一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng)的制作方法
本發(fā)明涉及巡檢機(jī)器人導(dǎo)航領(lǐng)域,具體涉及一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng)。
背景技術(shù):
在電力系統(tǒng)中,電能最基本特點(diǎn)是不能大規(guī)模地存儲(chǔ),并且電能的生產(chǎn)、輸送、分配、使用都是連續(xù)的。整個(gè)電力系統(tǒng)實(shí)現(xiàn)網(wǎng)絡(luò)化互聯(lián),并引入市場(chǎng)化的機(jī)制,給人們帶來(lái)巨大利益,但同時(shí)系統(tǒng)的安全穩(wěn)定運(yùn)行卻面臨巨大的挑戰(zhàn)。電力變電站系統(tǒng)是整個(gè)電力系統(tǒng)中生產(chǎn)、輸送以及分配三大核心系統(tǒng)之一,對(duì)整個(gè)電力系統(tǒng)的安全起著重要的作用。目前對(duì)變電站的巡檢方式主要有人工巡檢和機(jī)器人巡檢。智能巡檢機(jī)器人主要通過(guò)遠(yuǎn)程控制或者自主控制方式,對(duì)變電站室外設(shè)備進(jìn)行巡視檢測(cè),可代替人工進(jìn)行一些重復(fù)、繁雜、高危險(xiǎn)性的巡檢,并能夠完成更準(zhǔn)確的常規(guī)化的巡檢任務(wù)。
變電站巡檢機(jī)器人是移動(dòng)機(jī)器人中的一種。國(guó)外對(duì)于移動(dòng)機(jī)器人的研究,不僅起步較早,而且發(fā)展也較快。相對(duì)于國(guó)外,國(guó)內(nèi)對(duì)移動(dòng)機(jī)器人的研究開始時(shí)間較晚,距離世界前沿技術(shù)水平還相對(duì)較遠(yuǎn)。但國(guó)內(nèi)正在加快移動(dòng)機(jī)器人的探究步伐。在國(guó)家"863計(jì)劃"項(xiàng)目的支持下,清華大學(xué)、哈爾濱工業(yè)大學(xué)、中國(guó)科學(xué)院等研究機(jī)構(gòu)均開始對(duì)智能移動(dòng)機(jī)器人的研究,并取得一定成果。我國(guó)對(duì)變電站智能巡檢機(jī)器人的研究開始于2002年P(guān)SI,受到了國(guó)家“863”計(jì)劃的支持。2005年10月,我國(guó)第一臺(tái)變電站設(shè)備巡檢機(jī)器人在長(zhǎng)清投入運(yùn)行,它是由山東電力科學(xué)院自主研發(fā)的。2012年2月,中國(guó)第一臺(tái)軌道式巡檢機(jī)器人投入試運(yùn)行,這標(biāo)志著中國(guó)變電站實(shí)體化機(jī)器人正處在飛快發(fā)展中,在發(fā)展自主移動(dòng)機(jī)器人技術(shù)水平的同時(shí),也有力地提高了電網(wǎng)系統(tǒng)的智能化水平。目前巡檢機(jī)器人在我國(guó)得到廣泛應(yīng)用并將在今后國(guó)家電網(wǎng)智能化巡檢工程中得到持續(xù)應(yīng)用。截止到2014年,全國(guó)至少有27個(gè)省、市、自治區(qū)、直轄市采用了變電站巡檢機(jī)器人進(jìn)行巡檢,覆蓋了南方電網(wǎng)、華北電網(wǎng)、華東電網(wǎng)以及西北電網(wǎng)。由此,有必要對(duì)變電站巡檢機(jī)器人進(jìn)行功能上的改進(jìn)或完善。
變電站巡檢機(jī)器人巡檢方式可分為正常巡檢和特殊巡檢作業(yè)。正常巡檢作業(yè)即變電站巡檢機(jī)器人巡視全部變電站設(shè)備;特殊巡檢作業(yè)即在特殊情況下對(duì)某些指定的變電站設(shè)備進(jìn)行巡視,一般指在高溫天氣、大負(fù)荷運(yùn)行、新設(shè)備投入運(yùn)行以及冰雹、雷電等惡劣環(huán)境下,對(duì)變電站特別設(shè)備進(jìn)行特殊巡檢。在變電站巡檢機(jī)器人進(jìn)行特殊巡檢時(shí),若采用目前常見的磁軌道等巡檢機(jī)器人則不具有靈活性。基于行為的變電站巡檢機(jī)器人路徑規(guī)劃實(shí)質(zhì)就是傳感器感知的環(huán)境狀態(tài)到執(zhí)行器動(dòng)作的映射。采用這種技術(shù)的巡檢機(jī)器人能夠?qū)ν饨绛h(huán)境變化做出響應(yīng),具有實(shí)時(shí)、快速的優(yōu)點(diǎn)。因此路徑規(guī)劃性能的優(yōu)劣將直接影響巡檢機(jī)器人巡檢工作的效率。強(qiáng)化學(xué)習(xí)是機(jī)器學(xué)習(xí)重要分支之一,在近幾年重新受到越來(lái)越多的關(guān)注,也得到越發(fā)廣泛和復(fù)雜的實(shí)際應(yīng)用。它通過(guò)試錯(cuò)的方式與環(huán)境進(jìn)行交互以完成學(xué)習(xí)。如果環(huán)境對(duì)其動(dòng)作評(píng)價(jià)為積極的則選擇該動(dòng)作趨勢(shì)加強(qiáng),否則便會(huì)減弱。Agent在不斷訓(xùn)練的過(guò)程中得到最優(yōu)策略。因此強(qiáng)化學(xué)習(xí)具有自主學(xué)習(xí)和在線學(xué)習(xí)的特點(diǎn),通過(guò)訓(xùn)練可用于機(jī)器人路徑規(guī)劃中,目前也已廣泛地應(yīng)用于移動(dòng)機(jī)器人的路徑規(guī)劃問題當(dāng)中。
雖然強(qiáng)化學(xué)習(xí)有著諸多優(yōu)點(diǎn)以及值得期待的應(yīng)用前景,但強(qiáng)化學(xué)習(xí)也存在著收斂速度慢、“維數(shù)災(zāi)難”、平衡探索與利用、時(shí)間信度分配等問題。強(qiáng)化學(xué)習(xí)收斂速度慢的原因之一是沒有教師信號(hào),只能通過(guò)探索并依靠環(huán)境評(píng)價(jià)逐漸改進(jìn)以獲得最優(yōu)動(dòng)作策略。為進(jìn)一步加快強(qiáng)化學(xué)習(xí)收斂速度,啟發(fā)式強(qiáng)化學(xué)習(xí)通過(guò)給強(qiáng)化學(xué)習(xí)注入一定的先驗(yàn)知識(shí),有效提高強(qiáng)化學(xué)習(xí)的收斂速度。Torrey等通過(guò)遷移學(xué)習(xí)為強(qiáng)化學(xué)習(xí)算法注入先驗(yàn)經(jīng)驗(yàn)以提高收斂速度;但是遷移學(xué)習(xí)所注入的先驗(yàn)知識(shí)是固定的,即使有不合理規(guī)則也無(wú)法在訓(xùn)練過(guò)程中在線修正。Bianchi等通過(guò)給傳統(tǒng)強(qiáng)化學(xué)習(xí)算法添加啟發(fā)函數(shù),在訓(xùn)練過(guò)程中結(jié)合使用值函數(shù)和啟發(fā)函數(shù)來(lái)選擇動(dòng)作,提出了啟發(fā)式強(qiáng)化學(xué)習(xí)(Heuristically Accelerated Reinforcement Learning,HARL)算法模型。啟發(fā)式強(qiáng)化學(xué)習(xí)最重要的特點(diǎn)是在線更新啟發(fā)函數(shù),以不斷增強(qiáng)表現(xiàn)更好的動(dòng)作的啟發(fā)函數(shù)。方敏等在啟發(fā)式強(qiáng)化學(xué)習(xí)算法基礎(chǔ)上提出一種基于狀態(tài)回溯的啟發(fā)式強(qiáng)化學(xué)習(xí)方法,通過(guò)引入代價(jià)函數(shù)描述重復(fù)動(dòng)作的重要性,結(jié)合動(dòng)作獎(jiǎng)賞及動(dòng)作代價(jià)提出一種新的啟發(fā)函數(shù)定義以進(jìn)一步提高收斂速度;但是該方法只是針對(duì)重復(fù)性動(dòng)作的重要性進(jìn)行評(píng)估。
技術(shù)實(shí)現(xiàn)要素:
為解決上述問題,本發(fā)明提供了一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng)。
為實(shí)現(xiàn)上述目的,本發(fā)明采取的技術(shù)方案為:
一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng),基于信息強(qiáng)度引導(dǎo)啟發(fā)式Q學(xué)習(xí),包括中控模塊、距離傳感器模塊、RFID模塊和運(yùn)動(dòng)控制模塊,所述距離傳感器模塊由7個(gè)距離傳感器組成,用于將所測(cè)得的距離數(shù)據(jù)傳送給中控模塊用于巡檢機(jī)器人的避障;RFID模塊由定點(diǎn)分布的RFID標(biāo)簽和巡檢機(jī)器人上的RFID讀寫器組成,用于將RFID地標(biāo)數(shù)據(jù)和目標(biāo)地點(diǎn)位置數(shù)據(jù)傳送給中控模塊用于巡檢機(jī)器人的位置標(biāo)定和目標(biāo)位置確定;運(yùn)動(dòng)控制模塊接受來(lái)自中控模塊的命令確定運(yùn)動(dòng)方向;中控模塊為巡檢機(jī)器人的Agent,用于接收其他模塊傳出來(lái)的數(shù)據(jù)確定行動(dòng)策略,并向運(yùn)動(dòng)控制模塊傳送命令以規(guī)劃路徑。
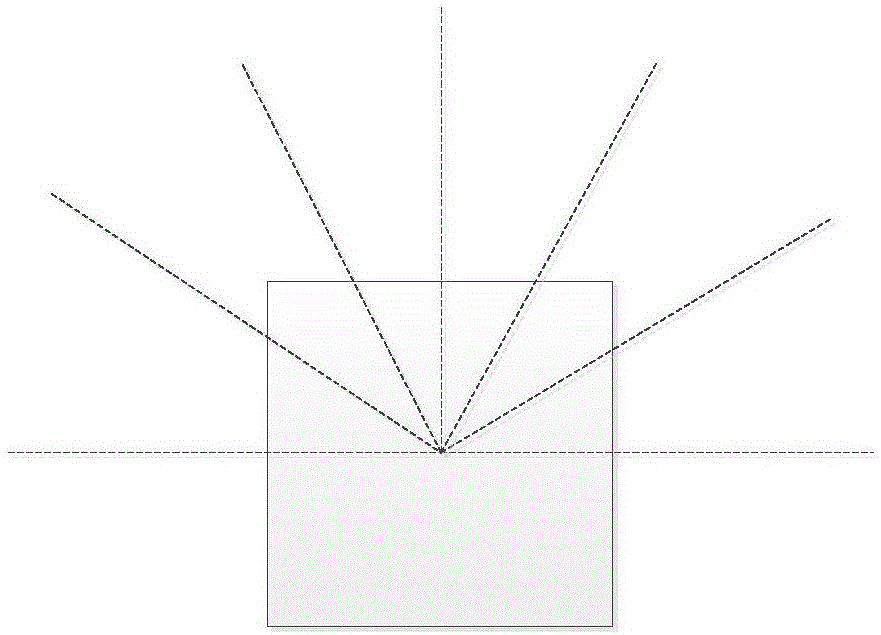
其中,以巡檢機(jī)器人正前方為零度線,七個(gè)距離傳感器依次以-90°、-60°、-30°、0°、30°、60°、90°裝配在巡檢機(jī)器人體側(cè)。
其中,通過(guò)以下步驟完成巡檢機(jī)器人獎(jiǎng)懲機(jī)制的建立:
步驟1:設(shè)定移動(dòng)獎(jiǎng)懲機(jī)制:為鼓勵(lì)機(jī)器人以盡可能少的步數(shù)移動(dòng)到目標(biāo)點(diǎn),每次執(zhí)行一個(gè)動(dòng)作都會(huì)產(chǎn)生一個(gè)懲罰回報(bào)值;同時(shí)為鼓勵(lì)機(jī)器人提前做出判斷,在非必要情況下盡量避免大角度移動(dòng),大角度移動(dòng)的懲罰回報(bào)值更大一些。具體設(shè)置為:在動(dòng)作屬于{-30°,0°,30°}時(shí),懲罰回報(bào)值為-0.2;動(dòng)作屬于{-60°,60°}時(shí),懲罰回報(bào)值為-0.5;
步驟2:設(shè)定目標(biāo)地點(diǎn)獎(jiǎng)懲機(jī)制:采用RFID標(biāo)定巡檢機(jī)器人與目標(biāo)設(shè)備的位置;在巡檢機(jī)器人每一步動(dòng)作后,計(jì)算當(dāng)前位置與目標(biāo)地點(diǎn)之間的距離d,將-d(即令所計(jì)算的距離值取反)作為此時(shí)的目標(biāo)回報(bào)值;同時(shí),將移動(dòng)到目標(biāo)地點(diǎn)的回報(bào)值設(shè)置為+100;
步驟3:設(shè)置巡檢機(jī)器人避障回報(bào)值:采用兩級(jí)避障回報(bào)值等級(jí):當(dāng)七個(gè)距離傳感器有任何一個(gè)測(cè)量結(jié)果小于0.1米時(shí),認(rèn)定機(jī)器人已經(jīng)撞到障礙物(包括設(shè)備和墻壁等),此時(shí)懲罰回報(bào)值為-100,并將此作為終止?fàn)顟B(tài)退出當(dāng)前episode進(jìn)入下一個(gè)episode的學(xué)習(xí);當(dāng)七個(gè)距離傳感器有任何一個(gè)測(cè)量結(jié)果大于0.1并且小于半個(gè)機(jī)器人車身長(zhǎng)時(shí),為鼓勵(lì)機(jī)器人及早避障,設(shè)置此時(shí)的懲罰回報(bào)值為-2。
其中,所述中控模塊基于以下步驟完成巡檢機(jī)器人路徑的規(guī)劃:
步驟1:初始化Agent
初始化狀態(tài)-動(dòng)作值函數(shù)、啟發(fā)函數(shù);確定目標(biāo)設(shè)備位置和巡檢所在位置;
步驟2:設(shè)計(jì)表H記錄信息強(qiáng)度
將表H定義為四元組<si,ai,p(si,ai),fmax>;其中,si為需要更新信息強(qiáng)度的信息狀態(tài);ai為需要更新信息強(qiáng)度的信息動(dòng)作;p(si,ai)為更新后的信息強(qiáng)度,信息強(qiáng)度為與適應(yīng)度呈正比的標(biāo)量;fmax為此前記錄的信息狀態(tài)si適應(yīng)度最大值;
步驟3:更新狀態(tài)-動(dòng)作值函數(shù)
Q學(xué)習(xí)狀態(tài)-動(dòng)作值函數(shù)的更新規(guī)則如下所示:
步驟4:更新適應(yīng)度最大值
將適應(yīng)度值定義為每幕(episode)訓(xùn)練中Agent從初始狀態(tài)移動(dòng)到目標(biāo)狀態(tài)的折扣累計(jì)回報(bào);其定義方式為其中,β為適應(yīng)度折扣因子,R為Agent每次移動(dòng)所獲的回報(bào);當(dāng)Agent完成一幕訓(xùn)練所獲得的適應(yīng)度值大于表H中的最大適應(yīng)度時(shí),則進(jìn)行適應(yīng)度最大值的更新;
步驟5:更新信息強(qiáng)度
若適應(yīng)度最大值更新,則相應(yīng)地更新信息強(qiáng)度,信息強(qiáng)度p(si,ai)的更新規(guī)則如下:
其中,at表示Agent最新情節(jié)的學(xué)習(xí)中在狀態(tài)si采用的動(dòng)作,ai表示表H中的信息動(dòng)作,fmax表示表H中的適應(yīng)度最大值;
步驟6:確定基于信息強(qiáng)度的啟發(fā)函數(shù)
為使所獲得的信息強(qiáng)度大小直接反映在動(dòng)作選擇上,將信息強(qiáng)度融入到啟發(fā)函數(shù);通過(guò)設(shè)置影響量級(jí)參數(shù)來(lái)控制信息強(qiáng)度對(duì)動(dòng)作選擇的影響程度;啟發(fā)函數(shù)更新方式定義如下:
其中,πp(st)為在信息強(qiáng)度啟發(fā)下的最優(yōu)動(dòng)作;是通過(guò)最大信息強(qiáng)度與信息強(qiáng)度總和比重來(lái)表示的該動(dòng)作的重要性,記為h;U是信息強(qiáng)度對(duì)動(dòng)作選擇的影響量級(jí)參數(shù),U越大則信息強(qiáng)度的影響越大;
在以上更新規(guī)則中,只有信息強(qiáng)度啟發(fā)下最優(yōu)動(dòng)作的啟發(fā)函數(shù)進(jìn)行更新,作用于動(dòng)作策略的選擇,非信息素強(qiáng)度啟發(fā)下最優(yōu)動(dòng)作的啟發(fā)函數(shù)都被設(shè)為0;當(dāng)信息素強(qiáng)度啟發(fā)下最優(yōu)動(dòng)作的值函數(shù)小于另一動(dòng)作時(shí),通過(guò)疊加啟發(fā)函數(shù)使動(dòng)作選擇更加傾向于信息素強(qiáng)度較大的動(dòng)作,而不是在不完全探索情況下選擇值函數(shù)較大的動(dòng)作;
步驟7:在啟發(fā)函數(shù)和值函數(shù)作用下確定策略
信息強(qiáng)度引導(dǎo)的啟發(fā)式Q學(xué)習(xí)的動(dòng)作選擇策略采用Boltzmann機(jī)制,其更新方式規(guī)則如下:
當(dāng)采用Boltzmann機(jī)制時(shí),若當(dāng)前最大動(dòng)作值函數(shù)下的動(dòng)作不是信息素強(qiáng)度下最優(yōu)動(dòng)作,則通過(guò)Q(st,a)+H(st,a),加大信息素強(qiáng)度下最優(yōu)動(dòng)作的選擇概率;同時(shí)使用Boltzmann機(jī)制,在不同動(dòng)作信息素強(qiáng)度差距不大的情況下,使得最大動(dòng)作值函數(shù)下的動(dòng)作和信息素強(qiáng)度下最優(yōu)動(dòng)作的概率相近,從而避免陷入信息素強(qiáng)度下的局部最優(yōu);在信息素強(qiáng)度差距較大的情況下,使得動(dòng)作選擇概率偏向于信息素強(qiáng)度下最優(yōu)動(dòng)作,從而有助于算法收斂。
本發(fā)明具有以下有益效果:
采用強(qiáng)化學(xué)習(xí)的路徑規(guī)劃系統(tǒng)完成特殊天氣等條件下對(duì)重點(diǎn)指定設(shè)備進(jìn)行特殊巡檢任務(wù),避免磁軌道等路徑規(guī)劃方法的軌道維護(hù)工作;提出可在線更新的信息強(qiáng)度引導(dǎo)的啟發(fā)式Q學(xué)習(xí)算法,該算法在啟發(fā)式強(qiáng)化學(xué)習(xí)算法的基礎(chǔ)上引入依據(jù)每次訓(xùn)練回報(bào)進(jìn)行在線更新的信息強(qiáng)度,通過(guò)結(jié)合強(qiáng)弱程度不同的動(dòng)作信息強(qiáng)度和狀態(tài)-動(dòng)作值函數(shù)來(lái)確定策略,從而提高算法收斂速度。
附圖說(shuō)明
圖1為本發(fā)明實(shí)施例一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng)的系統(tǒng)框圖。
圖2為本發(fā)明實(shí)施例中7個(gè)距離傳感器的安裝示意圖。
圖3為本發(fā)明實(shí)施例中中控模塊規(guī)劃路徑的流程圖。
圖4為本發(fā)明實(shí)施例中變電站仿真實(shí)驗(yàn)圖。
圖5為本發(fā)明實(shí)施例中累計(jì)成功率結(jié)果圖。
圖6為本發(fā)明實(shí)施例中算法平均步數(shù)結(jié)果圖。
圖7為本發(fā)明實(shí)施例中算法平均累計(jì)回報(bào)結(jié)果圖。
具體實(shí)施方式
為了使本發(fā)明的目的及優(yōu)點(diǎn)更加清楚明白,以下結(jié)合實(shí)施例對(duì)本發(fā)明進(jìn)行進(jìn)一步詳細(xì)說(shuō)明。應(yīng)當(dāng)理解,此處所描述的具體實(shí)施例僅僅用以解釋本發(fā)明,并不用于限定本發(fā)明。
如圖1所示,本發(fā)明實(shí)施例提供了一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng),基于信息強(qiáng)度引導(dǎo)啟發(fā)式Q學(xué)習(xí),包括中控模塊、距離傳感器模塊、RFID模塊和運(yùn)動(dòng)控制模塊,所述距離傳感器模塊由7個(gè)距離傳感器組成,用于將所測(cè)得的距離數(shù)據(jù)傳送給中控模塊用于巡檢機(jī)器人的避障;RFID模塊由定點(diǎn)分布的RFID標(biāo)簽和巡檢機(jī)器人上的RFID讀寫器組成,用于將RFID地標(biāo)數(shù)據(jù)和目標(biāo)地點(diǎn)位置數(shù)據(jù)傳送給中控模塊用于巡檢機(jī)器人的位置標(biāo)定和目標(biāo)位置確定;運(yùn)動(dòng)控制模塊接受來(lái)自中控模塊的命令確定運(yùn)動(dòng)方向;中控模塊為巡檢機(jī)器人的Agent,用于接收其他模塊傳出來(lái)的數(shù)據(jù)確定行動(dòng)策略,并向運(yùn)動(dòng)控制模塊傳送命令以規(guī)劃路徑。
如圖2所示,以巡檢機(jī)器人正前方為零度線,七個(gè)距離傳感器依次以-90°、-60°、-30°、0°、30°、60°、90°裝配在巡檢機(jī)器人體側(cè),相應(yīng)地,機(jī)器人運(yùn)動(dòng)模式設(shè)定為向-60°、-30°、0°、30°、60°方向移動(dòng)。
其中,通過(guò)以下步驟完成巡檢機(jī)器人獎(jiǎng)懲機(jī)制的建立:
步驟1:設(shè)定移動(dòng)獎(jiǎng)懲機(jī)制:為鼓勵(lì)機(jī)器人以盡可能少的步數(shù)移動(dòng)到目標(biāo)點(diǎn),每次執(zhí)行一個(gè)動(dòng)作都會(huì)產(chǎn)生一個(gè)懲罰回報(bào)值;同時(shí)為鼓勵(lì)機(jī)器人提前做出判斷,在非必要情況下盡量避免大角度移動(dòng),大角度移動(dòng)的懲罰回報(bào)值更大一些。具體設(shè)置為:在動(dòng)作屬于{-30°,0°,30°}時(shí),懲罰回報(bào)值為-0.2;動(dòng)作屬于{-60°,60°}時(shí),懲罰回報(bào)值為-0.5;
步驟2:設(shè)定目標(biāo)地點(diǎn)獎(jiǎng)懲機(jī)制:采用RFID標(biāo)定巡檢機(jī)器人與目標(biāo)設(shè)備的位置;在巡檢機(jī)器人每一步動(dòng)作后,計(jì)算當(dāng)前位置與目標(biāo)地點(diǎn)之間的距離d,將-d(即令所計(jì)算的距離值取反)作為此時(shí)的目標(biāo)回報(bào)值;同時(shí),將移動(dòng)到目標(biāo)地點(diǎn)的回報(bào)值設(shè)置為+100;
步驟3:設(shè)置巡檢機(jī)器人避障回報(bào)值:采用兩級(jí)避障回報(bào)值等級(jí):當(dāng)七個(gè)距離傳感器有任何一個(gè)測(cè)量結(jié)果小于0.1米時(shí),認(rèn)定機(jī)器人已經(jīng)撞到障礙物(包括設(shè)備和墻壁等),此時(shí)懲罰回報(bào)值為-100,并將此作為終止?fàn)顟B(tài)退出當(dāng)前episode進(jìn)入下一個(gè)episode的學(xué)習(xí);當(dāng)七個(gè)距離傳感器有任何一個(gè)測(cè)量結(jié)果大于0.1并且小于半個(gè)機(jī)器人車身長(zhǎng)時(shí),為鼓勵(lì)機(jī)器人及早避障,設(shè)置此時(shí)的懲罰回報(bào)值為-2。
如圖3所示,所述中控模塊基于以下步驟完成巡檢機(jī)器人路徑的規(guī)劃:
步驟1:初始化Agent
初始化狀態(tài)-動(dòng)作值函數(shù)、啟發(fā)函數(shù);確定目標(biāo)設(shè)備位置和巡檢所在位置;
步驟2:設(shè)計(jì)表H記錄信息強(qiáng)度
將表H定義為四元組<si,ai,p(si,ai),fmax>;其中,si為需要更新信息強(qiáng)度的信息狀態(tài);ai為需要更新信息強(qiáng)度的信息動(dòng)作;p(si,ai)為更新后的信息強(qiáng)度,信息強(qiáng)度為與適應(yīng)度呈正比的標(biāo)量;fmax為此前記錄的信息狀態(tài)si適應(yīng)度最大值;
步驟3:更新狀態(tài)-動(dòng)作值函數(shù)
Q學(xué)習(xí)狀態(tài)-動(dòng)作值函數(shù)的更新規(guī)則如下所示:
步驟4:更新適應(yīng)度最大值
將適應(yīng)度值定義為每幕(episode)訓(xùn)練中Agent從初始狀態(tài)移動(dòng)到目標(biāo)狀態(tài)的折扣累計(jì)回報(bào);其定義方式為其中,β為適應(yīng)度折扣因子,R為Agent每次移動(dòng)所獲的回報(bào);當(dāng)Agent完成一幕訓(xùn)練所獲得的適應(yīng)度值大于表H中的最大適應(yīng)度時(shí),則進(jìn)行適應(yīng)度最大值的更新;
步驟5:更新信息強(qiáng)度
若適應(yīng)度最大值更新,則相應(yīng)地更新信息強(qiáng)度,信息強(qiáng)度p(si,ai)的更新規(guī)則如下:
其中,at表示Agent最新情節(jié)的學(xué)習(xí)中在狀態(tài)si采用的動(dòng)作,ai表示表H中的信息動(dòng)作,fmax表示表H中的適應(yīng)度最大值;
通過(guò)以上更新規(guī)則,使信息強(qiáng)度p(si,ai)由適應(yīng)度f(wàn)與表H中適應(yīng)度最大值fmax的差值程度所決定;當(dāng)f大于表H中儲(chǔ)存的fmax時(shí),信息強(qiáng)度則需要更新,即表H需要更新;基于上述更新規(guī)則,該算法在保留此前信息強(qiáng)度的同時(shí),使按照適應(yīng)度差值程度更新的信息強(qiáng)度體現(xiàn)出不同信息動(dòng)作的重要性;
假設(shè)ai∈{a1,a2…aN},且在訓(xùn)練過(guò)程中執(zhí)行am時(shí)獲得最大適應(yīng)度f(wàn)1,表H中適應(yīng)度最大值在更新前為fmax=f0;則按照上式更新結(jié)果如下:(I)若ai=am,則p(si,am)=1;(II)若ai≠am:(1)當(dāng)p(si,am)=0時(shí),更新后的p(si,am)仍為0;(2)當(dāng)p(si,am)=1時(shí),更新后的(3)當(dāng)時(shí),更新后的
步驟6:確定基于信息強(qiáng)度的啟發(fā)函數(shù)
為使所獲得的信息強(qiáng)度大小直接反映在動(dòng)作選擇上,將信息強(qiáng)度融入到啟發(fā)函數(shù);通過(guò)設(shè)置影響量級(jí)參數(shù)來(lái)控制信息強(qiáng)度對(duì)動(dòng)作選擇的影響程度;啟發(fā)函數(shù)更新方式定義如下:
其中,πp(st)為在信息強(qiáng)度啟發(fā)下的最優(yōu)動(dòng)作;是通過(guò)最大信息強(qiáng)度與信息強(qiáng)度總和比重來(lái)表示的該動(dòng)作的重要性,記為h;U是信息強(qiáng)度對(duì)動(dòng)作選擇的影響量級(jí)參數(shù),U越大則信息強(qiáng)度的影響越大;
在以上更新規(guī)則中,只有信息強(qiáng)度啟發(fā)下最優(yōu)動(dòng)作的啟發(fā)函數(shù)進(jìn)行更新,作用于動(dòng)作策略的選擇,非信息素強(qiáng)度啟發(fā)下最優(yōu)動(dòng)作的啟發(fā)函數(shù)都被設(shè)為0。當(dāng)信息素強(qiáng)度啟發(fā)下最優(yōu)動(dòng)作的值函數(shù)小于另一動(dòng)作時(shí),通過(guò)疊加啟發(fā)函數(shù)使動(dòng)作選擇更加傾向于信息素強(qiáng)度較大的動(dòng)作,而不是在不完全探索情況下選擇值函數(shù)較大的動(dòng)作。注意,如上式所示,啟發(fā)函數(shù)并不是直接作用于動(dòng)作值函數(shù),使動(dòng)作值函數(shù)發(fā)生變化;而是進(jìn)行疊加操作,將疊加函數(shù)用于決定動(dòng)作選擇策略,繼而此情節(jié)學(xué)習(xí)的回報(bào)作用于動(dòng)作值函數(shù)的更新。
步驟7:在啟發(fā)函數(shù)和值函數(shù)作用下確定策略
信息強(qiáng)度引導(dǎo)的啟發(fā)式Q學(xué)習(xí)的動(dòng)作選擇策略采用Boltzmann機(jī)制,其更新方式規(guī)則如下:
當(dāng)采用Boltzmann機(jī)制時(shí),若當(dāng)前最大動(dòng)作值函數(shù)下的動(dòng)作不是信息素強(qiáng)度下最優(yōu)動(dòng)作,則通過(guò)Q(st,a)+H(st,a),加大信息素強(qiáng)度下最優(yōu)動(dòng)作的選擇概率;同時(shí)使用Boltzmann機(jī)制,在不同動(dòng)作信息素強(qiáng)度差距不大的情況下,使得最大動(dòng)作值函數(shù)下的動(dòng)作和信息素強(qiáng)度下最優(yōu)動(dòng)作的概率相近,從而避免陷入信息素強(qiáng)度下的局部最優(yōu);在信息素強(qiáng)度差距較大的情況下,使得動(dòng)作選擇概率偏向于信息素強(qiáng)度下最優(yōu)動(dòng)作,從而有助于算法收斂。此外,Boltzmann機(jī)制使得其他動(dòng)作也有一定概率被選擇,從而促進(jìn)算法進(jìn)行探索。
以變電站環(huán)境作為背景設(shè)置仿真環(huán)境:如圖4所示,實(shí)心紅色區(qū)域代表以設(shè)備為主的障礙物,四周代表墻壁障礙。起點(diǎn)位置設(shè)置為(1,1),目標(biāo)位置設(shè)置為(18,17);目標(biāo)位置回報(bào)值為100,其余位置回報(bào)值均按照該位置與目標(biāo)位置的距離差的大小分布在[0,2]的范圍內(nèi),距離差越小則回報(bào)值越大;為鼓勵(lì)A(yù)gent以最少步數(shù)找到目標(biāo)位置,Agent每執(zhí)行一個(gè)動(dòng)作,會(huì)得到一個(gè)-1的回報(bào)值;Agent動(dòng)作空間為{1,2,3,4},分別代表向上、向下、向左、向右;若Agent撞到障礙物或者墻壁,則退回起點(diǎn),并得到-10的懲罰。
在采用不同方法進(jìn)行仿真實(shí)驗(yàn)時(shí),均設(shè)置為相同參數(shù),如表1所示。為盡可能保證實(shí)驗(yàn)結(jié)果準(zhǔn)確,對(duì)每種方法分別進(jìn)行20次實(shí)驗(yàn),每次實(shí)驗(yàn)的episode設(shè)置為3000,取該20次實(shí)驗(yàn)的數(shù)據(jù)均值作為實(shí)驗(yàn)結(jié)果進(jìn)行分析。其中,PSG-HAQL的信息強(qiáng)度影響量級(jí)參數(shù)設(shè)置為1.5;HAQL為文獻(xiàn)[8]中的啟發(fā)式Q學(xué)習(xí),H-HAQL、L-HAQL的η分別設(shè)置為1.5、0.1,用以與PSG-HAQL作對(duì)比實(shí)驗(yàn)。
表1仿真實(shí)驗(yàn)參數(shù)設(shè)置
實(shí)驗(yàn)結(jié)果及分析
采用上述仿真環(huán)境以及參數(shù)設(shè)置,分別采用PSG-HAQL算法、H-HAQL算法、L-HAQL算法、Standard-QL算法進(jìn)行仿真實(shí)驗(yàn)。
本文給出以下3個(gè)參數(shù)描述實(shí)驗(yàn)結(jié)果:
學(xué)習(xí)過(guò)程累計(jì)成功率:到達(dá)目標(biāo)位置的學(xué)習(xí)情節(jié)數(shù)與學(xué)習(xí)情節(jié)總數(shù)的比值;
每情節(jié)學(xué)習(xí)所用步數(shù):該情節(jié)學(xué)習(xí)找到目標(biāo)位置所用的步數(shù);如果沒有到達(dá)目標(biāo)地點(diǎn)則步數(shù)為0;
每情節(jié)學(xué)習(xí)所獲得累計(jì)回報(bào)值:該情節(jié)學(xué)習(xí)從起始狀態(tài)到達(dá)終止?fàn)顟B(tài)(障礙物或者目標(biāo)位置)所獲得的累計(jì)回報(bào)值。
為對(duì)四種算法性能憂慮有一個(gè)總體的認(rèn)識(shí),首先觀察學(xué)習(xí)過(guò)程累計(jì)成功率曲線,如圖5所示,橫軸表示學(xué)習(xí)情節(jié)數(shù)episode,縱軸表示成功率。由圖5,PSG-HAQL、H-HAQL的曲線明顯優(yōu)于L-HAQL、Standard-QL的成功率曲線,印證了文獻(xiàn)[8]中啟發(fā)函數(shù)可以加快強(qiáng)化學(xué)習(xí)算法的學(xué)習(xí)速度。此外,PSG-HAQL的成功率曲線最早開始上升,且曲線初始階段斜率最大,說(shuō)明在訓(xùn)練初期PSG-HAQL到達(dá)目標(biāo)位置的頻率最高;在總成功率上,PSG-HAQL也均高于其他三種算法。
成功率曲線只是總體上針對(duì)每情節(jié)學(xué)習(xí)是否到達(dá)目標(biāo)位置進(jìn)行統(tǒng)計(jì),并不能直接由此判定每情節(jié)學(xué)習(xí)四種算法效果。為此統(tǒng)計(jì)每情節(jié)學(xué)習(xí)所用步數(shù),曲線如圖6所示,橫軸表示學(xué)習(xí)情節(jié)數(shù),縱軸表示每情節(jié)學(xué)習(xí)所用的步數(shù)。盡管在20次實(shí)驗(yàn)均值的數(shù)據(jù)統(tǒng)計(jì)結(jié)果中,PSG-HAQL最先尋找到目標(biāo)位置;但在實(shí)驗(yàn)中發(fā)現(xiàn),在某一次實(shí)驗(yàn)中四種算法第一次尋找到目標(biāo)位置所用步數(shù)大小排序并不能確定,即四種算法均有可能最先找到目標(biāo)位置,這是由于四種算法起始探索方向是隨機(jī)的。在圖6中,PSG-HAQL算法由于采用啟發(fā)函數(shù),其策略根據(jù)適應(yīng)度情況選擇動(dòng)作,所以步數(shù)整體比其他三種都要少;H-HAQL算法雖然也有一個(gè)較大的啟發(fā)函數(shù),但較易陷入局部,所以步數(shù)總體情況不如PSG-HAQL;而L-HAQL由于啟發(fā)函數(shù)強(qiáng)度不大,所以和Standard-QL類似,雖然偶爾步數(shù)達(dá)到最少,但有較大波動(dòng)。總體結(jié)果上,PSG-HAQL可最快得到穩(wěn)定的步數(shù)最少的動(dòng)作選擇策略。
Agent可通過(guò)不同路徑到達(dá)目標(biāo)位置,不同路徑所需步數(shù)大多不同;但也有可能不同路徑的步數(shù)相同。為此設(shè)置每情節(jié)學(xué)習(xí)所獲得累計(jì)回報(bào)值結(jié)果參數(shù),如圖7所示,橫軸表示學(xué)習(xí)情節(jié)數(shù),縱軸表示每情節(jié)學(xué)習(xí)所獲得累計(jì)回報(bào)值結(jié)果參數(shù)。在圖7中,每情節(jié)學(xué)習(xí)所獲得累計(jì)回報(bào)值整體情況和每情節(jié)學(xué)習(xí)所用步數(shù)曲線相類似。PSG-HAQL大概在情節(jié)數(shù)為400時(shí)達(dá)到穩(wěn)定,H-HAQL大概在情節(jié)數(shù)為1100時(shí)穩(wěn)定,而L-HAQL和Standard-QL則依然波動(dòng)較大,且并未達(dá)到最優(yōu)動(dòng)作。結(jié)果表明,PSG-HAQL能更快速的得到累計(jì)回報(bào)值較高的動(dòng)作策略,其他算法在該時(shí)間內(nèi)還無(wú)法得到穩(wěn)定的等同回報(bào)程度的策略,從而表明PSG-HAQL可有效提高動(dòng)作選擇策略的收斂速度。
PSG-HAQL算法將蜂群信息傳遞的思想結(jié)合到啟發(fā)式Q學(xué)習(xí)方法:Agent在訓(xùn)練過(guò)程中不斷獲得不同策略的適應(yīng)度以在線更新該策略信息強(qiáng)度,將信息強(qiáng)度作為Q學(xué)習(xí)啟發(fā)函數(shù),使Agent有更高概率去選擇信息強(qiáng)度高的策略。所以,信息強(qiáng)度引導(dǎo)的啟發(fā)式Q學(xué)習(xí)(PSG-HAQL)算法能夠更高效的尋找到最優(yōu)策略,從而進(jìn)一步縮減訓(xùn)練時(shí)間。
以上所述僅是本發(fā)明的優(yōu)選實(shí)施方式,應(yīng)當(dāng)指出,對(duì)于本技術(shù)領(lǐng)域的普通技術(shù)人員來(lái)說(shuō),在不脫離本發(fā)明原理的前提下,還可以作出若干改進(jìn)和潤(rùn)飾,這些改進(jìn)和潤(rùn)飾也應(yīng)視為本發(fā)明的保護(hù)范圍。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!
- 用于GIS/HGIS變電站的勘測(cè)機(jī)器人的制造方法與工藝
- 用于GIS/HGIS變電站的搜救機(jī)器人的制造方法與工藝
- 變電站集中調(diào)度系統(tǒng)及其方法與制造工藝
- 基于Android平臺(tái)的變電站巡檢機(jī)器人控制系統(tǒng)及方法與制造工藝
- 一種懸掛式巡檢機(jī)器人裝置的制造方法
- 一種機(jī)器人電站巡檢系統(tǒng)及方法與制造工藝
- 一種機(jī)器人巡檢專用圍欄的制造方法與工藝
- 四輪全向轉(zhuǎn)動(dòng)巡檢機(jī)器人底盤的制造方法與工藝
- 一種地面巡檢機(jī)器人隱藏式自動(dòng)充電裝置的制造方法
- 變電站GIS設(shè)備SF6氣體檢漏機(jī)器人的制造方法與工藝
- 一種四分裂高壓直流輸電線磁力驅(qū)動(dòng)巡檢機(jī)器人的制造方法與工藝
- 一種基于廣域互聯(lián)網(wǎng)通訊的巡檢機(jī)器人系統(tǒng)的制造方法與工藝
- 一種電力系統(tǒng)巡檢機(jī)器人的制造方法與工藝
- 核電站智能巡檢裝置的制造方法
- 一種場(chǎng)地巡檢機(jī)器人的移動(dòng)底盤及移動(dòng)方法與流程
- 智能變電站過(guò)程層網(wǎng)絡(luò)設(shè)備自動(dòng)配置系統(tǒng)及方法與流程
- 用于GIS/HGIS變電站的勘測(cè)機(jī)器人的制造方法與工藝
- 用于GIS/HGIS變電站的搜救機(jī)器人的制造方法與工藝
- 一種基于三維設(shè)計(jì)平臺(tái)的變電站設(shè)備智能布置方法與制造工藝
- 智能巡檢機(jī)器人和方法與制造工藝
- 一種基于X射線機(jī)器人的變電站檢測(cè)系統(tǒng)的制作方法與工藝
- 一種有效的變電站智能巡檢機(jī)器人的制作方法與工藝
- 一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng)的制作方法與工藝
- 一種小區(qū)變電站巡檢手持裝置的制作方法
- 一種變電站巡檢機(jī)器人自動(dòng)避障方法與流程
- 變電站巡檢機(jī)器人定位方法及定位裝置與流程
- 一種架空纜索的變電站智能巡檢機(jī)器人的制作方法與工藝
- 一種變電站智能巡檢機(jī)器人行走架空纜索的制作方法與工藝
- 一種適用于變電站巡檢機(jī)器人的可調(diào)式雙電機(jī)固定裝置的制作方法
- 一種適用于智能變電站用的高精度電池巡檢測(cè)量電路的制作方法與工藝
- 一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng)的制作方法與工藝
- 一種小區(qū)變電站巡檢手持裝置的制作方法
- 一種變電站巡檢機(jī)器人自動(dòng)避障方法與流程
- 變電站巡檢機(jī)器人定位方法及定位裝置與流程
- 一種架空纜索的變電站智能巡檢機(jī)器人的制作方法與工藝
- 一種變電站智能巡檢機(jī)器人行走架空纜索的制作方法與工藝
- 一種適用于變電站巡檢機(jī)器人的可調(diào)式雙電機(jī)固定裝置的制作方法
- 一種適用于智能變電站用的高精度電池巡檢測(cè)量電路的制作方法與工藝
- 一種機(jī)器人電站巡檢系統(tǒng)及方法與流程
- 一種機(jī)器人電站巡檢系統(tǒng)及方法與流程
- 一種變電站巡檢機(jī)器人路徑規(guī)劃系統(tǒng)的制作方法與工藝
- 一種變電站巡檢機(jī)器人自動(dòng)避障方法與流程
- 變電站巡檢機(jī)器人定位方法及定位裝置與流程
- 一種架空纜索的變電站智能巡檢機(jī)器人的制作方法與工藝
- 一種變電站智能巡檢機(jī)器人行走架空纜索的制作方法與工藝
- 一種適用于變電站巡檢機(jī)器人的可調(diào)式雙電機(jī)固定裝置的制作方法
- 一種適用于智能變電站用的高精度電池巡檢測(cè)量電路的制作方法與工藝
- 一種機(jī)器人電站巡檢系統(tǒng)及方法與流程
- 一種機(jī)器人電站巡檢系統(tǒng)及方法與流程
- 基于可穿戴增強(qiáng)現(xiàn)實(shí)的變電站雙向智能巡檢系統(tǒng)及方法與流程
- 變電站巡檢機(jī)器人定位方法及定位裝置與流程
- 一種架空纜索的變電站智能巡檢機(jī)器人的制作方法與工藝
- 一種變電站智能巡檢機(jī)器人行走架空纜索的制作方法與工藝
- 一種適用于變電站巡檢機(jī)器人的可調(diào)式雙電機(jī)固定裝置的制作方法
- 一種機(jī)器人電站巡檢系統(tǒng)及方法與流程
- 一種機(jī)器人電站巡檢系統(tǒng)及方法與流程
- 一種機(jī)器人電站巡檢系統(tǒng)及方法與流程
- 一種變電站巡檢機(jī)器人導(dǎo)航控制系統(tǒng)及方法與流程
- 一種變電站智能巡檢機(jī)器人定位坐標(biāo)的自動(dòng)校正裝置及校正方法與流程
- 一種變電站巡檢機(jī)器人智能續(xù)航無(wú)線補(bǔ)償系統(tǒng)的制作方法與工藝