:
在S301中,獲取所述語音信號中的每個音素以及每個所述音素的聲強。
通過Stanford NLP、Boson NLP、LTP、Hanlp等預設算法,調用相應的庫程序接口,從而實現為輸入文本中的每個短句標注漢語拼音。例如,對于短句“我/熱愛/這個/職業/”,則拼音標注結果為“我wo3熱re4愛ai4這zhe4個ge5職zhi2業ye4”。根據該拼音標注結果,可以從每個拼音中提取出各個音素。比如,從“wo”中提取出的兩個音素為“w”和“o”。
通過分析語音信號中音素幀的強度,可以逐一確定出語音信號中每個音素的聲強。例如,若音素“w”對應的音素幀為A、B、C,則A、B、C三個音素幀的平均聲強可作為音素“w”的聲強。
在S302中,在多個所述音素中,以相鄰的至少兩個音素為一個音素組合,判斷所述音素組合是否滿足協同發音條件。
協同發音是指在發音時,若聲道中兩個不同的部位形成阻礙,則這兩個阻礙可能是完全阻塞,也可能是其中一個部位的阻塞程度較輕。產生協同發音現象時,將所有可能遇到的音素組合存儲于系統中。
以相鄰的兩個、三個、或N個音素為一個音素組合,判斷該音素組合是否滿足協同發音條件,即,判斷該音素組合是否與預存儲于系統中的任一音素組合相同。
在S303中,若所述單位滿足協同發音條件,則將相鄰的所述至少兩個音素映射成一個唇形。
若待判斷的音素組合與預存儲于系統中的任一音素組合相同,或者,根據滿足協同發音的所有音素組合,訓練出唇形識別模型。則當不同的音素組合輸入唇形識別模型時,能夠自動判斷該音素組合是否滿足協同發音條件,并將構成該音素組合的各個音素自動映射輸出為一個唇形。
在音素組合對應的語音幀序列中,以處于飽滿時刻的語音幀為關鍵幀,并通過音素與唇形的對應關系,可以確定關鍵幀所對應的唇形。對于非關鍵幀,需要通過相鄰關鍵幀唇形插值的方法來確定其對應的唇形。唇形插值算法例如可以是數學插值方法(如多項式插值算法),或使用Cohen-Massaro模型的算法等。
在S304中,將相鄰的所述至少兩個音素的所述聲強映射成所述唇形對應的唇部運動幅度。
通過S301獲得音素組合中每個音素的聲強平均值,每個唇形產生時將會對應一個唇部開口或閉合的運動動作,則該運動動作的幅度大小與該聲強平均值大小成正比。
在S105中,將每個所述短句對應的所述頭部擺動動作與所述唇形融合,以生成每個所述短句對應的虛擬人臉動畫。
使用不同的骨架設定算法在視頻畫面中生成唇部與頭部后,在每個頭部擺動動作的擺動周期內,依次播放該頭部擺動動作對應的短句所映射出的一個或多個唇形。從而得到了一個頭部加唇部同時運動的虛擬人臉動畫的顯示效果。
本發明實施例基于文本與語音結合的方式來生成虛擬人臉動畫,根據輸入文本中的每個短句,生成頭部擺動動作以及唇形,為用戶提供了更接近現實的視覺感官效果,避免了最后得到的虛擬人臉動畫僅包含唇形信息,提高了虛擬人臉動畫的真實性。此外,本發明實施例提供的虛擬人臉動畫的生成方法無需依賴昂貴、復雜的設備來實現,從而降低了成本,擴大了虛擬人臉動畫的應用范圍,促進了人工智能技術的發展。
作為本發明的另一個實施例,如圖4所示,在S202之前,在S201之后,所述方法還包括:
在S401中,獲取每個所述語音幀中各音素的出現概率。
其中,如圖5所示,S401具體如下:
在S501中,獲取包含多條合成語音的語料庫。
在S502中,基于所述語料庫中的多條所述合成語音,構建并訓練語音識別模型。
在S503中,將每個所述語音幀輸入所述語音識別模型,以輸出每個所述語音幀中各音素的出現概率。
在本實施例中,利用語音合成算法,預先創建一個包含大量合成語音的語料庫,并將該語料庫結合開源的語音識別訓練平臺(如KAIDI),來訓練一個基于語音識別模型的語音識別法,然后再將這個語音識別模型提取出來,用于獲取每個所述語音幀中各音素的出現概率。
將語音幀輸入預先獲得的語音識別模型后,可計算出每個語音幀中所包含的每個音素的概率,即各音素在該語音幀中的出現概率。
如圖6所示,各個語音幀經過語音識別模型處理后,呈現出每個語音幀中包含的不同音素。在圖5中,語音幀中的數字1、2、3、4、5、6代表不同的音素,每種音素具有一個概率值,代表著語音幀中該音素的出現概率。例如,數字4代表音素“w”,數字“2”代表音素“o”,數字“6”代表靜音“sil”。經過語音識別模型的判斷處理,語音幀1中包含音素“w”的概率是0.8,語音幀2中包含音素“w”的概率是0.9,語音幀4中包含音素“o”的概率是0.8,語音幀8中包含靜音“sil”的概率是0.7。
在S402中,獲取所述語音信號對應的音素序列,所述音素序列包含按先后順序依次排列的多個音素。
由于語音信號是由輸入文本轉換而來的,因此,語音信號所對應的音素序列可根據輸入文本中的拼音標注而獲得。拼音標注的過程與上述實施例中S301的具體實施過程相同,得到拼音標注結果后,除了漢字符與數字外,將標注的拼音全部提取出來,依次形成一個語音信號對應的音素序列。
例如,拼音標注結果為“我wo3熱re4愛ai4這zhe4個ge5職zhi2業ye4”,則音素序列為“w-o-r-e-a-i-zh-e-g-e-zh-i-y-e”。每個音素在音素序列中的排列順序與其在輸入文本對應的拼音標注中出現的先后次序相同。例如,上述音素序列中,“w”會排在在“o”之后。
在S403中,根據所述音素序列中各個音素的排列順序以及所述語音幀中各音素的出現概率,在所述多個語音幀中確定所述靜音幀以及確定所述音素序列中各音素分別對應的音素幀。
在本實施例中,每一個語音幀僅為一個音素幀或者為一個靜音幀,每個音素幀在實際中僅與一個音素對應。根據S402中給定的音素序列,對每個語音幀與音素序列中每個音素的對應關系進行判定。
仍以圖6為例,若給定的音素序列為“w-o-…”,由于最先出現的語音幀1、2、3中,音素“w”的出現概率相對較大,且音素序列中最先出現的音素為“w”,因此,語音幀1、2、3均對應音素“w”。在音素序列中,音素“w”之后應當是音素“o”,而語音幀4、5、6、7中音素“o”的出現概率也相對較大,因此確定語音幀4、5、6、7均對應音素“o”,第8幀為靜音幀,等等。
若音素序列中“o”后面的音素為“i”,而“o”所對應的音素幀之后的一個語音幀為A,且A中“u”與“i”的出現概率均為“0.5”,則根據音素序列中“o”后面不可能出現“u”,因此,語音幀A也應當確定為與音素“i”對應的音素幀。
確定音素對應的多個音素幀后,依照音素幀的出現順序,能夠確定每個音素在虛擬人臉動畫中發音的起始時刻與結束時刻。由于音素在其對應的不同語音幀中的出現概率不同,因此,能夠以其出現概率最大的一個語音幀所出現的時刻作為該音素在虛擬人臉動畫中發音的飽滿時刻,或者,以起始時刻與結束時間的中點時刻作為該音素在虛擬人臉動畫中發音的飽滿時刻。
對于判定為靜音幀的語音幀,能夠確定其在虛擬人臉動畫中播放的具體起始位置與結束位置,以及每個靜音幀的長度。并可根據連續靜音幀的長度,獲得靜音時長。
本發明實施例中,基于合成語音來獲得語音識別模型,在訓練前無需人工對各個語料進行標注,自動化程度高。根據語音識別模型來獲取語音幀中各音素的出現概率,并由此得到每個音素對應的語音幀及在虛擬人臉動畫中的發音時間點,從而實現了音素與語音幀的強制對齊,因音素能夠映射唇形,因而唇形與語音的同步效果得到了顯著提升,提高了虛擬人臉動畫的真實性。
作為本發明的又一實施例,如圖7所示,上述虛擬人臉動畫的生成方法還包括:
在S701中,通過情感分析算法對所述輸入文本進行處理,以得到所述輸入文本的情感類型。
最常用的7種情感類別,分別為:中性、高興、悲傷、驚訝、恐懼、氣憤、惡心。輸入文本的不同分詞可表達不同的情感類別,因此,輸入文本相應地可映射為其中的若干種情感類型,在虛擬人臉動畫的不同發音時刻僅對應一種情感類型。
對多個訓練文本中具有情感傾向性質的詞語(如“傷心”、“討厭”等)、標點符號(如驚嘆號)、包含強烈情感的副詞(如“非常”)進行收集與統計,根據統計結果來訓練一個情感分類器。然后利用該情感分類器來對輸入文本進行情感分析處理,從而輸出其對應的情感類型。其中,情感分類器例如可以是簡單的支持向量機(Support Vector Machine,SVM)模型,或者是基于深度學習的情感分析模型,如Bidirectional-LSTM模型等。
在S702中,獲取所述情感類型對應的骨架系數,所述骨架系數表示虛擬人臉動畫中預存儲的一種表情姿態。
對于上述七種情感類型(中性、高興、悲傷、驚訝、恐懼、氣憤、惡心),可以預先通過手工的方式對虛擬人臉動畫中的骨架進行操控,以模擬出七種人臉表情。每種表情產生后,將會生產七組不同的骨架系數,并預存儲在系統中。在得到輸入文本對應的一個或多個情感類型后,可以直接將上述一個或多個情感類別映射到與其一一對應的預存儲的骨架系數中。
在S703中,根據所述骨架系數為所述虛擬人臉動畫渲染人臉表情。
得到骨架系數后,可使用不同的骨架設定算法生成人臉表情。其中,骨架設定算法為計算機圖形對象中預設的一副骨架,通過操控這幅骨架可以實現對該對象的姿態驅動,生成一系列的圖像動作。例如,skeleton、blend shapes的線性組合或者skeleton和肌肉生成算法結合的骨架設定算法等。利用上述骨架設定算法生成虛擬人臉的皮膚,在生成后的虛擬人臉皮膚上,在對應的各個時刻點,獲取此時的骨架系數,并驅動虛擬人臉生成表達此刻情感類型的一種人臉表情。
特別地,人臉表情與唇部運動的融合方法取決于兩者間的骨架設定算法。如果人臉表情與唇部運動使用相同的骨架設定方法,則將兩者對應的骨架系數進行融合;如果人臉表情與唇部運動使用相同不同的骨架設定方法,則先生成僅包含人臉表情的三維虛擬人臉模型以及僅包含唇部運動的三維虛擬人臉模型,然后再將兩個模型融合至一起。融合的方法例如可以是,直接對兩個三維虛擬人臉模型中每個點的三維空間位置值取平均。人臉表情與唇部運動融合后,再與頭部運動直接進行融合。
本發明實施例根據輸入文本來驅動一幅虛擬人臉動畫,且該虛擬人臉動畫能夠發聲、包含頭部運動、人臉表情以及與語音同步的唇部運動,難以受到噪聲的干擾,準確度高,因此,提高了虛擬人臉動畫的真實程度。
應理解,在本發明實施例中,上述各過程的序號的大小并不意味著執行順序的先后,各過程的執行順序應以其功能和內在邏輯確定,而不應對本發明實施例的實施過程構成任何限定。
對應于本發明實施例所提供的虛擬人臉動畫的生成方法,圖8示出了本發明實施例提供的虛擬人臉動畫的生成裝置的結構框圖。為了便于說明,僅示出了與本實施例相關的部分。
參照圖8,該裝置包括:
第一獲取單元81,用于將輸入文本轉化為語音信號。
分句單元82,用于根據所述語音信號中靜音幀的出現位置,對所述輸入文本進行分句處理,得到多個短句。
生成單元83,用于對于每個所述短句,生成虛擬人臉動畫中的一個頭部擺動動作。
映射單元84,用于將每個所述短句映射成至少一個唇形。
融合單元85,用于將每個所述短句對應的所述頭部擺動動作與所述唇形融合,以生成每個所述短句對應的虛擬人臉動畫。
可選地,所述分句單元82包括:
分幀子單元,用于將所述語音信號分解成多個語音幀,所述多個語音幀包括所述靜音幀以及音素幀。
第一獲取子單元,用于對所述輸入文本進行分詞處理,并獲取每個分詞對應的多個所述音素幀。
第二獲取子單元,用于若相鄰的兩個分詞分別對應的多個所述音素幀之間存在一個或多個靜音幀,則獲取所述一個或多個靜音幀的總時長。
劃分子單元,用于當所述總時長大于第一預設閾值時,將相鄰的兩個分詞分別劃分至相鄰的兩個短句中。
分句子單元,用于若劃分得到的任意一個所述短句的字符總數大于第二預設閾值,則令所述第一預設閾值減少一個固定值,并重新對該短句進行分句處理,直至得到的每個短句的所述字符總數不大于所述第二預設閾值。
可選地,所述裝置還包括:
第二獲取單元,用于獲取每個所述語音幀中各音素的出現概率。
第三獲取單元,用于獲取所述語音信號對應的音素序列,所述音素序列包含按先后順序依次排列的多個音素。
確定單元,用于根據所述音素序列中各個音素的排列順序以及所述語音幀中各音素的出現概率,在所述多個語音幀中確定所述靜音幀以及確定所述音素序列中各音素分別對應的音素幀。
可選地,所述第二獲取單元包括:
第三獲取子單元,用于獲取包含多條合成語音的語料庫。
訓練子單元,用于基于所述語料庫中的多條所述合成語音,構建并訓練語音識別模型。
輸出子單元,用于將每個所述語音幀輸入所述語音識別模型,以輸出每個所述語音幀中各音素的出現概率。
可選地,所述裝置還包括:
情感分析單元,用于通過情感分析算法對所述輸入文本進行處理,以得到所述輸入文本的情感類型。
第四獲取單元,用于獲取所述情感類型對應的骨架系數,所述骨架系數表示虛擬人臉動畫中預存儲的一種表情姿態。
渲染單元,用于根據所述骨架系數為所述虛擬人臉動畫渲染人臉表情。
本領域普通技術人員可以意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬件、或者計算機軟件和電子硬件的結合來實現。這些功能究竟以硬件還是軟件方式來執行,取決于技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的范圍。
所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的系統、裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
在本申請所提供的幾個實施例中,應該理解到,所揭露的系統、裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。
所述功能如果以軟件功能單元的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光盤等各種可以存儲程序代碼的介質。
以上所述,僅為本發明的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉本技術領域的技術人員在本發明揭露的技術范圍內,可輕易想到變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應所述以權利要求的保護范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!