一種基于截斷拼接的多模態跨類別偽樣本構造方法
本發明屬于圖像識別,圖像處理(g06v,g06f),具體涉及一種基于截斷拼接的多模態跨類別偽樣本構造方法。
背景技術:
1、對于邊緣計算[1,2]和機器人技術[3]等多種日常應用,能夠像人類認知那樣進行自適應學習的人工智能模型至關重要,在理想狀況下,這些模型需要能夠在保留整體知識的同時,用最少的數據進行增量式更新,例如在面部識別系統[4]等場景中,哪怕只用一張圖像這樣極少的數據進行更新也是必不可少的。
2、然而,許多現有的與視覺相關的人工智能模型都受到一維文本和二維圖像形式數據的限制[5,6],無法對新概念進行系統全面的學習,出于對現實世界理解的需求,開發對能夠學習三維物體表征的人工智能模型至關重要[7]。人類可以憑借極少的數據自然地掌握三維概念,但訓練模型來模擬這一過程仍然是一個挑戰。為了彌合這一差距,針對三維點云對象的小樣本類增量學習被自然而然地提了出來,這種方法側重于訓練模型并以增量的方式從極少的三維點云數據樣本中學習新概念。小樣本中,單類別樣本數較少,例如少于指定數量閾值。
3、正如chowdhury等人在2022年的研究中所提出的那樣[8],3d點云小樣本類增量學習是將訓練和測試過程劃分為不同的階段。首先,在基礎階段為特定類別分配大量的訓練數據來對模型進行預訓練,這模擬了人類在嬰兒時期的學習過程;隨后,預訓練好的模型在若干個增量階段中為每個新類別接收極少的樣本(通常每個類別少于五個樣本),以逐步擴展其標簽空間,這模仿了人類在成長過程中從有限的例子中持續學習的過程。在每個增量階段,之前階段(包括基礎階段)的數據都無法獲取。這就要求模型在吸收新知識的同時保留之前所學的概念。
4、與二維圖像相比,三維點云數據的復雜性和稀疏性使得充分捕捉和利用局部特征之間的關系頗具挑戰性,具體來說,二維圖像中的局部特征,如特定的顏色、形狀或紋理,可以被有效地提取和利用,這對新類別的增量學習非常有利,然而,三維點云主要由稀疏的空間信息組成,缺乏二維圖像中豐富的紋理和顏色細節。這種紋理和顏色信息的缺失阻礙了通用局部特征的提取,而通用局部特征對于識別不同物體或場景之間的模式和關系至關重要,這造成了3d點云小樣本類增量學習的困難性。
5、在圖像的小樣本類增量學習中,增強其前向兼容性已經被證明是一種有用的方法[9],即在基礎階段創建偽類別或偽階段,使模型能夠更好地擴展到未見過的類別,并能夠有效提升模型對于通用局部特征的分辨能力。然而,創建偽類別的傳統方法,如旋轉、顏色抖動和混疊等,對于三維點云數據并不有效。
技術實現思路
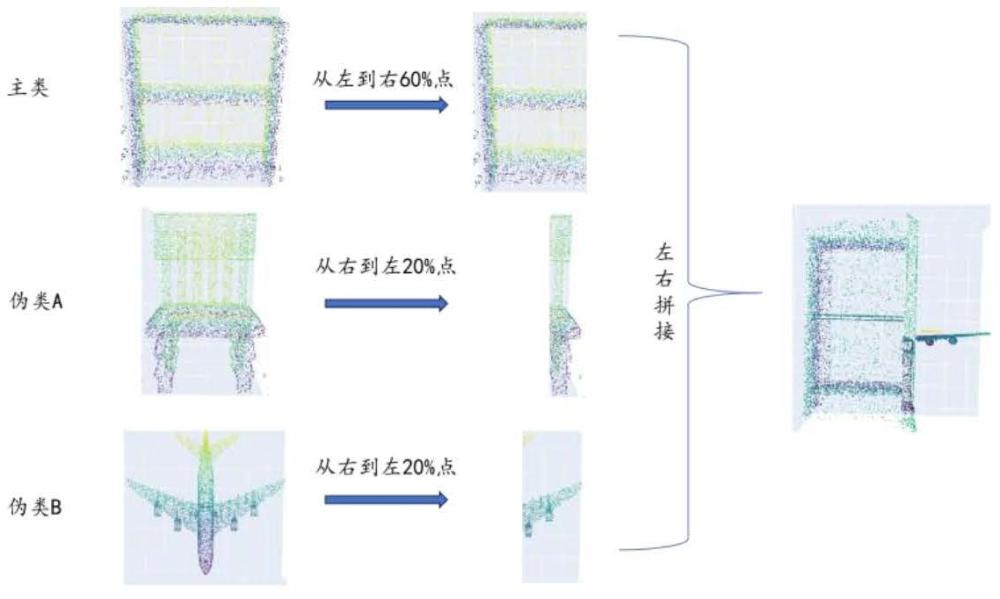
1、如圖2示,本發明提出一種方法,通過將不同類別的三維點云數據的不同部分組合在一起來利用兩個或更多類別的樣本生成偽類別的樣本,從而迫使主干模型在捕捉不同類別間共性的局部特征同時,為新類別的出現預留空間。此外,本發明還提出利用其他模態,如渲染的二維圖像和描述性文本,來增強三維主干模型的擴展能力,因此,本發明也提出了多模態跨類別的偽樣本生成方法及基于對比學習和有監督學習并行的模型預訓練方式。
2、本發明的目的是基于圖像增強和深度學習的理論和方法,研究有效的小樣本增量任務下的模型預訓練技術,其能夠利用基礎類別的樣本,為可能出現的增量類別預留空間,使其在學習新知識的同時不忘記舊有知識。
3、本發明設計了一種基于截斷拼接的多模態跨類別偽樣本構造方法,該項技術從三維點云的偽樣本生成、二維渲染圖像的偽樣本生成、描述性文本的偽樣本生成、原始類別與偽類別組合訓練等多方面做出了創新,從而解決了其他相關技術的痛點問題,多項實驗表明,本發明提出的技術具有明顯的性能優勢。
4、本發明包括以下步驟:
5、步驟s1:多模態偽樣本構造;
6、步驟s11:三維點云偽樣本構造。
7、步驟s12:渲染圖像偽樣本構造。
8、步驟s13:描述文本偽樣本構造。
9、步驟s2:原始類別與偽類別組合;
10、步驟s21:孿生對象選取。
11、步驟s22:偽正樣本對構造。
12、步驟s3:模型訓練過程;
13、步驟s31:基于偽樣本對的對比學習訓練。
14、步驟s32:狹義有監督訓練和廣義有監督訓練。
15、步驟s33:多損失加權訓練。
16、本發明在充分分析三維場景下模型預訓練范式的前提下,定位三維點云數據格式稀疏性問題,并基于多模態跨類別偽樣本的構造和基于偽樣本的模型預訓練方式,提出了具有廣泛應用價值的模型預訓練技術,該技術被用于獲取預訓練模型并進行小樣本類增量學習任務,實驗結果證明本發明達到了十分先進的水平。
17、本發明的有益效果在于:
18、1.如圖2所示,本發明基于原始類別樣本及類別信息,構造多模態跨類別的偽類別樣本,極大地豐富了三維點云場景下的樣本組織形式,使得模型預訓練過程更加充分,對于具有辨識度的細粒度特征具有更優的捕獲能力。
19、2.本發明拓展了多模態對比學習,將跨類別偽類別引入對比學習的框架中,進一步增強了預訓練模型的特征可區分性。
技術特征:
1.一種基于截斷拼接的多模態跨類別偽樣本構造方法技術并用于模型預訓練,其特征在于,包括以下步驟:
2.根據權利要求1所述的方法,其特征在于,步驟s11中,一個偽三維點云樣本通過以下公式生成,其中,是生成過程,xpseudo是生成的偽三維點云樣本,x0,x1,…,xk是用于生成xpseudo的原始三維點云樣本,x0,x1,…,xk分別屬于不同的類別,其中,每個偽三維點云樣本共使用k+1個原始三維點云樣本構造而成,
3.根據權利要求1所述的方法,其特征在于,步驟s12中,通過對原始三維點云預渲染后的圖像進行切割,然后將切割后的圖像水平拼接在一起來生成與偽三維點云樣本所對應的二維渲染圖像,如以下公式所示,其中,concat表示水平拼接,cpi表示每個圖像ii的切割點,其中i表示第i個拼接圖象,i∈{0,1,…,k},[:cpi]表示保留切割后圖像的左半部分,[cpi:]表示保留切割后圖像的右半部分,其中,每個偽圖像樣本共使用k+1個預渲染圖像拼接構造而成,
4.根據權利要求1所述的方法,其特征在于,步驟s13中,利用大型語言模型通過提示學習的方法來生成m種不同的描述性文本p1,…,pm;然后通過以下公式計算第j個描述性文本pj與ipseudo之間的相似度得分sj,其中,和分別是預訓練視覺語言對齊模型中的視覺編碼器和文本編碼器,cos表示余弦相似度,然后選擇得分最高的描述性文本t:
5.根據權利要求1所述的方法,其特征在于,步驟s21中,將從一個樣本作為主體所生成的偽樣本稱為其孿生偽樣本,對于每個樣本,利用不同種類的“輔助”樣本會生成k個偽樣本。
6.根據權利要求1所述的方法,其特征在于,步驟s22中,所有屬于同一個樣本的跨模態樣本對,即三維點云-圖像樣本對、三維點云-文本樣本對,被視為正樣本對;而對于那些屬于一個樣本及其孿生樣本的跨模態樣本對,則將它們視為偽正樣本對。
7.根據權利要求1所述的方法,其特征在于,步驟s31中,被視為正樣本對的原始樣本的不同模態被掩碼處理后,將s22所構造的偽正樣本對中的原始樣本與偽樣本的不同模態被視為正樣本對,并以此進行多模態對比學習。
8.根據權利要求1所述的方法,其特征在于,步驟s32中,采用類別標簽的粒度不同的狹義有監督訓練和廣義有監督訓練并行的訓練方式,在狹義有監督訓練中,偽類別和原始類別視為不同的類別;而在廣義有監督訓練中由同一個原始樣本作為主體所構造的偽樣本也視作與該原始樣本為用一個類別,不額外使用偽類別進行損失計算。
9.一種信息處理設備,包括存儲器、處理器及存儲在存儲器上并可在處理器上運行的程序,其特征在于,所述處理器執行所述程序時實現根據權利要求1-8之一所述的方法。
技術總結
多模態跨類別偽樣本作為一種數據增強方法在深度學習的模型預訓練中具有重要作用,但現有大多數方法局限于二維圖像和一維文本,因而限制了其更廣泛的應用。本發明提出了一種以三維點云稀疏數據結構作為基準的新型偽類別生成方法,該方法將屬于兩個或多個類別的對象的不同組件組合以生成偽樣本,其中,每個偽類別由使用多個相同類別的對象生成的偽樣本組成,本發明期望以此方式生成的偽類別擴展三維點云的學習內容空間。在此基礎上,利用將原始三維點云樣本進行“渲染——拼接”生成偽三維點云樣本的二維圖像,并利用大語言模型生成偽類別的描述信息,最終形成“三維點云、二維圖像、一維文本”的多模態跨類別偽樣本。本發明將這些多模態跨類別偽樣本被用于訓練三維點云小樣本類增量任務下的特征提取器,以此進行三維點云小樣本類增量學習。
技術研發人員:童超,金陸洋,梁宇辰
受保護的技術使用者:北京航空航天大學
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!