一種基于模式識別的短期負荷預測方法與流程
本發明屬于電力負荷預測,具體涉及一種基于模式識別的短期負荷預測方法。
背景技術:
1、隨著電網整體設置日益復雜化,如何深化電力配網的運行是電力配網發展的重點與關鍵。電力負荷是電網規劃的重要參考,準確預測電力負荷對提高電網運行的安全性和經濟性有重要意義,優化配電力負荷預測計算可以幫助電力供應商更好地規劃能源供應,穩定電網運行,減少對外購電的需求,并降低能源浪費率;同時電力負荷預測技術可以應用于智能電網、儲能系統以及可再生能源發電設備等領域,幫助用戶預測未來的用電量情況,調整用電策略和計劃,提高用電效率。
2、目前負荷預測主要采用數據驅動的預測技術,直接通過歷史數據、氣象信息、經濟狀況等多種因素進行綜合分析,具體方法包括傳統的一元線性回歸、灰色預測分析、二次多項式回歸等,以及現代的人工智能預測方法,如bp神經網絡模型、支持向量機模型等。然而,將多維的因素(氣象、歷史數據、社會事件)直接作為預測模型的輸入,無法區分不同因素對預測結果的不同影響,因此,亟需開發一種通用的短期負荷預測方法,以有效應對不同類型事件及氣象等偶然性因素。
技術實現思路
1、發明目的:為解決上述技術問題,本發明提供了一種基于模式識別的短期負荷預測方法,通過對歷史數據的學習與偶然性事件的分析,對短期(未來1天)負荷預測結果進行更加精準的自動校正。
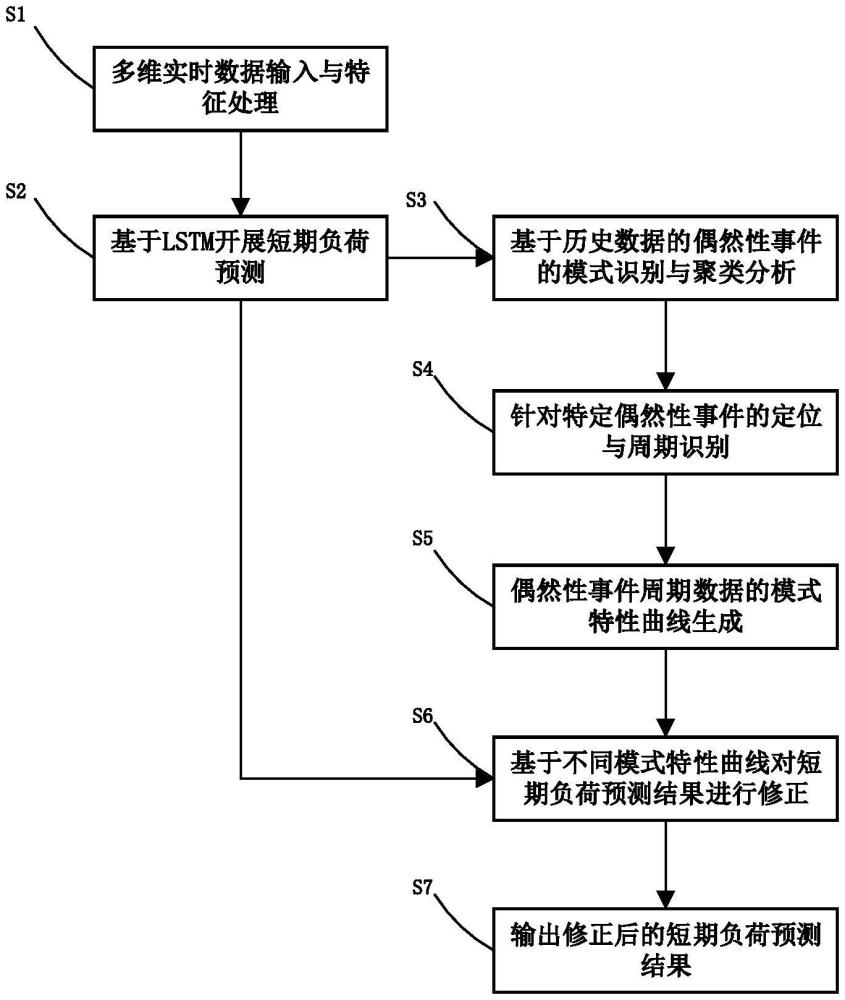
2、技術方案:本發明提供的一種基于模式識別的短期負荷預測方法,包括以下步驟:
3、(一種基于模式識別的短期負荷預測方法,其特征在于,包括以下步驟:
4、(1)多維實時數據輸入與特征處理;
5、(2)基于lstm開展短期負荷預測;
6、(3)基于歷史數據的偶然性事件的模式識別與聚類分析;
7、(4)針對特定偶然事件的周期識別與定位;
8、(5)偶然性事件的周期數據的模式特性曲線生成:將每種類型的事件,根據周期進行特征生成,特征提取網絡為步驟(3)中的特征提取網絡,利用多維度的特征值作為偶然性事件的模式特性曲線;
9、(6)基于不同模式特性曲線對短期負荷預測結果進行修正;
10、(7)輸出修正后的短期負荷預測結果:按負荷預測時間要求,輸出對應長度的預測結果。
11、進一步的,步驟(1)中由于負荷預測的輸入x多有多樣性和時序性,首先將各維度輸入數據進行均值歸一化。每次數據的持續時間t為10天,其時間間隔為15min,故各維度數據長度為960。均值歸一化公式如下:
12、
13、式中:mean(x)、max(x)、min(x)分別為樣本數據的平均值、最大值和最小值。
14、進一步的,步驟(2)中所述基于lstm開展短期負荷預測的具體步驟為:
15、s21模型與網絡超參數配置:短期負荷預測模型以lstm為基礎,具有5層的lstm以及1層的dense層的,時間步長為10天960點,激活函數采用relu激活函數,采用l2正則化防止過擬合;
16、s22開展短期負荷預測模型訓練,batch?size采用4,不設置迭代次數,而是采用early?stopping技術防止過擬合,在驗證集性能開始下降時停止訓練;
17、s23利用均方根誤差(rmse)作為預測模型的損失函數。
18、利用均方根誤差(rmse)作為預測模型的損失函數。
19、
20、式中:y_predi為預測值,y_truei為真實值。
21、進一步的,步驟(3)中所述基于歷史數據的偶然性事件的模式識別與聚類分析具體過程如下:
22、s31人工標注偶然性事件類型、開始時間與結束時間;在短期負荷預測中,偶然性事件包括但不限于:極端天氣、節假日以及特殊社會活動。為精準識別各類型事件,首先人工進行數據的標注。為保證偶然性事件對負荷預測的影響盡可能完成被覆蓋,開始與結束時間可延長,其總時長固定為960個點,10天。
23、s32對不同類型偶然性事件進行模式識別與聚類分析。
24、根據人工標注結果,確定聚類的類別數,各個事件及其歷史同期事件可單獨作為一類;類型相似的事件,如節假日等事件,可歸并為一類。確定聚類數后,可采用動態自適應特征提取方法,將事件發生過程中的負荷結果作為模式識別的輸入,設置輸出特征維度在50-100之間,更進一步的,本方法選擇64作為輸出特征維度。
25、進一步的,采用cnn作為特征提取網絡,采用center?loss作為特征提取的損失函數。center?loss為每個類指定了一個類別中心。同一類的輸入對應的特征都盡量靠近自己的類別中心,不同類的類別中心盡量遠離。在訓練過程,增加樣本經過網絡映射后在特征空間與類中心的距離約束,從而兼顧了類內聚合與類間分離。
26、centor?loss的計算公示如下。其中xi為第i個事件的輸出特征,c_(y_i)為第yi個類別的類中心。
27、
28、進一步,不斷更新各個事件的特征的聚類中心更新方法如下。其中m標識事件類別數
29、
30、進一步的,為優化各類型事件的模式識別與聚類,采用centor?loss和softmaxloss聯合監督,并用一個超參數λ平衡兩個監督信號。其中softmax?loss目的是擴大類間的特征差異;center?loss目的是減少類內特征變化,優勢是不需要復雜的訓練樣本復合。聯合監督公式為:
31、
32、進一步的,不同的事件的持續時間不同,前序步驟僅做出了事件的識別,為更加精準定位事件的開始時間與持續時間,需對各類事件的周期進行統計分析。同一類型的事件具有相同的周期。步驟(4)中所述針對特定偶然事件的周期識別與定位具體步驟如下:
33、s41,首先設定可能的最長與最短事件時間,設定最小化的時間間隔,按時間間隔去循環取不同長度的周期去驗證是否同該事件進行匹配。
34、s42,事件周期的匹配方法:采用ncc評估兩個序列的相似度,對于未知啟動時間的事件,采用滑動窗口和ncc結合的方式進行相似度計算,基于ncc最大化的原則,得到每個類別事件的周期period。ncc的計算公式如下:
35、
36、式中:f和t為兩個樣本,n為窗口大小,σ為兩個樣本的標準差,μ為兩個樣本的均值。
37、s43,針對實際的負荷預測結果,識別其是否發生了事件,以及利用ncc計算事件開始時間,當正在發生的事件負荷與標注事件的相似度超過某一閾值時,可定位當前發生某事件的時間點,并在事件后續持續時間內開展負荷預測的修正。
38、進一步的,步驟(6)中所述對短期負荷預測結果進行修正流程如下:
39、s61,定位當前偶然性事件發生的開始時間t1。
40、s62,將事件后延960個時刻,識別當前事件屬于哪種類別的事件;
41、s63,將識別出的事件類別對應的特征進行插值化,與當前預測序列進行融合。將特征值控制在-1~1之間,其對當前值的融合方式為:
42、修正預測值=原始預測值+原始預測值*特征值
43、s6-4:對于日前負荷預測,按預測要求自動化的將事件特征值與實時預測結果進行融合。
44、有益效果:與現有技術相比,本發明的技術方案具有以下顯著優點:(1)本發明提出了一種基于模式識別的短期負荷預測修正方法,通過對歷史數據的學習與偶然性事件的分析,對短期(未來1天)負荷預測結果進行更加精準的自動校正。(2)短期負荷預測模型與偶然性事件模式識別、定位與周期識別相互依托,配套使用,可以更加高效精準的基于不同類型事件對預測結果進行修正。(3)本方法可識別偶然性事件的發生時間、周期、運行模式與特性曲線,可定性評估不同事件對負荷預測的影響,提高負荷預測的可解釋性。(4)本方法創新的提出一種偶然性事件特性曲線與預測曲線的融合(校正)方法。偶然性事件對負荷預測的影響,放在預測結果校正環節,而不作為負荷預測的輸入因素,不僅可以從降低輸入因素方面進而降低負荷預測模型的復雜度,最大限度保持負荷預測模型專注于負荷預測本身,而且可靈活控制修正策略,仍可以人工選擇是否使用校正方法。
- 還沒有人留言評論。精彩留言會獲得點贊!