一種基于Transformer和多尺度特征融合的圖像去模糊系統及方法與流程
本發明涉及圖像處理,具體的說是一種基于transformer和多尺度特征融合的圖像去模糊系統及方法。
背景技術:
1、圖像去模糊技術,作為圖像處理領域的一個重要分支,旨在解決由于相機抖動、物體移動或其他因素導致的圖像模糊問題,以恢復出更加清晰、細節豐富的圖像。這一技術在攝影、醫學成像、衛星圖像解析等多個領域都有著廣泛的應用前景。
2、傳統的圖像去模糊方法主要依賴于數學模型,如逆濾波、維納濾波等。這些方法通過構建模糊過程的數學模型,嘗試逆轉模糊效應以恢復原始圖像。然而,當面對復雜的模糊模式,尤其是那些由非均勻運動或非線性因素引起的模糊時,傳統方法往往難以獲得令人滿意的去模糊效果。這是因為復雜模糊模式可能涉及多種不同類型的模糊核,且模糊核的具體參數(如大小、形狀、方向等)可能未知或難以準確估計。
3、近年來,隨著深度學習技術的飛速發展,基于卷積神經網絡(cnn)的圖像去模糊方法逐漸成為主流。與傳統方法相比,cnn具有強大的特征提取和表示能力,能夠自動學習模糊圖像與清晰圖像之間的映射關系。更重要的是,基于cnn的方法能夠在沒有明確模糊核的情況下,直接從模糊圖像中恢復出清晰圖像。這一特性使得cnn在處理復雜模糊模式時表現出色,極大地提高了圖像去模糊的準確性和魯棒性。
4、然而,盡管基于cnn的圖像去模糊方法取得了顯著進展,但它們在捕捉圖像全局信息以及長距離依賴關系方面仍存在局限性。具體來說,cnn在處理局部特征時表現出色,但在整合全局上下文信息、理解遠距離像素之間的依賴關系時可能遇到困難。這限制了其在某些需要精細全局理解的場景下的表現,如場景深度估計、語義分割等任務。
技術實現思路
1、本發明針對現有圖像去模糊技術在全局特征學習和感受野受限方面的不足,提供一種基于transformer和多尺度特征融合的圖像去模糊系統及方法,從而應對現有技術在全局特征學習、遠程像素捕獲、計算效率、輸入內容自適應性以及圖像細節恢復等方面的挑戰。
2、第一方面,本發明提供一種基于transformer和多尺度特征融合的圖像去模糊系統,解決上述技術問題采用的技術方案如下:
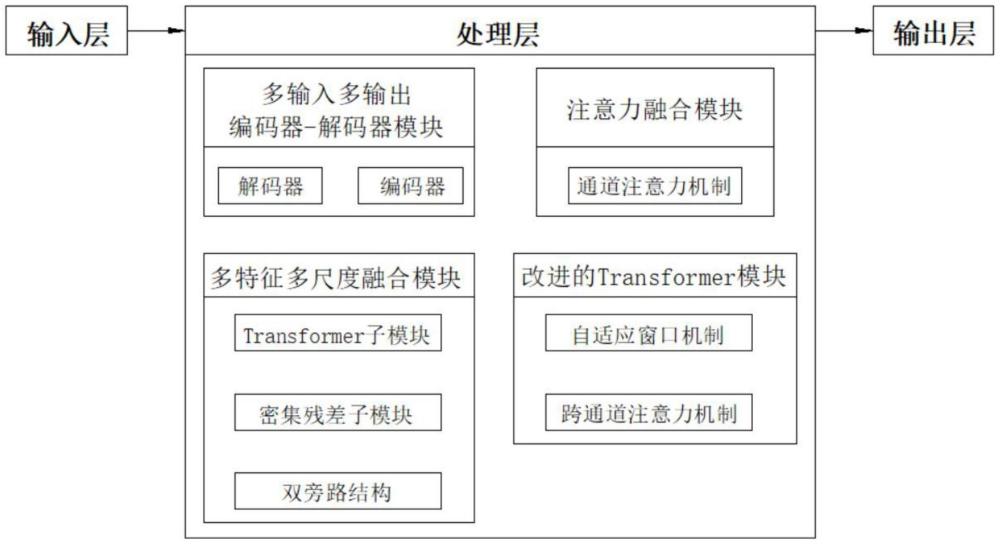
3、一種基于transformer和多尺度特征融合的圖像去模糊系統,其包括輸入層、處理層和輸出層,輸入層負責接收模糊圖像作為輸入,處理層包含多個模塊,多個模塊協同工作以提取特征并逐步恢復清晰圖像,輸出層輸出去模糊后的清晰圖像;其中,處理層進一步包括:
4、多輸入多輸出編碼器-解碼器模塊,用于通過編碼器從不同尺度的模糊圖像里提取特征,通過解碼器基于提取到的特征逐步還原出清晰圖像;
5、多特征多尺度融合模塊,用于整合局部和全局特征信息,增強系統對全局特征的學習能力;
6、改進的transformer模塊,通過引入自適應窗口機制和跨通道注意力機制,使系統能夠更好地適應不同類型的模糊圖像,提高特征提取和圖像恢復的效果;
7、注意力融合模塊,通過引入通道注意力機制,來動態學習和整合有用的特征信息。
8、可選的,所涉及多輸入多輸出編碼器-解碼器模塊的編碼器具體實現如下步驟:
9、將輸入的模糊圖像分別下采樣到不同的尺度;
10、對于每個尺度的圖像,首先進行3×3卷積操作,以初步提取圖像的局部特征并調整通道信息,然后將卷積結果送入編碼器;
11、編碼器從所接收不同尺度的圖像中分別提取多尺度特征,隨后調用注意力融合模塊,注意力融合模塊為每個尺度的特征通道計算重要性權重,從而動態地把全局和局部信息進行加權融合。
12、進一步可選的,所涉及多特征多尺度融合模塊具體包括:
13、transformer子模塊,用于基于其自注意力機制,計算圖像中不同位置像素之間的長距離依賴性,以此來提取圖像的全局特征,捕捉到圖像整體的語義信息;
14、密集殘差子模塊,用于使用不同大小的卷積核提取不同尺度圖像的局部特征信息;
15、雙旁路結構,用于結合局部特征信息和全局特征信息,確保信息的充分融合。
16、進一步可選的,所涉及多特征多尺度融合模塊的具體實現過程如下:
17、以編碼器階段中注意力融合模塊得到的融合特征作為輸入;
18、使用transformer子模塊計算圖像中不同位置像素之間的長距離依賴性,以提取圖像的全局特征,捕捉到圖像整體的語義信息;同時,使用3×3卷積核的密集殘差子模塊對同一輸入特征進行處理,提取局部特征;
19、將transformer子模塊提取的全局特征和密集殘差子模塊提取的局部特征進行逐元素相加操作,把相加后的特征送入包含不同大小的卷積核的密集殘差子模塊中,進一步增強網絡的感受野,使融合后的特征得到進一步強化和優化;
20、使用1×1卷積將感受野增強處理后的特征圖的通道數降低到初始通道數,以保持特征圖在通道維度上的一致性;這一過程中,加入殘差連接,即把當前經過處理的特征與之前指定階段的特征相加,使得系統的神經網絡在訓練及特征處理過程中能更穩定有效地學習和傳遞信息。
21、進一步可選的,所涉及改進的transformer模塊的具體實現過程如下:
22、以經過多特征多尺度融合模塊處理后的特征圖作為輸入,對其進行層歸一化操作,隨后通過卷積投影操作將特征圖分別投影生成queries(q)、keys(k)和values(v)這三個不同的表示形式,以分別從不同角度對特征進行空間上的映射,為后續的注意力計算做準備;
23、將queries(q)和keys(k)進行重塑后相乘,生成轉置注意力圖,再通過softmax函數進行歸一化,然后與values(v)相乘得到注意力結果,以確定不同位置特征之間的相關性權重,突出重要的特征信息;
24、使用由層歸一化、兩個1×1卷積層和gelu激活函數組成的前饋網絡,對得到的注意力結果進行非線性映射。
25、進一步可選的,所涉及注意力融合模塊的具體實現過程如下:
26、將當前階段的輸入圖像和經過改進的transformer模塊處理后的特征進行拼接操作,在通道維度上將二者合并在一起,形成更豐富的特征表示,為后續動態學習和整合有用特征做準備;
27、計算每個通道的重要性權重,根據計算出的權重對拼接后的特征進行動態的權重分配,來突出重要的特征信息;
28、使用1×1卷積對經過權重分配后的特征進行細化操作,確保特征圖在結構和維度上的一致性,得到經過優化后的特征信息。
29、進一步可選的,所涉及多輸入多輸出編碼器-解碼器模塊的解碼器具體實現如下步驟:
30、以經過注意力融合模塊優化后的特征圖為輸入,使用轉置卷積操作進行上采樣,逐步將特征圖的大小恢復到接近原始圖像的分辨率大小;
31、當通過轉置卷積將特征圖上采樣到接近原始圖像分辨率的最大尺度時,使用多特征多尺度融合模塊對其進行處理,進一步學習和整合該尺度下的局部和全局特征,進一步完善圖像的細節;
32、采用殘差學習方案,即預測殘差圖像,并將其添加到輸入模糊圖像中,最終得到去模糊后的清晰圖像,并通過輸出層輸出該清晰圖像。
33、第二方面,本發明提供一種基于transformer和多尺度特征融合的圖像去模糊方法,解決上述技術問題采用的技術方案如下:
34、一種基于transformer和多尺度特征融合的圖像去模糊方法,基于第一方面所述的系統,其包括如下實現步驟:
35、s1、通過輸入層接收模糊圖像;
36、s2、通過多輸入多輸出編碼器-解碼器模塊將接收的模糊圖像分別下采樣到不同的尺度,對于每個尺度的圖像,首先進行3×3卷積操作,以初步提取圖像的局部特征并調整通道信息,然后將卷積結果送入編碼器;編碼器從所接收不同尺度的圖像中分別提取多尺度特征,隨后調用注意力融合模塊,注意力融合模塊為每個尺度的特征通道計算重要性權重,從而動態地把全局和局部信息進行加權融合;
37、s3、多特征多尺度融合模塊包括transformer子模塊、密集殘差子模塊和雙旁路結構,多特征多尺度融合模塊以編碼器階段中注意力融合模塊得到的融合特征作為輸入,使用transformer子模塊計算圖像中不同位置像素之間的長距離依賴性,以提取圖像的全局特征,捕捉到圖像整體的語義信息,同時,使用3×3卷積核的密集殘差子模塊對同一輸入特征進行處理,提取局部特征;將transformer子模塊提取的全局特征和密集殘差子模塊提取的局部特征進行逐元素相加操作,把相加后的特征送入包含不同大小的卷積核的密集殘差子模塊中,進一步增強網絡的感受野,使融合后的特征得到進一步強化和優化;使用1×1卷積將感受野增強處理后的特征圖的通道數降低到初始通道數,以保持特征圖在通道維度上的一致性;這一過程中,加入殘差連接,即把當前經過處理的特征與之前指定階段的特征相加,使得網絡在訓練及特征處理過程中能更穩定有效地學習和傳遞信息;
38、s4、改進的transformer模塊的以經過多特征多尺度融合模塊處理后的特征圖作為輸入,首先對其進行層歸一化操作;隨后通過卷積投影操作將特征圖分別投影生成queries(q)、keys(k)和values(v)這三個不同的表示形式,以分別從不同角度對特征進行空間上的映射,為后續的注意力計算做準備;再后將queries(q)和keys(k)進行重塑后相乘,生成轉置注意力圖,再通過softmax函數進行歸一化,然后與values(v)相乘得到注意力結果,以確定不同位置特征之間的相關性權重,突出重要的特征信息;最后使用由層歸一化、兩個1×1卷積層和gelu激活函數組成的前饋網絡,對得到的注意力結果進行非線性映射;
39、s5、使用注意力融合模塊將當前階段的輸入圖像和經過改進的transformer模塊處理后的特征進行拼接操作,在通道維度上將二者合并在一起,形成更豐富的特征表示,為后續動態學習和整合有用特征做準備;計算每個通道的重要性權重,根據計算出的權重對拼接后的特征進行動態的權重分配,來突出重要的特征信息;使用1×1卷積對經過權重分配后的特征進行細化操作,確保特征圖在結構和維度上的一致性,得到經過優化后的特征信息;
40、s6、多輸入多輸出編碼器-解碼器模塊的解碼器以經過注意力融合模塊優化后的特征圖為輸入,使用轉置卷積操作進行上采樣,逐步將特征圖的大小恢復到接近原始圖像的分辨率大小;當通過轉置卷積將特征圖上采樣到接近原始圖像分辨率的最大尺度時,使用多特征多尺度融合模塊對其進行處理,進一步學習和整合該尺度下的局部和全局特征,進一步完善圖像的細節;采用殘差學習方案,即預測殘差圖像,并將其添加到輸入模糊圖像中,最終得到去模糊后的清晰圖像,并通過輸出層輸出該清晰圖像。
41、可選的,所涉及transformer子模塊基于其自注意力機制,計算圖像中不同位置像素之間的長距離依賴性,以此來提取圖像的全局特征,捕捉到圖像整體的語義信息;密集殘差子模塊使用不同大小的卷積核提取不同尺度圖像的局部特征信息;雙旁路結構結合局部特征信息和全局特征信息,確保信息的充分融合。
42、本發明的一種基于transformer和多尺度特征融合的圖像去模糊系統及方法,與現有技術相比具有的有益效果是:
43、1、本發明不僅能更有效地恢復圖像細節特征,還可以顯著提升后續計算機視覺任務的魯棒性,適用于多種圖像去模糊應用場景,具有廣泛的應用前景;
44、2、本發明通過引入transformer架構,能夠有效地學習圖像中的全局特征信息,提高系統對長距離依賴關系的處理能力,從而在復雜模糊情況下表現更佳;多特征多尺度融合模塊通過雙旁路結構將局部特征信息和全局特征信息有效結合,可以顯著增強系統對遠程像素的捕獲能力,提升圖像細節的恢復質量;通過簡化transformer模塊并引入自適應窗口機制,惡意在保證性能的同時顯著降低計算復雜度,提高系統的運行效率;通過多尺度特征融合和改進的transformer模塊,能夠更有效地恢復圖像中的細節特征,顯著提升了圖像的整體清晰度和視覺質量。
- 還沒有人留言評論。精彩留言會獲得點贊!