一種基于多路融合的法律法規(guī)推薦系統(tǒng)及方法與流程
本發(fā)明屬于自然語言處理的信息召回領域,涉及法律法規(guī)的召回推薦,具體涉及一種基于多路融合的法律法規(guī)推薦系統(tǒng)及方法,即根據(jù)用戶輸入的法律問題推薦能解決這個問題的相關法律法規(guī)。
背景技術:
1、隨著互聯(lián)網(wǎng)的普及和公眾法律意識的增強,越來越多的人選擇通過網(wǎng)絡獲取法律咨詢服務。現(xiàn)有的法條檢索技術主要包括基于關鍵詞匹配、標簽分類以及傳統(tǒng)的分類模型等方法。然而,這些方法各自存在一定的局限性,難以滿足用戶對精準法條推薦和實時響應的需求。
2、1.基于關鍵詞的檢索方法:這類方法依賴于用戶問題中關鍵詞的匹配進行法條檢索。雖然能夠快速找到與關鍵詞相關的法條,但由于缺乏對語義的深刻理解,關鍵詞匹配可能導致檢索結果與用戶真實意圖不符。例如,用戶提問的法律問題如果包含同義詞或表述不同的關鍵詞,基于關鍵詞的檢索往往難以準確捕捉到用戶需求,導致結果偏差。
3、2.基于標簽的檢索方法:該方法通過為法條添加標簽或分類標簽來實現(xiàn)快速檢索。盡管標簽化處理有助于縮小檢索范圍,但標簽的準確性和全面性對系統(tǒng)效果至關重要。標簽劃分通常較為粗糙,無法應對復雜、抽象的法律問題,且標簽的更新和管理難度較大,導致某些法條可能被錯誤地歸類或遺漏,影響推薦的準確性。
4、3.基于分類模型的檢索方法:分類模型通過訓練數(shù)據(jù)集將法律問題歸入不同的類別,再根據(jù)類別返回相關法條。盡管這一方法能在某些情況下提供一定的準確性,但其缺乏靈活性,且對訓練數(shù)據(jù)的依賴較大。如果訓練數(shù)據(jù)不充分或數(shù)據(jù)標注存在偏差,分類模型的準確性會顯著下降。此外,分類模型對用戶提問的深層次語義理解仍顯不足,難以捕捉復雜的法律場景和用戶個性化需求。
5、綜上所述,現(xiàn)有的法條檢索和推薦技術普遍存在對語義理解不足、精準度不高和對用戶意圖的捕捉不精準等問題,無法滿足用戶在法律咨詢過程中的即時性與精確性的雙重需求。因此,迫切需要一種能夠基于深度語義理解,準確預測并推薦相關法條的系統(tǒng),以提升法律咨詢檢索服務的效率與質量。
技術實現(xiàn)思路
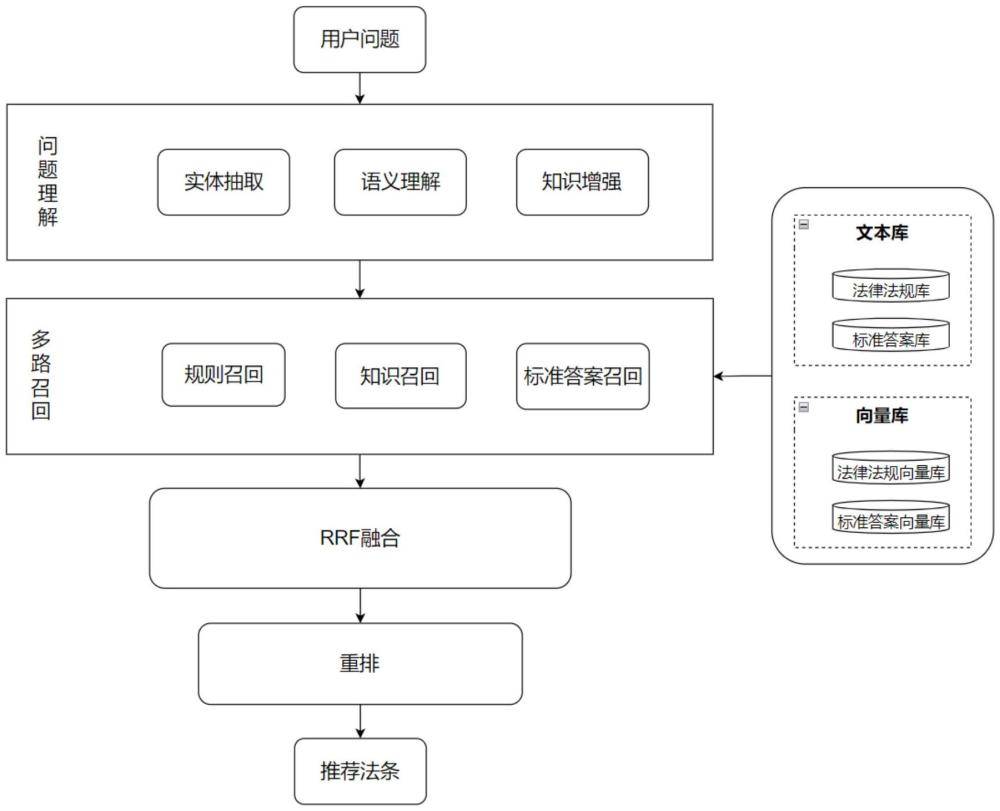
1、本發(fā)明旨在解決現(xiàn)有法律法規(guī)推薦方法中效率低下和準確性差的問題,因此提出了一種基于多路融合的法律法規(guī)推薦系統(tǒng)及方法。該方法通過融合規(guī)則召回、知識召回和標準答案召回等多種召回策略,利用rrf技術對多路結果進行融合并重排。同時,結合意圖理解和主題詞典構建等知識增強方法,強化了問題與法條之間的相關性,顯著提高了法律法規(guī)推薦的準確性,并確保了推薦過程的即時性和精確性。
2、本發(fā)明的技術方案為:
3、一種基于多路融合的法律法規(guī)推薦方法,其步驟包括:
4、1)按法條對法律法規(guī)文本進行拆分并提取結構化內容,構建法律法規(guī)集合e={li|i=1,2,…,n};其中,li表示第i條法條;
5、2)構建標準答案庫,所述標準答案庫中包括多個qa對,每一qa對包括一個問題q和一個答案文本a;
6、3)利用問題-法條對數(shù)據(jù)集g對預訓練的嵌入模型e(·)進行微調,得到微調后的嵌入模型e′(·);利用嵌入模型e′(·)對法律法規(guī)集合e中的每一法條進行向量化并存儲到法條向量庫中;對于所述標準問答庫中的每個問題q,使用預訓練的嵌入模型e(·)進行向量化并存儲到法條向量庫中;
7、4)利用問題理解模塊對收到的用戶問題q進行實體抽取、語義理解和知識增強作為該用戶問題q的擴展信息qe;利用嵌入模型e′(·)對該用戶問題q及其擴展信息qe進行向量化后,并對所得向量進行加權融合得到一個代表用戶意圖的問題向量qvec;
8、5)利用bm25模型從法律法規(guī)庫e中召回出與該用戶問題q最相關的若干相關法條;根據(jù)問題向量qvec與法條向量庫中的每一法條向量進行相似度計算,召回相似度最高的若干法條;以及從所述標準答案庫中選取與用戶問題q語義相似的若干問答對并對每個所選問答對的答案部分進行法條抽取,得到相關的法條集合la作為召回結果;然后對各路召回結果進行綜合排序,選取與用戶問題q最相關的top-k個法條l={l1,l2,…,lk};
9、6)將該top-k個法條l={l1,l2,…,lk}和用戶問題q輸入重排模型,計算l={l1,l2,…,lk}中每一法條與用戶問題q的重排序得分,將重排序得分最高的若干法條返回給用戶。
10、進一步的,步驟1)中,設計多階段提示詞,包括用于生成主題詞的提示詞pm、用于生成關鍵詞的提示詞pk、用于生成關鍵詞的釋義的提示詞pd、用于生成與法條相關的潛在法律問題的提示詞pq;針對每一法條li,首先使用提示詞pm引導大語言模型生成主題詞、利用提示詞pk引導大語言模型生成關鍵詞,利用所生成的主題詞、關鍵詞對法條li進行標注;然后針對法條li的每個關鍵詞kij,使用提示詞pd引導大語言模型生成釋義d(kij);然后基于該法條li的主題詞、關鍵詞和釋義,使用提示詞pq生成與法條li相關的潛在法律問題,預測該法條li的實際應用情境q(t(li),kij,d(kij))={q1,q2,…,qm},其中,qm為法條li對應的第m個潛在問題。
11、進一步的,構建所述標準答案庫的方法為:首先采用模糊匹配方法過濾掉未提及法律條款的答案文本,然后對每一答案文本進行正則提取,得到其包含的法條及其編號,并檢測提取的每一法條的法律狀態(tài),若答案文本中包含任何失效、廢止或不存在的法條,則該答案文本中的qa對將被過濾;然后對保留的每一qa對采用自然語言推理匹配篩選方法進行初步篩選,然后采用多模型校驗方法對初步篩選后保留的每一qa對進行校驗,將校驗通過后的qa對存儲到標準答案庫。
12、進一步的,所述問題-法條對數(shù)據(jù)集g={(qj1,qj2,…,qjm,lj)|j=1,2,…,n},其中,法條lj與m個問題qj1,qj2,…,qjm相關聯(lián),qjm表示大語言模型根據(jù)法條lj生成的第m個問題。
13、進一步的,所述預訓練的嵌入模型e(·)的輸出端引入一稀疏網(wǎng)絡層,用于生成稀疏向量。
14、進一步的,利用嵌入模型e′(·)對法律法規(guī)集合e中的每一法條l轉換為稠密向量el和稀疏向量wl并存儲到法條向量庫中,利用嵌入模型e′(·)對每一法條l對應的關聯(lián)知識轉換為稠密向量和稀疏向量并存儲到法條向量庫中;對于所述標準問答庫中的每個問題q,使用預訓練的嵌入模型e(·)生成該問題q的稠密向量eq和稀疏向量wl并存儲到法條向量庫中;所述關聯(lián)知識包括主題詞、關鍵詞、釋義和潛在問題。
15、進一步的,第i條法條li={法規(guī)名稱,條目號,時效性,法律類型,法條內容,……};各法條以樹狀或表格結構進行存儲。
16、一種基于多路融合的法律法規(guī)推薦系統(tǒng),其特征在于,包括法律法規(guī)集合構建模塊、標準答案庫構建模塊、法條向量庫構建模塊、問題理解模塊、多路徑召回模塊和重排模型;
17、所述法律法規(guī)集合構建模塊,用于按法條對法律法規(guī)文本進行拆分并提取結構化內容,構建法律法規(guī)集合e={li|i=1,2,…,n};其中,li表示第i條法條;
18、所述標準答案庫構建模塊,用于構建標準答案庫,所述標準答案庫中包括多個qa對,每一qa對包括一個問題q和一個答案文本a;
19、所述法條向量庫構建模塊,用于利用問題-法條對數(shù)據(jù)集g對預訓練的嵌入模型e(·)進行微調,得到微調后的嵌入模型e′(·);然后利用嵌入模型e′(·)對法律法規(guī)集合e中的每一法條進行向量化并存儲到法條向量庫中;以及對于所述標準問答庫中的每個問題q,使用預訓練的嵌入模型e(·)進行向量化并存儲到法條向量庫中;
20、所述問題理解模塊,用于對收到的用戶問題q進行實體抽取、語義理解和知識增強作為該用戶問題q的擴展信息qe;利用嵌入模型e′(·)對該用戶問題q及其擴展信息qe進行向量化后,并對所得向量進行加權融合得到一個代表用戶意圖的問題向量qvec;
21、所述多路徑召回模塊,用于利用bm25模型從法律法規(guī)庫e中召回出與該用戶問題q最相關的若干相關法條;根據(jù)問題向量qvec與法條向量庫中的每一法條向量進行相似度計算,召回相似度最高的若干法條;以及從所述標準答案庫中選取與用戶問題q語義相似的若干問答對并對每個所選問答對的答案部分進行法條抽取,得到相關的法條集合la作為召回結果;然后對各路召回結果進行綜合排序,選取與用戶問題q最相關的top-k個法條l={l1,l2,…,lk};
22、所述重排模型,用于計算該top-k個法條l={l1,l2,…,lk}中每一法條與用戶問題q的重排序得分,將重排序得分最高的若干法條返回給用戶。
23、一種服務器,其特征在于,包括存儲器和處理器,所述存儲器存儲計算機程序,所述計算機程序被配置為由所述處理器執(zhí)行,所述計算機程序包括用于執(zhí)行上述方法的指令。
24、一種計算機可讀存儲介質,其上存儲有計算機程序,其特征在于,所述計算機程序被處理器執(zhí)行時實現(xiàn)上述方法。
25、一種基于多路融合的法律法規(guī)推薦方法,包括如下步驟:
26、步驟一、法律法規(guī)庫的建設:(a)從國家法律、地方法規(guī)、立法資料等多個來源,獲取最新最全的法律法規(guī)文本;將收集到的法律法規(guī)按法條進行拆分,并提取結構化內容構建法律法規(guī)集合e={li|i=1,2,…,n}。其中,li表示第i條法條,并包含如下文本信息:li={法規(guī)名稱,條目號,時效性,法律類型,法條內容,……}。法條以樹狀或表格結構進行存儲,方便后續(xù)召回和關聯(lián)查詢。(b)為進一步提升推薦的精準度,設計了多階段提示詞(prompt)引導大語言模型對法條文本進行解析,生成與法條相關的元數(shù)據(jù),包括主題詞、關鍵詞、關鍵詞釋義以及潛在法律問題,多階段提示詞(prompt)包括用于生成主題詞的提示詞pm、用于生成關鍵詞的提示詞pk、用于生成關鍵詞的釋義的提示詞pd、用于生成與法條相關的潛在法律問題的提示詞pq。首先,使用提示詞pm生成主題詞和提示詞pk生成關鍵詞,這些主題詞和關鍵詞用于標注法條的核心內容,方便快速索引和匹配。接著,針對每個關鍵詞kij,使用提示詞pd引導模型生成詳細的釋義和背景信息:d(kij)=釋義(kij),將提示詞pd輸入大語言模型即可直接生成關鍵詞kij的釋義和背景信息。最后,基于主題詞、關鍵詞和釋義,使用提示詞pq生成與法條相關的潛在法律問題,預測該法條的實際應用情境:q(t(li),kij,d(kij))={q1,q2,…,qm},其中,將主題詞t(li)、關鍵詞kij、釋義d(kij)、提示詞pq輸入大語言模型,即可輸出q(t(li),kij,d(kij))={q1,q2,…,qm},qm為第i個法條對應的第m個潛在問題。通過對法規(guī)進行拆分與結構化存儲,系統(tǒng)能夠快速召回和管理大量法規(guī)文本。
27、步驟二、標準答案庫的建設:(a)從互聯(lián)網(wǎng)及公司的法律法規(guī)推薦系統(tǒng)中,自動采集百萬級別真實的用戶法律咨詢問答對(qa對),確保收集范圍廣泛,涵蓋各類法律法規(guī)場景。(b)為了確保標準答案庫的高質量與一致性,需要進行嚴格的質量篩選,過濾掉無效或不合格的問答對,最終所得標準答案庫中包括多個qa對,每一qa對包括一個問題q和一個答案文本a,作為標準法律問答對。具體采用以下多層次的質量篩選方法:
28、1.模糊匹配與規(guī)則過濾
29、為了確保標準答案庫中qa對的答案是基于明確的法律條款,首先要排除那些沒有引用法律法規(guī)的回答。采用模糊匹配與規(guī)則過濾方法來識別和過濾這些無效答案。具體而言,模糊匹配是通過搜索包含法律術語和條款編號的關鍵詞,如“xx法”、“第xx條”、“xx解釋”等,過濾掉未提及法律條款的答案。例如,通過正則表達式來匹配這些關鍵詞:
30、
31、只有滿足match(a)=1的答案才會保留下來。進一步,規(guī)則過濾是對答案文本a進行正則提取法條及其編號,如“勞動法第47條”。這些識別出的法條暫存為集合la={l1,l2…,ln},其中,li表示答案中引用的第i個條款,i=1~n。每個識別出的法條li將與系統(tǒng)中的法律數(shù)據(jù)庫d進行匹配。數(shù)據(jù)庫d中包含了所有現(xiàn)行有效的法律條款,以及它們的狀態(tài)(有效、失效、廢止)。
32、
33、其中,dvalid表示當前有效的法條集合。如果答案中的所有法條均通過校驗(即valid?law?check(li)=1對所有l(wèi)i∈la成立,則該答案被保留:
34、
35、若答案中包含任何失效、廢止或不存在的法條,則該qa對將被過濾。
36、2.自然語言推理匹配篩選
37、為了確保問題與答案的語義相關性,引入自然語言推理(nli)匹配算法進行初步篩選,nli模型可以判斷問題和答案之間的關系(蘊含、矛盾、中立),以確保答案確實回應了問題的意圖。
38、nli模型的工作原理:給定一個問題(q)和一個答案(a),nli模型判斷a與q之間是否存在以下關系之一:
39、entailment(蘊含):答案是對問題的有效回應。
40、contradiction(矛盾):答案與問題相矛盾。
41、neutral(中立):答案與問題無關,無法直接回答問題。
42、篩選規(guī)則與決策公式:使用roberta訓練的nli模型,將問題q和答案a輸入模型,生成三類關系的概率分布:p(e)+p(c)+p(n)=1。其中,p(e)表示蘊含(entailment)的概率,p(c)表示矛盾(contradiction)的概率,p(n)表示中立(neutral)的概率。nli篩選規(guī)則如下:
43、
44、其中,θ是蘊含概率的閾值(建議值為0.85)。只有當p(e)高于θ時,才將該qa對保留。否則,該qa對將被過濾。通過nli篩選方式,能夠更準確地判斷答案是否真正回應了問題,從而減少不相關或無效問答對的進入,提高標準答案庫的整體質量。
45、3.多模型校驗
46、為了進一步加強質量篩選的穩(wěn)健性。在初步篩選后,使用多個高級語義模型(如bert、simcse、大語言模型)對已篩選的qa對進行深度校驗,計算其綜合得分,確保問答對在多模型語義空間中的一致性。融合多個語義匹配模型計算一致性分數(shù),并取平均值,確保結果的穩(wěn)健性:
47、
48、其中,scorei為第i個模型的匹配分數(shù),n為模型總數(shù)。只有最終得分超過某一閾值的qa對,才能被納入標準答案庫。
49、(c)將經(jīng)過質量篩選的高質量qa對以增量方式加入標準答案庫。每次更新后,系統(tǒng)對新加入的qa對執(zhí)行去重操作,確保庫中不存在語義重復的內容。增量更新公式:at+1=at∪δa。其中,at為t時刻的標準答案庫,δa為新篩選出的增量qa對。
50、(d)自動化循環(huán)更新與構建標準問答庫a,系統(tǒng)按設定的時間間隔(如每日、每周)自動執(zhí)行上述步驟(a)、(b)和(c),確保標準答案庫的內容始終最新、完整。自動化過程可通過循環(huán)任務調度系統(tǒng)實現(xiàn),例如:t(i+1)=t(i)+δt,其中t(i)為第i次執(zhí)行時間,δt為間隔周期。這樣設計的自動化流程確保標準答案庫能動態(tài)適應最新的法律法規(guī)和用戶需求,為系統(tǒng)的推薦性能提供了可靠的知識支撐。
51、步驟三、法條向量庫的建設:為了實現(xiàn)基于多路融合的高效法律法規(guī)推薦系統(tǒng),需要構建稀疏與稠密向量庫,以實現(xiàn)法條與問題的語義匹配和高效召回。
52、(a)基于llm合成微調數(shù)據(jù)
53、由于缺乏足夠的高質量問題-法條對數(shù)據(jù),本系統(tǒng)借助大語言模型,為每條法條選擇合適的問題生成策略并隨機生成多個問題,構建多樣化的合成數(shù)據(jù)集。這些問題在廣度和深度上需具備豐富性和覆蓋性,以確保每條法條從多個視角被理解與表述。以下是部分問題生成策略:
54、1.背景類問題:根據(jù)法條的適用情境生成問題,模擬用戶在現(xiàn)實中可能會提出的背景問題。示例:針對勞動法條,生成問題如“公司是否可以在員工試用期無故解雇?”
55、2.反向推理類問題:構建對立或反面的情境,測試法條的邊界與例外情況。示例:針對消費者權益保護法中的條款,生成問題如“退貨時間超過7天還能申請退款嗎?”
56、3.細節(jié)類問題:聚焦于法條的具體細節(jié),如時間、金額、程序規(guī)定等。示例:對于稅法條款,生成問題如“年度申報需要在什么時間之前完成?”
57、4.模糊類問題:生成含有模糊或非正式描述的問題,模擬用戶的日常語言表達。示例:針對知識產(chǎn)權法中的規(guī)定,生成問題如“盜用別人創(chuàng)意的圖片合法嗎?”
58、5.條款比較類問題:比較相似或相近條款之間的差異,幫助用戶了解細微差別。示例:針對合同法和消費者法的條款,生成問題如“商品買賣合同與服務合同有哪些不同?”
59、6.多步推理類問題:設計需要跨多個條款或法規(guī)推理才能得出答案的問題,模擬復雜情境。示例:針對公司法中的多個條款,生成問題如“公司股東能否在債權人提出訴訟后轉讓股份?”
60、7.案例分析類問題:基于實際或假設案例生成問題,幫助模型處理復雜情境。示例:針對刑法條款,生成問題如“如果甲在公共場合散布謠言,是否構成犯罪?”
61、根據(jù)上述策略示例(不僅限于這些類型),為每條法條隨機選擇適用的策略并生成多個問題,以形成多樣化的問題-法條對數(shù)據(jù)集g={(qj1,qj2,…,qjm,lj)|j=1,2,…,n},其中,法條lj與m個問題qj1,qj2,…,qjm相關聯(lián),以增強數(shù)據(jù)集的多樣性和覆蓋度,qjm表示大語言模型根據(jù)法條lj生成的第m個問題。
62、(b)基于合成數(shù)據(jù)集微調嵌入模型
63、預訓練的嵌入模型e(·)是基于通用語料訓練而成,更適用于通用場景下的相似度衡量。然而,當將其應用于法律領域時,該模型在理解法律專業(yè)術語、法條邏輯關系和領域特定語義方面往往不足。為此,有必要利用法律領域數(shù)據(jù)進行微調,使模型能夠更好地適應法律場景下的語義關聯(lián)與匹配需求。因此,本專利利用生成的數(shù)據(jù)集g,對預訓練的嵌入模型e(·)進行微調,使模型更好地捕捉問題與法條之間的語義關聯(lián)。微調過程中,模型會同時優(yōu)化稠密和稀疏向量的表示,以提高召回和匹配的準確性。具體而言,每對數(shù)據(jù)(q,l)∈g將分別生成隱藏狀態(tài)向量:hq=e(q),hl=e(l)。接著,使用norm(·)分別對問題向量hq和法條向量hl的第一個向量歸一化,得到各自的稠密向量:eq=norm(hq[0]),el=norm(hl[0])。稠密召回的核心是計算問題和法條之間的內積,以衡量它們的語義相關性:sdense=<eq,el>。這里,<·>操作表示兩個嵌入向量之間的內積,內積值越大,說明問題和法條之間的語義相關性越高。考慮到法律領域的特殊性,在e(·)的輸出端引入一個稀疏網(wǎng)絡層來解決模型的領域適應性、信息密度以及計算效率等問題,稀疏網(wǎng)絡層用于生成稀疏向量,其輸入hq,輸出是wqt,其結果將存儲到milvus數(shù)據(jù)庫。稀疏網(wǎng)絡層在處理專業(yè)術語或罕見關鍵詞時表現(xiàn)出色,并專注于關鍵特征,而不是捕捉所有細微的關系,這使得它們在文本搜索中更為高效。稀疏化過程的主要目的是基于詞項的權重估計,將問題和法條中的重要詞項挑選出來,并利用這些詞項的權重來進行詞匯召回。這里,使用隱藏狀態(tài)向量hq和hl來估算每個詞項的重要性。具體而言,對于問題中的每個詞項,通過計算它的權重來確定該詞項在問題中的重要性。權重計算公式為:其中,是將隱藏狀態(tài)映射為標量的權重矩陣。hq[i]表示問題中第i個詞項的隱藏狀態(tài)向量。relu(·)是修正線性單元(relu)激活函數(shù),用于確保權重非負。如果某個詞項t在問題中出現(xiàn)了多次,則只保留該詞項的最大權重(即最大的重要性)。這一策略確保重復出現(xiàn)的詞項不會因為簡單的頻率累加而被高估。接著,使用相同的方式計算法條中的詞項權重:hl[i]表示法條中第i個詞項的隱藏狀態(tài)向量。同樣,對于在法條中重復出現(xiàn)的詞項,也只保留它的最大權重。進一步,需要計算問題和法條之間的相關性得分,考慮的是它們之間共有的詞項(即q∩l),并根據(jù)這些詞項的權重來計算最終的匹配得分:ssparse=∑t∈q∩l(wqt·wlt)。其中,wqt和wlt分別表示問題和法條中詞項t的權重。該公式通過對所有共有詞項的權重乘積求和,得到問題和法條之間的詞匯層面相關性得分ssparse。最后,采用聯(lián)合損失函數(shù)優(yōu)化稀疏與稠密向量的語義相關性。通過上述步驟,得到微調后的嵌入模型表示為:e′(·)=finetune(e(·),g)。微調后的模型e′(·)能夠生成高質量的稠密與稀疏向量,并更好地捕捉問題與法條之間的語義關聯(lián)。這一優(yōu)化過程確保了模型在不同層面的語義匹配能力,使法律法規(guī)推薦系統(tǒng)在復雜召回任務中具備更高的準確性與效率。
64、(c)法條、關聯(lián)知識、標準問題入庫
65、為了實現(xiàn)高效召回與匹配,將候選法條、關聯(lián)知識(如主題詞、關鍵詞、釋義和潛在問題等)及標準問答庫的問題編碼為稠密向量和稀疏向量,并將這些向量存儲在milvus向量數(shù)據(jù)庫中,用于快速查詢。具體而言,使用預訓練并微調后的嵌入模型e′(·),將法條l轉換為稠密向量el和稀疏向量wl,然后緩存到milvus向量數(shù)據(jù)庫中。在存入向量后,系統(tǒng)在milvus數(shù)據(jù)庫中為稠密向量表構建ann(近似最近鄰)索引,提升召回性能。同理,關聯(lián)知識也使用了微調后的嵌入模型e′(·)來完成這一向量化入庫過程,生成每一關聯(lián)知識對應的稠密向量和稀疏向量。進一步,對于標準問答庫中的每個問題q,使用未經(jīng)微調的嵌入模型e(·)生成稠密eq和稀疏向量wq。同樣地,將生成的問題向量分別存儲于milvus的對應表中。
66、步驟四、對用戶問題q進行問題理解。用戶輸入一個問題q之后,本系統(tǒng)的問題理解模塊會對這個問題進行深度解析,包括:實體抽取、語義理解和知識增強。具體來說分為以下3個小步驟:
67、(a)實體抽取:利用uie(統(tǒng)一信息抽取)模型從問題q中抽取關鍵實體,如法律名稱qtitle、條目號qitem和查詢主題qkey等。使用uie模型的目的在于其高效性和準確性,能夠迅速地識別并提取文本中的相關法律實體eq={qtitle:[e1,…,en],qitem:[e1,…,en],qkey:[e1,…,en]}。
68、(b)語義理解:引導大語言模型來精確解析問題中的隱含意義和復雜語境。這一步驟通過構建特定的prompt模板,引導模型不僅識別問題的字面意義,還能捕捉到潛在的語義層次,如法律術語的具體應用和語境依賴的意義解釋。
69、(c)知識增強:設計大語言模型的prompt來總結出:法言法語、爭議焦點、法律問題、問題解釋等關鍵信息。在這個階段,模型利用其廣泛的法律知識庫和先前訓練中獲得的語義理解能力,對問題進行深入分析,從而提供詳細的法律見解和解釋,幫助系統(tǒng)準確地識別并回應用戶的法律咨詢需求。
70、(d)融合(a)(b)(c)中解析出來的信息作為問題的擴展信息qe,并利用步驟3微調的嵌入模型e′(·)來編碼q和qe,然后加權融合得到一個代表用戶意圖的問題向量qvec。
71、步驟五、多路召回:為了提高法律法規(guī)推薦系統(tǒng)的準確性和覆蓋面,本發(fā)明通過多路召回方法融合了不同的信息源和模型能力。此過程包括規(guī)則召回、知識召回、標準答案召回三條召回路徑,并利用加權融合與rrf(reciprocal?rank?fusion)算法將各路徑結果綜合排序,最終得到用于下一階段(即重排階段)的相關法條。
72、(a)第一條路徑(規(guī)則召回)使用bm25模型進行召回。該模型主要根據(jù)詞頻和反向文檔頻率來評估問題與法律條文的相關性。對于用戶問題q,利用bm25模型從法律法規(guī)庫e中召回出與問題q最相關的前p個相關法條。bm25的評分函數(shù)為:
73、
74、其中,m為法條總數(shù)量,m(t)是包含詞t的法條數(shù)量,f(t,l)表示詞t在法律l中出現(xiàn)的次數(shù),|l|為法條l的長度,avgdl是平均法條長度,k1和b是可調節(jié)的超參數(shù)。通過bm25計算每條法條的匹配得分,返回top-p法條。
75、(b)第二條路徑(知識召回)利用微調后的嵌入模型e′(·)對用戶問題q及其擴展信息qe編碼,生成向量表示qvec=αe′(q)+βe′(qe),其中α和β為可調節(jié)參數(shù)且α+β=1。將該向量與法條向量庫中的法條向量進行語義相似度計算。法條向量庫中的法條已融合主題、釋義等法律知識,以增強語義匹配能力。向量召回使用余弦相似度計算問題與法條之間的相似度:
76、
77、其中,qvec表示用戶問題的向量表示,lvec為法條的向量表示。最終召回top-p法條。
78、(c)第三條路徑(標準答案召回)從標準答案庫中召回與用戶問題q語義相似的top-n個問答對(q,ai)。對答案部分ai進行法條抽取,得到相關的法條集合la={la1,la2,…,lan}。
79、(d)多路召回結果融合與排序,rrf算法用于融合三條路徑的召回結果。對于每條法條li的rrf得分計算公式如下:
80、
81、其中,r為路徑的數(shù)量,kr為路徑r的平滑參數(shù),rankr(li)是法條li在路徑r中的排名。最終根據(jù)rrf得分對法條進行排序,返回top-k法條作為下一階段(即重排階段)的輸入。
82、步驟六、在多路召回獲得top-k法條之后,系統(tǒng)進入重排階段,進一步優(yōu)化推薦順序。此階段通過重排模型對初步召回結果進行二次排序,以提高推薦結果的準確性和相關性。重排模型是一個監(jiān)督學習模型,輸入為多路召回得到的top-k法條l={l1,l2,…,lk}和用戶問題q,輸出為法條的重排序得分s(li)及最終排序。重排模型的目標是捕捉法條與用戶問題之間的深層語義關系,同時結合上下文信息和法條的法律知識進行精細化排序。
83、本發(fā)明的優(yōu)點如下:
84、優(yōu)點1:多路融合:通過規(guī)則召回、知識召回與標準答案召回三種路徑并行檢索,并利用rrf進行融合重排,將不同信息源的優(yōu)勢進行高效整合,從而顯著提升法條推薦的精確度與全面性。
85、優(yōu)點2:知識增強與多維度向量化:在法律法規(guī)庫構建中引入主題詞、關鍵詞、釋義及潛在法律問題等元數(shù)據(jù),并通過多階段提示詞(prompt)技術對法條進行深度解析與標注。同時,將法條及相關知識進行稀疏與稠密向量化處理,使系統(tǒng)在檢索時既能依托詞項的權重獲得穩(wěn)健結果,又能依靠深層語義理解的嵌入模型實現(xiàn)高相關度匹配,從而實現(xiàn)快速、精準且深度智能的法律法規(guī)推薦。
86、優(yōu)點3:自動化構建高質量標準答案庫:通過自動化采集、嚴格多層次質量篩選與多模型校驗策略構建高可信度的標準答案庫,為召回路徑之一提供有效參考。這種嚴謹?shù)臄?shù)據(jù)治理與優(yōu)化流程,確保了系統(tǒng)在復雜法律咨詢場景下能夠持續(xù)穩(wěn)定地提供準確而可靠的法條推薦結果。
- 還沒有人留言評論。精彩留言會獲得點贊!