作圖方法、裝置及作圖設備與流程
本發明涉及人工智能,尤其是指一種作圖方法、裝置及作圖設備。
背景技術:
1、人工智能(artificial?intelligence,ai)生成內容是一種通過人工智能算法對數據或媒體進行生產、操控和修改的統稱。伴隨著大量應用的落地,ai生成圖片、文字、音頻甚至視頻等內容也漸漸進入了人們的日常。利用人工智能算法,通過關鍵詞精準生成所需要景物的圖片為目前人工智能生成式作圖的重要研究方向。
技術實現思路
1、本發明技術方案的目的是提供一種作圖方法、裝置及作圖設備,用于利用人工智能算法,通過關鍵詞精準生成所需要景物的圖片。
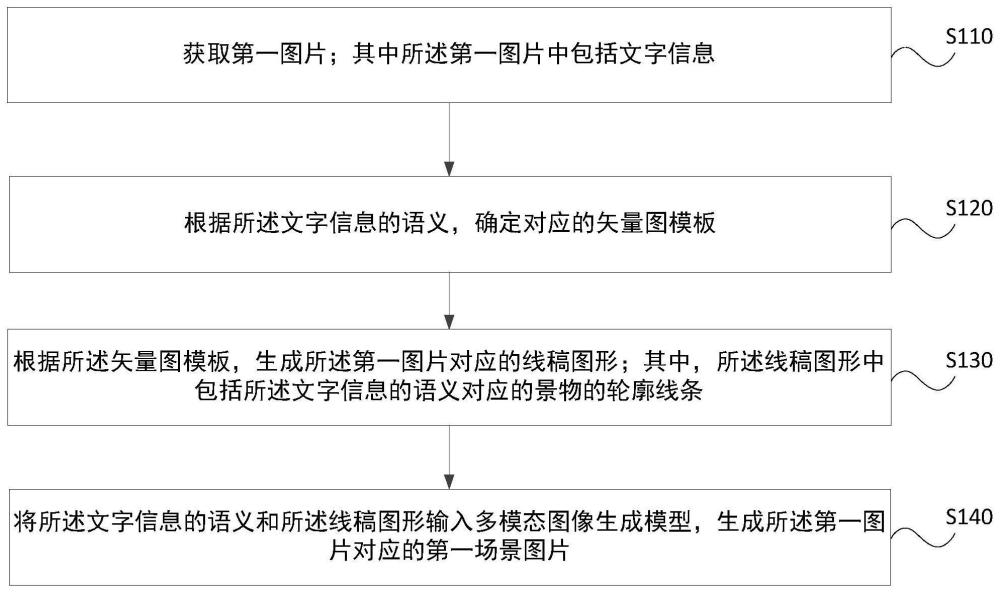
2、本發明其中一實施例提供一種作圖方法,其中,包括:
3、獲取第一圖片;其中所述第一圖片中包括文字信息;
4、根據所述文字信息的語義,確定對應的矢量圖模板;
5、根據所述矢量圖模板,生成所述第一圖片對應的線稿圖形;其中,所述線稿圖形中包括所述文字信息的語義對應的景物的輪廓線條;
6、將所述文字信息的語義和所述線稿圖形輸入多模態圖像生成模型,生成所述第一圖片對應的第一場景圖片。
7、可選地,所述的作圖方法,其中,所述方法還包括:
8、識別所述文字信息在所述第一圖片中的坐標位置;
9、其中,所述矢量圖模板包括多個線條數組;在確定對應的矢量圖模板之后,所述方法還包括:
10、根據所述坐標位置,確定所述多個線條數組對應的點陣坐標;所述坐標位置位于所述點陣坐標的覆蓋區域之內;
11、其中,根據所述矢量圖模板,生成所述第一圖片對應的線稿圖形,包括:
12、根據所述矢量圖模板中多個線條數組對應的點陣坐標,生成所述第一圖片對應的線稿圖形。
13、可選地,所述的作圖方法,其中,所述方法還包括:
14、根據所述文字信息的語義,在確定所述文字信息中包括文字類型為形容詞或動詞的第一目標文字的情況下,根據所述第一目標文字調整所述多個線條數組對應的點陣坐標。
15、可選地,所述的作圖方法,其中,所述方法還包括:
16、根據所述文字信息的語義,輸出所述文字信息對應的標簽選項;
17、獲取在所述標簽選項上選擇的所述文字信息對應的標簽屬性;
18、其中,根據所述文字信息的語義,確定對應的矢量圖模板,包括:
19、根據所述文字信息的語義和對應的所述標簽屬性,確定對應的矢量圖模板。
20、可選地,所述的作圖方法,其中,根據所述文字信息的語義,輸出所述文字信息對應的標簽選項,包括:
21、根據所述文字信息的語義,輸出所述文字信息中文字類型為名詞的第二目標文字對應的標簽選項。
22、可選地,所述的作圖方法,其中,所述方法還包括:
23、根據用戶的第一輸入操作,在屏幕上顯示所述線稿圖形;
24、獲取對所述線稿圖形的位置、大小和/或形狀進行調整的第一調整操作,并獲得調整后的所述線稿圖形;
25、將所述文字信息的語義和調整后的所述線稿圖形輸入所述多模態圖像生成模型,生成所述第一圖片對應的第二場景圖片。
26、可選地,所述的作圖方法,其中,所述方法還包括:
27、根據用戶的第二輸入操作,在屏幕上顯示所述第一圖片;
28、獲取對所述文字信息的位置、大小和/或形狀進行調整的第二調整操作,并獲得調整后的所述文字信息在所述第一圖片中的坐標位置;
29、根據調整后的所述坐標位置和對應的所述矢量圖模板,生成調整后的所述線稿圖形;
30、將所述文字信息和調整后的所述線稿圖形輸入所述多模態圖像生成模型,生成所述第一圖片對應的第三場景圖片。
31、可選地,所述的作圖方法,其中,所述方法還包括:
32、根據用戶的第三輸入操作,在屏幕上顯示所述文字信息對應的標簽選項;
33、獲取在所述標簽選項上的選擇操作,并獲得所述選擇操作所選擇的標簽屬性;
34、根據所選擇的標簽屬性和對應的所述矢量圖模板,生成調整后的所述線稿圖形;
35、將所述文字信息和調整后的所述線稿圖形輸入所述多模態圖像生成模型,生成所述第一圖片對應的第四場景圖片。
36、可選地,所述的作圖方法,其中,所述第一圖片中還包括構圖輔助線條;
37、其中,所述方法還包括:
38、根據所述構圖輔助線條,確定所述線稿圖形中不同景物的輪廓線條和/或不同景物的輪廓線條的間隔位置。
39、可選地,所述的作圖方法,其中,所述矢量圖模板包括所述文字信息的語義對應景物的邊框線稿模板和所述文字信息的語義對應景物的骨骼線稿模板。
40、本發明其中一實施例還提供一種作圖裝置,其中,包括:
41、第一獲取模塊,用于獲取第一圖片;其中所述第一圖片中包括文字信息;
42、確定模塊,用于根據所述文字信息的語義,確定對應的矢量圖模板;
43、第一生成模塊,用于根據所述矢量圖模板,生成所述第一圖片對應的線稿圖形;其中,所述線稿圖形中包括所述文字信息的語義對應的景物的輪廓線條;;
44、第二生成模塊,用于將所述文字信息的語義和所述線稿圖形輸入多模態圖像生成模型,生成所述第一圖片對應的第一場景圖片。
45、本發明其中一實施例還提供一種作圖設備,包括:存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的程序;其中,所述處理器用于讀取所述存儲器中的程序實現如上中任一項所述的作圖方法。
46、本發明具體實施例上述技術方案中的至少一個具有以下有益效果:
47、采用該實施例所述作圖方法,根據用戶制作的第一圖片中的文字信息(關鍵詞),進行語義識別,根據所識別的文字信息的語義,確定對應的矢量圖模型,并生成對應的線稿圖形,該作圖過程能夠利用人工智能算法實現由文字、線稿圖形至場景效果圖的分階段作圖,保證通過文字信息精準生成所需要景物的圖片。
技術特征:
1.一種作圖方法,其特征在于,包括:
2.根據權利要求1所述的作圖方法,其特征在于,所述方法還包括:
3.根據權利要求2所述的作圖方法,其特征在于,所述方法還包括:
4.根據權利要求1所述的作圖方法,其特征在于,所述方法還包括:
5.根據權利要求4所述的作圖方法,其特征在于,根據所述文字信息的語義,輸出所述文字信息對應的標簽選項,包括:
6.根據權利要求1所述的作圖方法,其特征在于,所述方法還包括:
7.根據權利要求1所述的作圖方法,其特征在于,所述方法還包括:
8.根據權利要求4所述的作圖方法,其特征在于,所述方法還包括:
9.根據權利要求1所述的作圖方法,其特征在于,所述第一圖片中還包括構圖輔助線條;
10.根據權利要求1所述的作圖方法,其特征在于,所述矢量圖模板包括所述文字信息的語義對應景物的邊框線稿模板和所述文字信息的語義對應景物的骨骼線稿模板。
11.一種作圖裝置,其特征在于,包括:
12.一種作圖設備,包括:存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的程序;其特征在于,所述處理器用于讀取所述存儲器中的程序實現如權利要求1至10中任一項所述的作圖方法。
技術總結
本發明提供一種作圖方法、裝置及作圖設備。該方法包括:獲取第一圖片;其中所述第一圖片中包括文字信息;根據所述文字信息的語義,確定對應的矢量圖模板;根據所述矢量圖模板,生成所述第一圖片對應的線稿圖形;其中,所述線稿圖形中包括所述文字信息的語義對應的景物的輪廓線條;將所述文字信息的語義和所述線稿圖形輸入多模態圖像生成模型,生成所述第一圖片對應的第一場景圖片。采用該方法,根據用戶制作的第一圖片中的文字信息,能夠利用人工智能算法實現由文字、線稿圖形至場景效果圖的分階段作圖,保證通過文字信息精準生成所需要景物的圖片。
技術研發人員:聶鼎
受保護的技術使用者:京東方科技集團股份有限公司
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!