一種基于數據庫語言的多平臺的數據一致性檢驗方法與流程
本發明涉及一種數據一致性檢驗方法,尤其涉及一種基于數據庫語言的多平臺的數據一致性檢驗方法。
背景技術:
1、隨著大數據應用的廣泛使用,相同數據在不同數據庫平臺文件格式、數據類型、存儲方式等方面存在差異。然而,在實際的應用場景中,數據遷移存在諸多問題,如:數據丟失,重復,一致性的問題,給業務應用帶來了諸多的困擾。例如:
2、1)數據跨平臺遷移后,因存儲格式不一致,導致數據文件md5值不一致,無法從文件判斷數據是否一致;
3、2)在數據跨平臺遷移后,僅僅數據量一致并不能打消業務對于數據一致性的擔憂。
技術實現思路
1、本發明所要解決的技術問題是提供一種基于數據庫語言的多平臺的數據一致性檢驗方法,能夠解決跨平臺數據遷移中數據一致性問題,保證數據遷移前后數據的一致性。
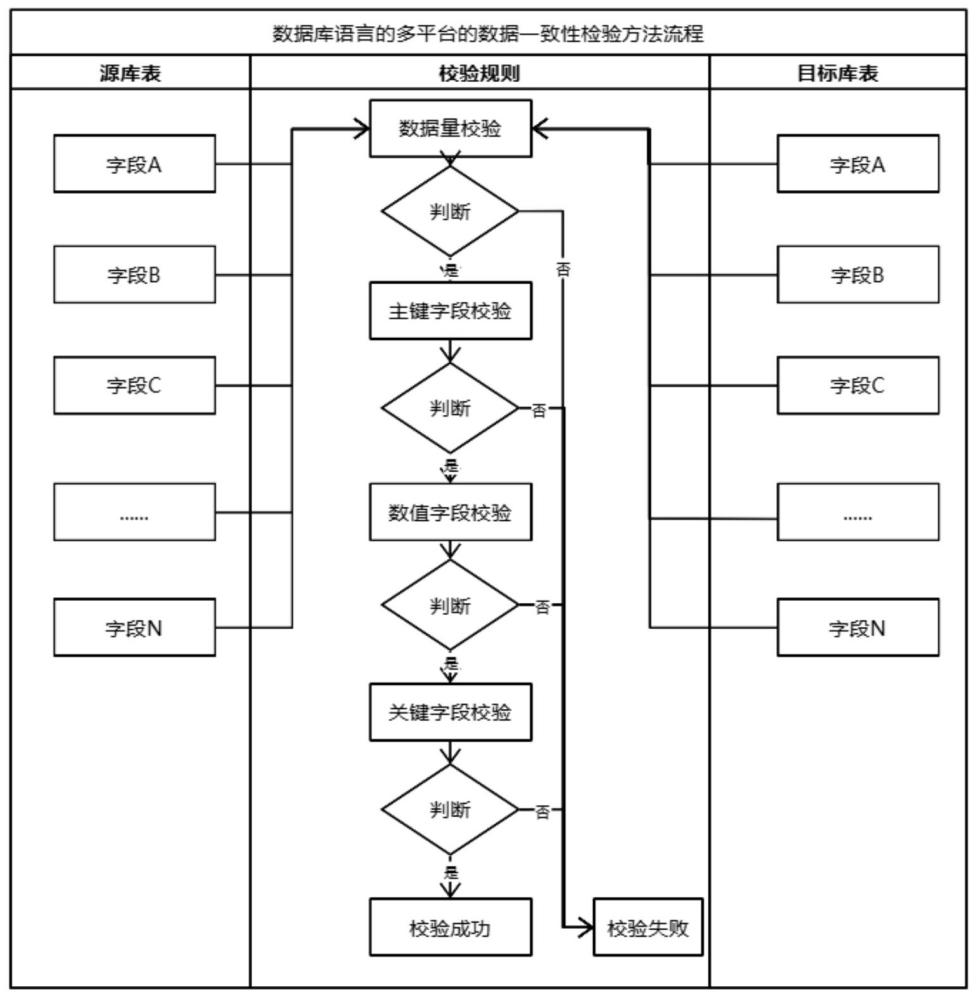
2、本發明為解決上述技術問題而采用的技術方案是提供一種基于數據庫語言的多平臺的數據一致性檢驗方法,包括如下步驟:s1)通過遷移工具將數據遷移至其他數據庫或者平臺;s2)先校驗數據遷移前后的數據量是否一致,數據量一致,則繼續進行驗證;s3)接著分別對源端數據庫表數據和目標端表數據主鍵字段進行校驗,主鍵字段相一致,則繼續進行驗證;s4)最后進行數值字段和關鍵字段校驗。
3、進一步地,所述步驟s1中的遷移工具為datax、kettle或liquibase。
4、進一步地,所述步驟s2通過數據庫管理工具navicat或dbeaver校驗數據遷移前后的數據量是否一致。
5、進一步地,所述步驟s3中的主鍵字段為數據類型時,則進行求和計算操作;如果主鍵字段為字符串類型,則計算字符串長度后再進行求和計算操作;如果源端和目標端計算結果一致,則認為主鍵字段數據相一致。
6、進一步地,所述步驟s4針對數值類型字段的數據,采用求和或求平均方式分別對源端數據和目標端數據進行數據一致性檢驗;針對字符串類型字段的數據,按照字符串長度進行求和計算,結果一致則確認數據相一致;針對時間類型字段的數據,按照年月日時分秒其中一個或者多個維度進行求和計算,結果一致則確認數據相一致。
7、進一步地,所述步驟s4將波爾類型字段數據當作字符串類型字段數據進行一致性校驗,將浮點類型字段數據當作數值類型字段數據進行一致性驗證。
8、進一步地,所述步驟s4中當表字段數目超出預設閾值時,每一種數據類型僅驗證一個字段。
9、本發明對比現有技術有如下的有益效果:本發明提供的基于數據庫語言的多平臺的數據一致性檢驗方法,通過對不同類型的業務字段進行聚合計算,對數據按規則進行數據分析,用數據庫語言對數據一致性進行校驗,保證數據遷移前后數據的一致性。
技術特征:
1.一種基于數據庫語言的多平臺的數據一致性檢驗方法,其特征在于,包括如下步驟:
2.如權利要求1所述的基于數據庫語言的多平臺的數據一致性檢驗方法,其特征在于,所述步驟s1中的遷移工具為datax、kettle或liquibase。
3.如權利要求1所述的基于數據庫語言的多平臺的數據一致性檢驗方法,其特征在于,所述步驟s2通過數據庫管理工具navicat或dbeaver校驗數據遷移前后的數據量是否一致。
4.如權利要求1所述的基于數據庫語言的多平臺的數據一致性檢驗方法,其特征在于,所述步驟s3中的主鍵字段為數據類型時,則進行求和計算操作;如果主鍵字段為字符串類型,則計算字符串長度后再進行求和計算操作;如果源端和目標端計算結果一致,則認為主鍵字段數據相一致。
5.如權利要求1所述的基于數據庫語言的多平臺的數據一致性檢驗方法,其特征在于,所述步驟s4針對數值類型字段的數據,采用求和或求平均方式分別對源端數據和目標端數據進行數據一致性檢驗;針對字符串類型字段的數據,按照字符串長度進行求和計算,結果一致則確認數據相一致;針對時間類型字段的數據,按照年月日時分秒其中一個或者多個維度進行求和計算,結果一致則確認數據相一致。
6.如權利要求5所述的基于數據庫語言的多平臺的數據一致性檢驗方法,其特征在于,所述步驟s4將波爾類型字段數據當作字符串類型字段數據進行一致性校驗,將浮點類型字段數據當作數值類型字段數據進行一致性驗證。
7.如權利要求5所述的基于數據庫語言的多平臺的數據一致性檢驗方法,其特征在于,所述步驟s4中當表字段數目超出預設閾值時,每一種數據類型僅驗證一個字段。
技術總結
本發明公開了一種基于數據庫語言的多平臺的數據一致性檢驗方法,包括如下步驟:S1)通過遷移工具將數據遷移至其他數據庫或者平臺;S2)先校驗數據遷移前后的數據量是否一致,數據量一致,則繼續進行驗證;S3)接著分別對源端數據庫表數據和目標端表數據主鍵字段進行校驗,主鍵字段相一致,則繼續進行驗證;S4)最后進行數值字段和關鍵字段校驗。本發明提供的基于數據庫語言的多平臺的數據一致性檢驗方法,通過對不同類型的業務字段進行聚合計算,對數據按規則進行數據分析,用數據庫語言對數據一致性進行校驗,保證數據遷移前后數據的一致性。
技術研發人員:劉迎風,張向飛,劉辰昀,潘佳,翁程凱,汪瑜,范倍銘
受保護的技術使用者:上海市大數據中心
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!