基于大規模預訓練ViT模型的摳圖方法及裝置與流程
本技術涉及圖像處理,特別涉及一種基于大規模預訓練vit模型的摳圖方法、一種計算機可讀存儲介質、一種計算機設備以及一種基于大規模預訓練vit模型的摳圖裝置。
背景技術:
1、摳圖是指對圖像進行去背景操作,以準確提取靜止圖片或者視頻圖片序列中的前景目標;在對靜止圖片或者視頻圖片進行摳圖處理的過程中常面臨挑戰,尤其在電商圖像中處理孔洞、鏡面和小部件等復雜場景時難以實現精確識別和精細摳圖。
2、相關技術中,盡管已有部分摳圖模型的基礎架構采用了vit模型,但由于vit模型的預訓練數據量最多僅約1300萬數據(imagenet-22k數據集,主要用于分類任務),導致其在圖像特征提取和語義識別方面存在一定局限性,導致摳圖效果不理想。
3、此外,vit架構采用的是global?attention機制,專注于捕捉圖像的全局信息,但由于其只有單尺度特征信息,在學習局部幾何細節方面存在一定局限性;因此,在摳圖任務中,vit架構難以充分關注前景對象的局部邊緣細節,導致其在精細化邊緣摳圖效果上表現欠佳。
技術實現思路
1、本技術旨在至少在一定程度上解決上述技術中的技術問題之一。為此,本技術的一個目的在于提出一種基于大規模預訓練vit模型的摳圖方法,通過在vit架構中引入了基于大模型預訓練權重,并加入旁路網絡輔助主干網絡,從而有效提升了模型的語義識別能力和摳圖精度。
2、本技術的第二個目的在于提出一種計算機可讀存儲介質。
3、本技術的第三個目的在于提出一種計算機設備。
4、本技術的第四個目的在于提出一種基于大規模預訓練vit模型的摳圖裝置。
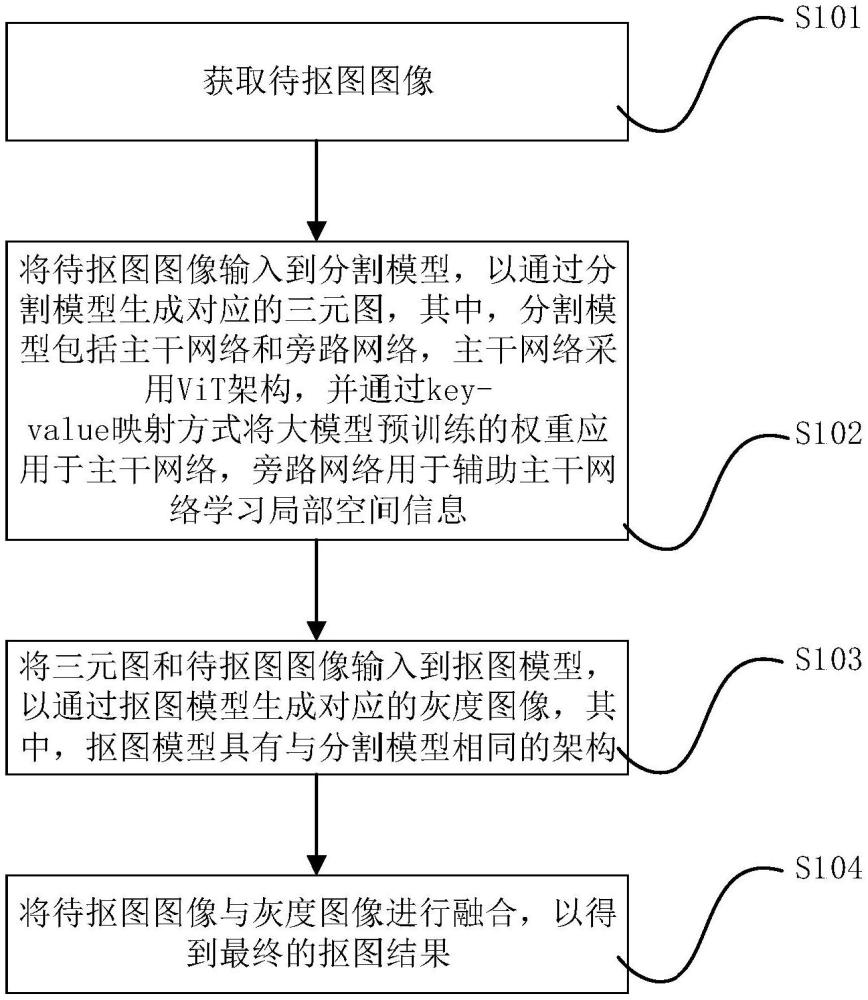
5、為達到上述目的,本技術第一方面實施例提出了一種基于大規模預訓練vit模型的摳圖方法,包括以下步驟:獲取待摳圖圖像;將所述待摳圖圖像輸入到分割模型,以通過所述分割模型生成對應的三元圖,其中,所述分割模型包括主干網絡和旁路網絡,所述主干網絡采用vit架構,并通過key-value映射方式將大模型預訓練的權重應用于所述主干網絡,所述旁路網絡用于輔助所述主干網絡學習局部空間信息;將所述三元圖和所述待摳圖圖像輸入到摳圖模型,以通過所述摳圖模型生成對應的灰度圖像,其中,所述摳圖模型具有與所述分割模型相同的架構;將所述待摳圖圖像與所述灰度圖像進行融合,以得到最終的摳圖結果。
6、根據本技術實施例的基于大規模預訓練vit模型的摳圖方法,通過采用帶有大規模預訓練權重的vit架構和旁路網絡,顯著提升了摳圖模型的語義識別能力和精度;特別是在處理電商圖中復雜細節(如孔洞、鏡面、小部件)時表現尤為突出。
7、另外,根據本技術上述實施例提出的基于大規模預訓練vit模型的摳圖方法還可以具有如下附加的技術特征:
8、可選地,所述主干網絡包括嵌入模塊和多個編碼模塊;其中,所述待摳圖圖像通過所述嵌入模塊編碼為第一嵌入向量;以及在所述第一嵌入向量上加入位置信息后輸入所述編碼模塊進行處理。
9、可選地,所述大模型為交互式分割模型,包括提示編碼器、圖像編碼器和輕量級掩碼解碼器;其中,所述提示編碼器用于將輸入的交互式提示轉換為第二嵌入向量;所述圖像編碼器采用vit架構,以捕捉圖像的全局和局部特征;所述輕量級掩碼解碼器結合所述提示編碼器和所述圖像編碼器的輸出,以生成分割掩碼,并作為所述大模型預訓練的權重。
10、可選地,所述旁路網絡包括空間先驗模塊、幾何先驗特征注入模塊和多尺度特征提取模塊;其中,通過所述空間先驗模塊提取所述待摳圖圖像的幾何先驗特征;所述幾何先驗特征注入模塊將加入位置信息后的第一嵌入向量作為query,將所述幾何先驗特征作為key和value,進行cross?attention操作,以得到新的特征表示,以便將所述新的特征表示作為所述主干網絡中下一個編碼模塊的輸入;所述多尺度特征提取模塊將所述幾何先驗特征作為query,將所述編碼模塊的輸出作為key和value,進行cross?attention操作后再經過ffn層,以得到多尺度特征。
11、為達到上述目的,本技術第二方面實施例提出了一種計算機可讀存儲介質,其上存儲有基于大規模預訓練vit模型的摳圖程序,該基于大規模預訓練vit模型的摳圖程序被處理器執行時實現如上述的基于大規模預訓練vit模型的摳圖方法。
12、為達到上述目的,本技術第三方面實施例提出了一種計算機設備,包括存儲器、處理器及存儲在存儲器上并可在處理器上運行的計算機程序,其特征在于,所述處理器執行所述程序時,實現如上述的基于大規模預訓練vit模型的摳圖方法。
13、為達到上述目的,本技術第四方面實施例提出了一種基于大規模預訓練vit模型的摳圖裝置,包括:獲取模塊,用于獲取獲取待摳圖圖像;分割模塊,用于將所述待摳圖圖像輸入到分割模型,以通過所述分割模型生成對應的三元圖,其中,所述分割模型包括主干網絡和旁路網絡,所述主干網絡采用vit架構,并通過key-value映射方式將大模型預訓練的權重應用于所述主干網絡,所述旁路網絡用于輔助所述主干網絡學習局部空間信息;摳圖模塊,用于將所述三元圖和所述待摳圖圖像輸入到摳圖模型,以通過所述摳圖模型生成對應的灰度圖像,其中,所述摳圖模型具有與所述分割模型相同的架構;目標生成模塊,用于將所述待摳圖圖像與所述灰度圖像進行融合,以得到最終的摳圖結果。
14、根據本技術實施例的基于大規模預訓練vit模型的摳圖裝置,通過采用帶有大規模預訓練權重的vit架構和旁路網絡,顯著提升了摳圖模型的語義識別能力和精度;特別是在處理電商圖中復雜細節(如孔洞、鏡面、小部件)時表現尤為突出。
15、另外,根據本技術上述實施例提出的基于大規模預訓練vit模型的摳圖裝置還可以具有如下附加的技術特征:
16、可選地,所述主干網絡包括嵌入模塊和多個編碼模塊;其中,所述待摳圖圖像通過所述嵌入模塊編碼為第一嵌入向量;以及在所述第一嵌入向量上加入位置信息后輸入所述編碼模塊進行處理。
17、可選地,所述大模型為交互式分割模型,包括提示編碼器、圖像編碼器和輕量級掩碼解碼器;其中,所述提示編碼器用于將輸入的交互式提示轉換為第二嵌入向量;所述圖像編碼器采用vit架構,以捕捉圖像的全局和局部特征;所述輕量級掩碼解碼器結合所述提示編碼器和所述圖像編碼器的輸出,以生成分割掩碼,并作為所述大模型預訓練的權重。
18、可選地,所述旁路網絡包括空間先驗模塊、幾何先驗特征注入模塊和多尺度特征提取模塊;其中,通過所述空間先驗模塊提取所述待摳圖圖像的幾何先驗特征;所述幾何先驗特征注入模塊將加入位置信息后的第一嵌入向量作為query,將所述幾何先驗特征作為key和value,進行cross?attention操作,以得到新的特征表示,以便將所述新的特征表示作為所述主干網絡中下一個編碼模塊的輸入;所述多尺度特征提取模塊將所述幾何先驗特征作為query,將所述編碼模塊的輸出作為key和value,進行cross?attention操作后再經過ffn層,以得到多尺度特征。
- 還沒有人留言評論。精彩留言會獲得點贊!