布渣葉黃烷酮?2?羥基化酶及其編碼基因與應用的制作方法
本發明屬于基因工程技術領域。更具體地,涉及一種布渣葉黃烷酮-2-羥基化酶及其編碼基因與應用。
背景技術:
植物類黃酮是一類廣泛存在的小分子化合物,在植物體內大多以糖苷形式存在,其O-苷不勝枚舉,而C-苷歷歷可數。黃酮C-苷的糖配基大多直接連接在其A環的C-6/C-8位,因母核各異,其種類也不盡相同。長期以來,植物類黃酮以其廣泛的生理活性和良好的藥食兩用價值使得其應用研究如火如荼,其中大量的工作主要集中了各種黃酮類成份的分離純化、結構鑒定、活性評價及產品開發上。但相關的基礎研究,比如植物類黃酮次生代謝調控的研究,尤其是黃酮C-苷的次生代謝調控研究,相關的研究報道屈指可數。
近年來,隨著研究的不斷深入,黃酮 C-苷及其生物活性引起了越來越多的關注。從文獻報道可知,其苷元以芹菜素或木犀草素較為常見,其糖配基以葡萄糖、鼠李糖、木糖或阿拉伯糖等居多,如牡荊苷、異牡荊苷、維采寧-2、夏佛塔苷、異夏佛塔苷等。研究發現,黃酮碳苷通常具有較好的抗炎、抗氧化、抗腫瘤、降血糖、降血壓、護肝等活性。
黃酮C-苷化學性質較O-苷穩定,其化學合成難度也較大。迄今,獲取黃酮C-苷的主要途徑仍然是從植物原料中提取分離。隨著現代生物技術的發展,植物次生代謝逐漸成為研究熱點之一。而今,通過調控相應的生物合成關鍵酶基因的表達,以提高特定代謝產物的累積,在植物基因工程上的應用已越來越成熟,如青蒿素,人參皂苷等。在前期研究中發現,廣東涼茶植物布渣葉中黃酮C-苷含量較高,組份較多,且大多數都是芹黃素-C-苷(Apigenin C-glycosides, ACGs)。因此,探索布渣葉ACGs生物合成相關酶的研究具有重要的意義。
技術實現要素:
本發明要解決的技術問題是克服現有布渣葉ACGs生物合成相關酶及其基因的研究不足,提供一種與其ACGs生物合成相關的關鍵酶基因,并進行了原核表達和功能驗證,為進一步研究布渣葉ACG生源途徑奠定了基礎。
本發明的目的是提供一種布渣葉黃烷酮-2-羥基化酶MpF2H及其編碼基因。
本發明另一目的是提供所述布渣葉黃烷酮-2-羥基化酶及其編碼基因的應用。
本發明再一目的是提供所述布渣葉黃烷酮-2-羥基化酶的制備方法。
本發明上述目的通過以下技術方案實現:
一種編碼布渣葉黃烷酮-2-羥基化酶的DNA分子(即布渣葉黃烷酮-2-羥基化酶編碼基因MpF2H),其核苷酸序列如SEQ ID NO.1或SEQ ID NO.2所示(SEQ ID NO.1為DNA全長序列,SEQ ID NO.2為cDNA序列,即開放閱讀框)。
一種在嚴格條件下能夠與SEQ ID NO.1或SEQ ID NO.2所示序列雜交且編碼具有相同功能蛋白質的DNA分子,也應在本發明的保護范圍之內。
優選地,上述嚴格條件可為:在6×SSC、0.5% SDS的溶液中,在65℃下雜交,然后用2×SSC、0.1% SDS,以及1×SSC、0.1% SDS各洗膜一次。
一種與SEQ ID NO.1或SEQ ID NO.2所示序列至少具有80%、至少具有85%、至少具有90%、至少具有95%、至少具有96%、至少具有97%、至少具有98%或至少具有99%同源性且編碼具有相同功能蛋白質的DNA分子,也應在本發明的保護范圍之內。
一種布渣葉黃烷酮-2-羥基化酶,其氨基酸序列如SEQ ID NO.3所示。
一種將SEQ ID NO.3所示氨基酸序列經過一個或幾個氨基酸殘基的取代和/或缺失和/或添加所得具有相同功能的蛋白質,也應在本發明的保護范圍之內。
本發明在前期研究發現布渣葉中黃酮C-苷含量較高的基礎上,同時,綜合布渣葉的轉錄組和代謝組數據,經差異基因表達和趨勢分析,篩選發現了與其ACGs生物合成相關的關鍵酶基因 F2H(Flavanone 2-hydroxylase,MpF2H),并首次從布渣葉中克隆了 MpF2H基因cDNA 序列,并進行了原核表達和功能驗證,為牡荊苷、異牡荊苷和維采寧-2等黃酮碳苷類成分的制備提供了一種新的途徑。
另外,一種含有上述DNA分子的重組載體、表達盒、轉基因細胞系或重組菌,也應在本發明的保護范圍之內。
優選地,所述重組載體為將SEQ ID NO.1或SEQ ID NO.2所示序列插入pET30a(+)載體的Bam HI和 Hind III酶切位點間得到的載體,命名為pET30- MpF2H。
一種擴增上述DNA分子全長或其任意片段的引物對,也應在本發明的保護范圍之內。
優選地,一種擴增SEQ ID NO.1或SEQ ID NO.2所示序列的引物對,其正反向引物序列分別如SEQ ID NO.4和SEQ ID NO.5所示。
另外,上述布渣葉黃烷酮-2-羥基化酶在作為或制備黃烷酮-2-羥基化酶制劑方面的應用,所述布渣葉黃烷酮-2-羥基化酶、上述DNA分子或上述重組載體、表達盒、轉基因細胞系或重組菌在催化柚皮素生成2-羥基柚皮素方面的應用,以及上述DNA分子在制備布渣葉黃烷酮-2-羥基化酶中的應用,也都應在本發明的保護范圍之內。
具體地,可以通過含有所述DNA分子的重組載體、表達盒、轉基因細胞系或重組菌制備布渣葉黃烷酮-2-羥基化酶。
一種制備布渣葉黃烷酮-2-羥基化酶的方法,包括如下步驟:培養含有布渣葉黃烷酮-2-羥基化酶基因MpF2H的重組菌,收集培養物,得到布渣葉黃烷酮-2-羥基化酶。
更具體地,所述制備布渣葉黃烷酮-2-羥基化酶的方法,包括如下步驟:
S1.構建重組載體
將布渣葉黃烷酮-2-羥基化酶編碼基因MpF2H的序列插入至pET30a(+)質粒的Bam HI和 Hind III酶切位點之間,得到重組載體pET30a-MpF2H;
S2. MpF2H蛋白的表達
將重組載體pET30a-MpF2H導入感受態細胞,得到重組菌;在重組菌的培養體系中加入異丙基硫代-β-D-半乳糖苷(IPTG),振蕩誘導培養;
S3. MpF2H蛋白的純化
S31.步驟S2所述振蕩誘導培養6~8小時后收集培養物,離心收集菌體沉淀,加入Tris–HCl,超聲破碎;
S32.步驟S31破碎后的產物離心,取上清液,即為MpF2H蛋白粗提取物,經過純化得到MpF2H蛋白。
其中,優選地,步驟S1的具體方法為:
以布渣葉葉片cDNA為模板,利用正向引物MpF2H-F(序列如SEQ ID NO.4所示)和反向引物MpF2H-R(序列如SEQ ID NO.5所示)進行PCR擴增基因MpF2H片段,再用限制性內切酶 Bam HI 和 Hind III 對PCR擴增產物和pET-30a (+)質粒進行雙酶切,經過連接酶連接(T4 DNA 連接酶 18℃連接過夜)后得到重組質粒pET30a-MpF2H。
其中,優選地,所述PCR擴增的反應體系為:cDNA 模板 1μL,MpF2H-F 1μL,MpF2H-R 1μL,10×ExTaq buffer 5μL,2.5mmol/L dNTP 4μL,ExTaq 酶 0.25μL,加水至50μL。
優選地,所述PCR擴增的反應程序為(降落PCR):95℃預變性 5 min,循環內98℃ 10s變性,從65℃每個循環降1℃退火,72℃延伸2min,10個循環;在55℃退火,進行20個循環;PCR反應循環后72℃延伸7 min,然后4℃保存。
另外,優選地,步驟S2所述感受態細胞為E.coli trans1 T1感受態細胞,得到重組菌E.coli trans1 T1-pET30a-MpF2H。
優選地,步驟S2中培養重組菌所用培養基為含50~100μg/ml(更優選為50μg/ml)卡拉霉素的LB培養基。
優選地,步驟S2中異丙基硫代-β-D-半乳糖苷(IPTG)的終濃度為0.5μM。
優選地,步驟S2中,重組菌的培養過程為:先37℃振蕩培養至OD600=0.6~0.8后,加入IPTG,28℃振蕩誘導培養。
更優選地,步驟S2中,重組菌的培養過程為:將重組菌接種于含50μg/ml卡拉霉素的LB培養基中,37℃振蕩培養過夜,以1:100比例接種于新鮮的含抗生素卡拉霉素的培養基中,37℃振蕩培養2~3h,待OD600=0.6~0.8 后,加入異丙基硫代-β-D-半乳糖苷(IPTG,終濃度為0.5μM),在28℃振蕩誘導培養。
優選地,步驟S31所述離心的條件為12000r/min,4℃,離心1min。
優選地,步驟S31所述菌體沉淀還需重懸于PBS(pH 7.5)緩沖液中洗滌2次后,再加入Tris–HCl。步驟S31所述Tris–HCl的濃度為0.1mM,pH7.5。
優選地,步驟S31所述超聲破碎的條件為:置于碎冰上超聲破碎,20KHz、120W,開2秒、停10秒,循環10次。
優選地,步驟S32所述離心的條件為12000r/min,4℃,離心30min。
優選地,步驟S32所述純化利用His-Bind蛋白純化回收試劑盒進行。
本發明具有以下有益效果:
本發明首次從布渣葉中克隆得到布渣葉黃烷酮-2-羥基化酶 (MpF2H)基因,體外實驗表明,MpF2H具有催化柚皮素生成2-羥基柚皮素的活性,是一種黃烷酮-2-羥基化酶,為進一步研究布渣葉ACGs生源途徑奠定了基礎;研究結果對其次生代謝調控及種質創新研究也將具有非常重要科學意義與應用價值。
利用本發明,可以以MpF2H基因為基礎,通過基因工程技術來提高布渣葉等植物中牡荊苷、異牡荊苷和維采寧-2等黃酮碳苷類成分的含量,或通過生物合成技術制備牡荊苷、異牡荊苷和維采寧-2等黃酮碳苷類成分,為該類黃酮碳苷類成分的制備合成提供了一種新的途徑。
附圖說明
圖1為重組表達載體pET30a-MpF2H的圖譜。
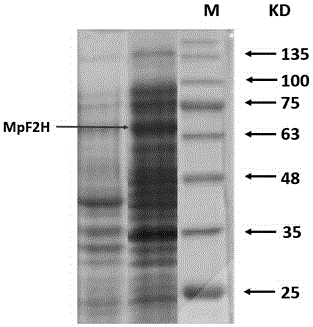
圖2為MpF2H蛋白質的SDS-聚丙烯酰胺凝膠電泳結果。
具體實施方式
以下結合說明書附圖和具體實施例來進一步說明本發明,但實施例并不對本發明做任何形式的限定。除非特別說明,本發明采用的試劑、方法和設備為本技術領域常規試劑、方法和設備。
除非特別說明,本發明所用試劑和材料均為市購。
以下實施例所用試劑盒材料來源:
同源重組克隆試劑盒( pEASY-Uni Seamless Cloning andAssembly Kit)、蛋白Marker、大腸桿菌感受態Trans1-T1、pET30a(+)載體以及DNA凝膠回收試劑盒購自北京全式金生物技術有限公司;RNA反轉錄試劑盒、BamH I限制性內切酶購自寶生物(大連)工程有限公司(TaKaRa)公司。引物合成和測序由廣州生工有限公司完成。柚皮素和2-羥基柚皮素購自Chemface(武漢天植生物技術有限公司)。
實施例1 布渣葉黃烷酮-2-羥基化酶基因MpF2H的克隆
1、利用植物總 RNA 提取試劑盒提取布渣葉葉片的總 RNA,反轉錄得到cDNA為模板,用正向引物MpF2H-F(序列如SEQ ID NO.4所示)和反向引物MpF2H-R(序列如SEQ ID NO.5所示)進行PCR擴增。
正向引物:MpF2H-F(序列如SEQ ID NO.4所示)
5’-CGGGATCCATGATGCCCATGATACTTGAAT-3’;
反向引物:MpF2H-R(序列如SEQ ID NO.5所示)
5’-CCCAAGCTTTTAGGTTGCAAAGAGAGTGGGA3’。
其中,所述PCR擴增的反應體系為 :
cDNA 模板 1μL,MpF2H-F 1μL,MpF2H-R 1μL,10×ExTaq buffer 5μL,2.5mmol/L dNTP 4μL,ExTaq 酶 0.25 μL,加水至 50μL。
所述的PCR反應條件為(降落PCR):95℃預變性 5 min,循環內98℃ 10s變性,從65℃每個循環降1℃退火,72℃延伸2min,10個循環;在55℃退火,進行20個循環;PCR反應循環后72℃延伸7 min,然后4℃保存。
2、PCR 產物用1%瓊脂糖凝膠電泳檢測分析,用 PCR 產物純化試劑盒純化。用限制性內切酶 Bam HI 和 Hind III 對PCR純化產物和pET-30a (+)質粒進行雙酶切,T4 DNA 連接酶16℃連接過夜后轉化大腸桿菌 Trans1-T1感受態細胞,在卡拉抗性平板上進行篩選,經菌液 PCR 和電泳檢測后,挑選陽性克隆測序。
3、經過測序分析,得到布渣葉黃烷酮-2-羥基化酶基因MpF2H的序列,如SEQ ID NO.1所示(1826bp),其開放閱讀框如SEQ ID NO.2所示(1557bp),編碼的蛋白命名為布渣葉黃烷酮-2-羥基化酶MpF2H,該蛋白的氨基酸序列如SEQ ID NO.3所示(518aa)。
實施例2 布渣葉黃烷酮-2-羥基化酶MpF2H的表達和純化
1、重組載體的構建
提取布渣葉葉片總RNA,反轉錄得到cDNA為模板,用用正向引物MpF2H-F(序列如SEQ ID NO.4所示)和反向引物MpF2H-R(序列如SEQ ID NO.5所示)進行PCR擴增。
PCR反應體系為:cDNA 模板 1μL,MpF2H-F 1μL,MpF2H-R 1μL,10×ExTaq buffer 5μL,2.5mmol/L dNTP 4μL,ExTaq 酶 - 0.5μL,加水至50μL。
反應條件為(降落PCR):95℃預變性 5 min,循環內98℃ 10s變性,從65℃每個循環降1℃退火,72℃延伸2min,10個循環;在55℃退火,進行20個循環;PCR反應循環后72℃延伸7 min,然后4℃保存。
PCR產物用純化試劑盒純化。用限制性內切酶 Bam HI 和 Hind III 對PCR純化產物和pET-30a (+)質粒進行雙酶切,T4 DNA 連接酶 18℃連接過夜后得到重組質粒,該重組載體為將MpF2H基因序列插入pET30a(+)質粒的Bam HI和 Hind III酶切位點間得到的載體,命名為pET30a-MpF2H(如圖1所示)。
2、MpF2H蛋白的表達
(1)將目標質粒pET30a-MpF2H導入E.coli trans1 T1感受態細胞,得到重組菌E.colitrans1 T1-pET30a-MpF2H。
將空載體pET30a導入E.coli trans1 T1感受態細胞,得到對照菌E.coli trans1 T1-pET30a。
(2)將重組菌E.coli trans1 T1-pET30a-MpF2H接種于含50μg/ml卡拉霉素的LB培養基中,37℃振蕩培養過夜,以1:100比例接種于新鮮的含抗生素卡拉霉素的培養基中,37℃振蕩培養2~3h,待OD600=0.6~0.8 后,取1ml菌液作為誘導前對照,然后加入異丙基硫代-β-D-半乳糖苷(IPTG,終濃度為0 .5μM ),在28℃振蕩誘導培養。以E.coli trans1 T1-pET30a為陰性對照。
(3)誘導培養6~8小時后,收集培養物,置于碎冰上超聲破碎,20KHz,120W,開2秒,停10秒,循環10次,離心收集上清液。將上清液進行SDS-聚丙烯酰胺凝膠電泳,結果如圖2所示,泳道M為Protein Marker(17-180kDa),可以看出,在分子量約為70 kD處,出現一條明顯的特異蛋白質表達條帶,與理論值一致,表明表達得到蛋白MpF2H(如圖2所示)。
3、MpF2H蛋白純化
(1)將重組菌E.coli trans1 T1-pET30a-MpF2H接種于含50μg/ml卡拉霉素的LB培養基中,37℃振蕩培養過夜,以1:100比例接種于新鮮的含抗生素卡拉霉素的培養基中,37℃振蕩培養2~3h,待OD600=0.6~0.8 后,加入異丙基硫代-β-D-半乳糖苷(IPTG,終濃度為0 .5μM ),在28℃振蕩誘導培養,6~8小時后收集培養物,12000r/min,4℃,離心1min,收集菌體沉淀,重懸于PBS(pH 7.5)緩沖液中,洗滌2次,再加入0.1mM Tris–HCl(pH 7.5),置于碎冰上超聲破碎,20KHz,120W,開2秒,停10秒,循環10次,12000r/min,4℃,離心30min,吸取上清液作為MpF2H蛋白粗提取物,置冰上備用。
(2)按照His-Bind蛋白純化回收試劑盒說明書對上述粗提物進行純化,得到MpF2H蛋白。
實施例3 布渣葉黃烷酮-2-羥基化酶MpF2H及其基因的功能研究
1、按照實施例2的方法將布渣葉黃烷酮-2-羥基化酶基因MpF2H表達出布渣葉黃烷酮-2-羥基化酶MpF2H,對其功能進行研究。
MpF2H蛋白功能驗證:
以柚皮素為反應底物進行體外酶功能驗證。在200μL反應體系中包括:0.1 M甘氨酸(KOH, pH 7.9),0.1 mM柚皮素,0.5 mM還原性的谷胱甘肽,1 mM NADPH,50μg MpF2H蛋白純化產物。混勻,水浴30℃,孵育6~12h,加入400μL冰冷的甲醇終止反應,12000rpm離心10min,取上清,過0.22μm濾膜,進行LC-ESI-QTOF-MS分析。以柚皮素和2-羥基柚皮素對照品(購自Chemface)為對照,根據精確分子量、MS/MS碎片質荷比和色譜保留時間等進行目標產物鑒定。
UPLC-ESI-QTOF-MS分析條件如下:
液相條件:流動相為0.1%甲酸-乙腈(A),0.1%甲酸-水(B),流速0.2 mL/min,梯度洗脫程序為0min 7%B,3min 18%B,3.5min 7%B,5.5min 7%B;
質譜條件:離子源:ESI+,電離模式:正離子模式;離子源溫度:150℃;脫溶劑溫度450℃;毛細管電壓:2500V脫溶劑氣流速900L/hr,錐孔氣流速50L/hr,裂解能20-30eV;高分辨質譜分析參數值如下表1所示。
表1高分辨質譜分析值
結果發現,柚皮素和2-羥基柚皮素標準品保留時間分別為4.24min 和3.52min,上述MpF2H酶促反應體系在4.24min檢出2-羥基柚皮素相應特征峰,而對照反應體系沒有檢測到相應的特征峰。
對MpF2H酶促反應體系的特征峰進行質譜碎片分析,相應的分子離子精確分子量(m/z)和碎片離子精確分子量(m/z)為與標準品MS和MS/MS一致;至此可以確定酶促反應后確有2-羥基柚皮素生成。
結果表明,盡管相應的誘導表達條件、蛋白的分離純化條件以及酶促反應體系可以進一步優化,但MpF2H融合蛋白確實具有催化柚皮素合成2-羥基柚皮素的活性,說明該基因為黃烷酮-2-羥基化酶編碼基因。因此,可以以MpF2H基因為基礎,通過基因工程技術來提高布渣葉等植物中牡荊苷、異牡荊苷和維采寧-2等黃酮碳苷類成分的含量,或通過生物合成技術制備牡荊苷、異牡荊苷和維采寧-2等黃酮碳苷類成分。
SEQUENCE LISTING
<110> 廣東藥科大學
<120> 布渣葉黃烷酮-2-羥基化酶及其編碼基因與應用
<130>
<160> 5
<170> PatentIn version 3.3
<210> 1
<211> 1826
<212> DNA
<213> 布渣葉黃烷酮-2-羥基化酶基因MpF2H的DNA全長序列
<400> 1
ttccctctag aataattttg tttaacttta agaaggagat atacatatgc accatcatca 60
tcatcattct tctggtctgg tgccacgcgg ttctggtatg aaagaaaccg ctgctgctaa 120
attcgaacgc cagcacatgg acagcccaga tctgggtacc gacgacgacg acaaggccat 180
ggctgatatc ggatccatga tgcccatgat acttgaattc ctatcatatc tagctccctt 240
agttgtttca tttcttctcg ttaagagaat actcatctct accaacaagc aaggtcctaa 300
tgccaagcag cttcttcccc caggcccaat cgccttaccg atcattggcc acctccatct 360
cctgggcccc ttccttcatc aaaccttccg caagctctcc tcgcgctacg gtcccttaat 420
gtatcttcgt cttggctctg ttggctgcgt ggtggcttcc aatccagagt ttgccaaaga 480
gcttctcaaa acttacgagc tcgccttcgc tgcccgcatg cacaccgctg ccatcaccca 540
cctgacctac aactcgtcct ttgccttcgc accgtacgga acgtactgga aattcatcag 600
aaagttcagc acgtacgagc tcctaggcaa ccgtactctc gcccagtttc ttcccgttcg 660
aaccaaggaa ttgcaccatc tccttcagtt tgttcttggc aaggctaaag caggggaaag 720
cgtgaattta acccaagagc tgttgaaact aaccaacaac accatatcgc agatgatgct 780
gagcatgcgc tgttcgggga caggaaaccc tgccgactcg gttagaactc ttgtgcgaga 840
ggtgacagag atcttcggag agttcaacat ctcagatagc atatggtttt tgaaaaactg 900
ggacttgcag ggattcagaa agagattcga agacctgcat aggaggtttg atgcattgtt 960
ggagatgatt atgagagaac gtgagcgagt aagatcagaa agcaagcaaa agaaaggcga 1020
caatgttaac aaggtaaaag atttcctgga catcatgctt gacgttttgg aaaaggataa 1080
ctcggagtcg gaggtagatt ttaccagaaa tcacatcaag gccttaattt tggatttctt 1140
cacagccgct acagatacaa cggcaattgt acttgaatgg gcaatggcag agttgatcaa 1200
ccacccgaag ctactaaaaa tagctcagca agaaattgat caagttgtgg gaaaaggcag 1260
gttggtggaa gaatctgaca gcccacatct ccattacatc caagccatta ttaaagaaac 1320
atttcggctt cacccaccag tcccaatgat caataggaaa tcaatccaaa catgccaggt 1380
taagggatac acaatccctg ctgaatgtat ggtgtttgtg aacgtttggg ctatcggaag 1440
agatcccaag gtttggacag atccattgaa gtttcagcct gagagattcc tgaaatccga 1500
tgattctata gatgttagag ggcaacatta cgagctgttg cctttcgggt cagggaggag 1560
gggctgccct ggcgcttctt tggcgttgca ggagctgccc accactttgg ctgccatgat 1620
tcagtgcttt gactggaagg tggcgaatgg cgttgttgac atggttgaaa ggcctggact 1680
tacggctccc agggctaagg atctcgagtg tgttcctgtt gtacgcttca ctcccactct 1740
ctttgcaacc taaaagcttg cggccgcact cgagcaccac caccaccacc actgagatcc 1800
ggctgctaac aaagcccgaa agaagc 1826
<210> 2
<211> 1557
<212> DNA
<213> 布渣葉黃烷酮-2-羥基化酶基因MpF2H的cDNA序列
<400> 2
atgatgccca tgatacttga attcctatca tatctagctc ccttagttgt ttcatttctt 60
ctcgttaaga gaatactcat ctctaccaac aagcaaggtc ctaatgccaa gcagcttctt 120
cccccaggcc caatcgcctt accgatcatt ggccacctcc atctcctggg ccccttcctt 180
catcaaacct tccgcaagct ctcctcgcgc tacggtccct taatgtatct tcgtcttggc 240
tctgttggct gcgtggtggc ttccaatcca gagtttgcca aagagcttct caaaacttac 300
gagctcgcct tcgctgcccg catgcacacc gctgccatca cccacctgac ctacaactcg 360
tcctttgcct tcgcaccgta cggaacgtac tggaaattca tcagaaagtt cagcacgtac 420
gagctcctag gcaaccgtac tctcgcccag tttcttcccg ttcgaaccaa ggaattgcac 480
catctccttc agtttgttct tggcaaggct aaagcagggg aaagcgtgaa tttaacccaa 540
gagctgttga aactaaccaa caacaccata tcgcagatga tgctgagcat gcgctgttcg 600
gggacaggaa accctgccga ctcggttaga actcttgtgc gagaggtgac agagatcttc 660
ggagagttca acatctcaga tagcatatgg tttttgaaaa actgggactt gcagggattc 720
agaaagagat tcgaagacct gcataggagg tttgatgcat tgttggagat gattatgaga 780
gaacgtgagc gagtaagatc agaaagcaag caaaagaaag gcgacaatgt taacaaggta 840
aaagatttcc tggacatcat gcttgacgtt ttggaaaagg ataactcgga gtcggaggta 900
gattttacca gaaatcacat caaggcctta attttggatt tcttcacagc cgctacagat 960
acaacggcaa ttgtacttga atgggcaatg gcagagttga tcaaccaccc gaagctacta 1020
aaaatagctc agcaagaaat tgatcaagtt gtgggaaaag gcaggttggt ggaagaatct 1080
gacagcccac atctccatta catccaagcc attattaaag aaacatttcg gcttcaccca 1140
ccagtcccaa tgatcaatag gaaatcaatc caaacatgcc aggttaaggg atacacaatc 1200
cctgctgaat gtatggtgtt tgtgaacgtt tgggctatcg gaagagatcc caaggtttgg 1260
acagatccat tgaagtttca gcctgagaga ttcctgaaat ccgatgattc tatagatgtt 1320
agagggcaac attacgagct gttgcctttc gggtcaggga ggaggggctg ccctggcgct 1380
tctttggcgt tgcaggagct gcccaccact ttggctgcca tgattcagtg ctttgactgg 1440
aaggtggcga atggcgttgt tgacatggtt gaaaggcctg gacttacggc tcccagggct 1500
aaggatctcg agtgtgttcc tgttgtacgc ttcactccca ctctctttgc aacctaa 1557
<210> 3
<211> 518
<212> PRT
<213> 布渣葉黃烷酮-2-羥基化酶MpF2H氨基酸序列
<400> 3
Met Met Pro Met Ile Leu Glu Phe Leu Ser Tyr Leu Ala Pro Leu Val
1 5 10 15
Val Ser Phe Leu Leu Val Lys Arg Ile Leu Ile Ser Thr Asn Lys Gln
20 25 30
Gly Pro Asn Ala Lys Gln Leu Leu Pro Pro Gly Pro Ile Ala Leu Pro
35 40 45
Ile Ile Gly His Leu His Leu Leu Gly Pro Phe Leu His Gln Thr Phe
50 55 60
Arg Lys Leu Ser Ser Arg Tyr Gly Pro Leu Met Tyr Leu Arg Leu Gly
65 70 75 80
Ser Val Gly Cys Val Val Ala Ser Asn Pro Glu Phe Ala Lys Glu Leu
85 90 95
Leu Lys Thr Tyr Glu Leu Ala Phe Ala Ala Arg Met His Thr Ala Ala
100 105 110
Ile Thr His Leu Thr Tyr Asn Ser Ser Phe Ala Phe Ala Pro Tyr Gly
115 120 125
Thr Tyr Trp Lys Phe Ile Arg Lys Phe Ser Thr Tyr Glu Leu Leu Gly
130 135 140
Asn Arg Thr Leu Ala Gln Phe Leu Pro Val Arg Thr Lys Glu Leu His
145 150 155 160
His Leu Leu Gln Phe Val Leu Gly Lys Ala Lys Ala Gly Glu Ser Val
165 170 175
Asn Leu Thr Gln Glu Leu Leu Lys Leu Thr Asn Asn Thr Ile Ser Gln
180 185 190
Met Met Leu Ser Met Arg Cys Ser Gly Thr Gly Asn Pro Ala Asp Ser
195 200 205
Val Arg Thr Leu Val Arg Glu Val Thr Glu Ile Phe Gly Glu Phe Asn
210 215 220
Ile Ser Asp Ser Ile Trp Phe Leu Lys Asn Trp Asp Leu Gln Gly Phe
225 230 235 240
Arg Lys Arg Phe Glu Asp Leu His Arg Arg Phe Asp Ala Leu Leu Glu
245 250 255
Met Ile Met Arg Glu Arg Glu Arg Val Arg Ser Glu Ser Lys Gln Lys
260 265 270
Lys Gly Asp Asn Val Asn Lys Val Lys Asp Phe Leu Asp Ile Met Leu
275 280 285
Asp Val Leu Glu Lys Asp Asn Ser Glu Ser Glu Val Asp Phe Thr Arg
290 295 300
Asn His Ile Lys Ala Leu Ile Leu Asp Phe Phe Thr Ala Ala Thr Asp
305 310 315 320
Thr Thr Ala Ile Val Leu Glu Trp Ala Met Ala Glu Leu Ile Asn His
325 330 335
Pro Lys Leu Leu Lys Ile Ala Gln Gln Glu Ile Asp Gln Val Val Gly
340 345 350
Lys Gly Arg Leu Val Glu Glu Ser Asp Ser Pro His Leu His Tyr Ile
355 360 365
Gln Ala Ile Ile Lys Glu Thr Phe Arg Leu His Pro Pro Val Pro Met
370 375 380
Ile Asn Arg Lys Ser Ile Gln Thr Cys Gln Val Lys Gly Tyr Thr Ile
385 390 395 400
Pro Ala Glu Cys Met Val Phe Val Asn Val Trp Ala Ile Gly Arg Asp
405 410 415
Pro Lys Val Trp Thr Asp Pro Leu Lys Phe Gln Pro Glu Arg Phe Leu
420 425 430
Lys Ser Asp Asp Ser Ile Asp Val Arg Gly Gln His Tyr Glu Leu Leu
435 440 445
Pro Phe Gly Ser Gly Arg Arg Gly Cys Pro Gly Ala Ser Leu Ala Leu
450 455 460
Gln Glu Leu Pro Thr Thr Leu Ala Ala Met Ile Gln Cys Phe Asp Trp
465 470 475 480
Lys Val Ala Asn Gly Val Val Asp Met Val Glu Arg Pro Gly Leu Thr
485 490 495
Ala Pro Arg Ala Lys Asp Leu Glu Cys Val Pro Val Val Arg Phe Thr
500 505 510
Pro Thr Leu Phe Ala Thr
515
<210> 4
<211> 30
<212> DNA
<213> 正向引物MpF2H-F
<400> 4
cgggatccat gatgcccatg atacttgaat 30
<210> 5
<211> 31
<212> DNA
<213> 反向引物MpF2H-R
<400> 5
cccaagcttt taggttgcaa agagagtggg a 31
- 還沒有人留言評論。精彩留言會獲得點贊!