一種基于反事實數據增強的序列推薦方法
本發明屬于互聯網偏好預測領域,涉及一種基于反事實數據增強的序列推薦方法。
背景技術:
1、序列推薦是一種決策支持系統,其目的是根據用戶的歷史行為來預測用戶的偏好。然而,由于真實世界數據的稀疏性,這種推薦策略在實踐中可能執行得不好。為此,本問提出了一種新的反事實數據增強框架,以減輕不完美訓練數據的影響,并為序列推薦模型提供支持。
2、在過去的幾年中,許多序列推薦模型被提出,并在各種應用場景下取得了不錯的性能。這些模型利用復雜的機制,從用戶的歷史行為中預測用戶的偏好。但序列推薦模型本質上仍然是基于兩個或多個項目在序列中的出現來捕獲它們的聯合分布,這使得它們與非序列推薦模型相比需要更多的高質量序列數據來用于訓練。但這一條件與真實世界數據的稀疏性相沖突,在實踐中觀察到的序列僅能覆蓋用戶內容交互的極少數。
技術實現思路
1、有鑒于此,本發明的目的在于提供一種基于反事實數據增強的序列推薦方法,該方法包括:獲取視頻數據和用戶數據;將原始訓練數據輸入到用戶偏好預測模型中訓練得到預訓練模型,將視頻數據和用戶數據輸入數據增強框架中生成反事實序列,增強后的訓練數據重新訓練推薦模型得到用完整的推薦模型,利用該模型預測用于興趣偏好。
2、為達到上述目的,本發明提供如下技術方案:
3、一種基于反事實數據增強的序列推薦方法,該方法包括以下步驟:
4、s1:獲取用戶在網站歷史行為數據歷史行為數據包括用戶信息和內容信息;
5、s2:根據歷史行為數據,建立用戶內容特征向量;
6、s3:將特征向量輸入到序列推薦模型中進行訓練;
7、s4:計算模型交叉熵損失并根據模型交叉熵損失調整模型參數,得到預訓練的推薦模型;
8、s5:將原始數據輸入到采樣器模型中生成反事實序列;
9、s6:利用反事實序列重新訓練推薦模型;
10、s7:將待預測用戶數據輸入推薦模型中,計算用戶的興趣偏好。
11、進一步,所述s1中,歷史行為數據來源于pc端、wap端、app端和線下數據;用戶信息包括用戶的標識id、用戶的性別、年齡和訪問偏好;內容信息包括該項目的標識編碼、項目類別和作者。
12、進一步,所述s2中,建立用戶內容概率預測特征向量具體包括:
13、清除特征中的缺失值,將非數值特征轉化為數值特征,采用嵌入層對內容數據和用戶數據進行處理;嵌入層為深度學習中常用的神經網絡層,主要作用是將一些低維的或者高維的特征轉化成同一維度,方便后續的向量維度統一;對不同種類的特征進行劃分,將特征進行編碼向量化,得到用戶嵌入和視頻嵌入,表示為:
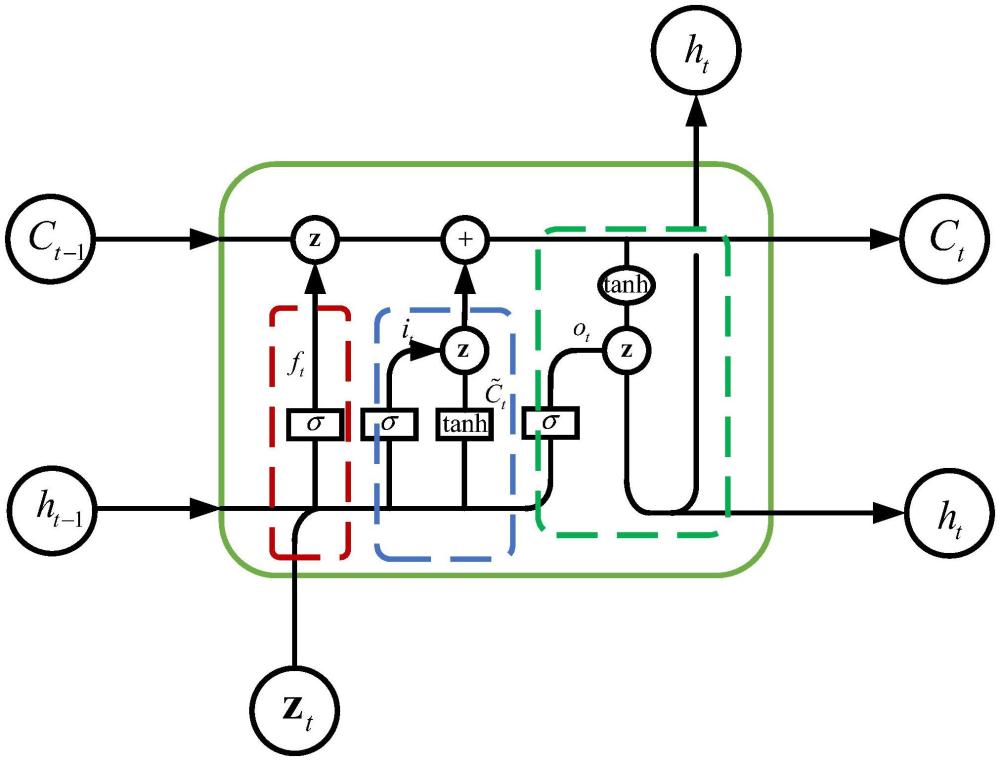
14、um=[α1,α2,...,αi,...,αm]
15、en=[β1,β2,...,βj,...,βn]
16、其中,m和n表示所有用戶特征和內容特征的數量;對于類別特征而言,αi為獨熱向量,對于離散特征而言,αi是一個標量值;當內容的第j個特征為稀疏特征時,βj獨熱向量,為非類別特征時βj是一個標量值;um為第m個用戶的嵌入表示,en為第n個內容的嵌入表示;
17、則最終的輸入序列特征向量為:
18、zi=[α1,α2,...,αi,...,αm,β1,β2,...,βj,...,βn]。
19、進一步,所述s3中,將特征向量輸入到推薦模型中進行訓練,具體表示為采用lstm神經網絡對用戶特征向量和內容特征向量進行學習,以下是從輸入到輸出的流程:
20、1.遺忘門
21、ft=σ(wf·[ht-1,zt]+bf)
22、遺忘門的作用是決定前一時刻的記憶單元ct-1中哪些信息將被遺忘;通過ft的輸出進行控制,值在0到1之間;ht-1是前一個時間步的隱藏狀態向量,zt是當前時間步的輸入數據
23、2.輸入門
24、it=σ(wi·[ht-1,zt]+bi)
25、
26、輸入門決定哪些新的信息被寫入到新的記憶單元中;it是輸入門的激活值,而是候選新的狀態;
27、3.更新記憶單元
28、
29、通過遺忘門和輸入門的控制,更新記憶單元ct;
30、4.輸出門
31、ot=σ(wo·[ht-1,zt]+bo)
32、ht=ot*tanh(ct)
33、輸出門決定當前時刻的隱藏狀態ht,結合當前記憶單元和輸出門的控制信號。
34、進一步,所述s4中,推薦模型中神經網絡參數可通過最小化交叉熵損失進行優化;交叉熵損失的計算公式為:
35、
36、其中,loss表示交叉熵損失,n表示訓練樣本數,表示第j個樣本的預測點擊概率,yj表示第j個樣本的的用戶實際點擊標簽。
37、進一步,所述s5中,序列推薦旨在建模利用交互對未來交互的影響,從而預測用戶的未來偏好,設有一個用戶集合u和一個內容集合i;將用戶-內容交互集合記作t,t組織為其中每個ui∈u,在t的第i個樣本中,與用戶ui交互的物品在歷史中表示為序列而是下一個物品;給定{u,i,t},;為實現此目標,構建如下優化問題:
38、
39、其中,模型a輸出在給定歷史信息ti的條件下與交互的概率,是負樣本集合,是從us未交互過的物品中隨機選擇的;若則標簽yi=1否則yi=0;
40、為解決訓練數據的稀疏性問題,引入采樣器模型,記為s,通過生成反事實序列來解決訓練數據的稀疏性問題;在新的框架中,s和a都是基于原始數據集進行預訓練的;然后,利用s產生的反事實序列來重新優化a,最后利用a來提供推薦列表;
41、最直觀的啟發式采樣方式,就是將序列中的某個內容td替換為其他隨機的內容項ta,然后將新序列{t1,…,td-1,ta,td+1,…tl}輸入到模型s中得到最終可能感興趣的內容最后作為生成的反事實數據;在生成的序列中引入太多的隨機性,導致模型性能的下降;
42、
43、在分類問題中,輸入特征空間根據不同的輸出標簽被分成許多子控件;不同輸入子控件之間的邊界被稱為決策邊界;位于決策邊界附近的樣本被認為是對整體決策更具辨別能力的樣本;采樣器的設計給予合一原則,生成的反事實序列最低限度地改變用戶的歷史項目,使目前的互動項目改變;設et∈rd是內容項t的嵌入,基于嵌入空間來度量用戶行為的變化;對于給定的真實的序列({u,t1,t2,…,tl},tl+1)∈t和索引d,優化以下目標:
44、
45、其中和是改變的項和原始項的嵌入;c表示要替換的項的集合,在上式中,目標旨在最小化改變過去的行為,以改變當前項;最終生成的反事實序列是通過這種“最小精確”優化,在生成的反事實序列中ta的一些小變化將使距離不足以改變tl+1,這意味著反事實序列接近決策邊界。
46、進一步,所述s6中,利用s5中生成的反事實序列重新輸入到預訓練好的lstm網絡中進行訓練。
47、進一步,所述s7中,構建需要預測用戶的特征向量以及輸入特征序列,并投入到序列推薦模型中進行訓練,即可得到最終預測結果。
48、本發明的有益效果在于:本發明可準確有效的進行用戶偏好預測,提高了用戶偏好預測的準確性。
49、本發明的其他優點、目標和特征在某種程度上將在隨后的說明書中進行闡述,并且在某種程度上,基于對下文的考察研究對本領域技術人員而言將是顯而易見的,或者可以從本發明的實踐中得到教導。本發明的目標和其他優點可以通過下面的說明書來實現和獲得。
- 還沒有人留言評論。精彩留言會獲得點贊!