一種多實(shí)例GPU下的工作負(fù)載配置優(yōu)化方法及系統(tǒng)與流程
本發(fā)明涉及人工智能領(lǐng)域、大型語言模型領(lǐng)域,具體涉及一種多實(shí)例gpu下的工作負(fù)載配置優(yōu)化方法及系統(tǒng)。
背景技術(shù):
1、gpu是llm預(yù)訓(xùn)練、微調(diào)和推理的核心。它們已成為計算領(lǐng)域最珍貴、最昂貴的資源之一,需求遠(yuǎn)遠(yuǎn)超過可用性。
2、大型語言模型(llm)需要強(qiáng)大的計算能力,特別是依賴于gpu。gpu作為并行處理能力強(qiáng)的硬件設(shè)備,在大模型的推理過程中扮演了至關(guān)重要的角色。然而,隨著生成式ai和llm的快速發(fā)展,gpu在推理應(yīng)用中也面臨許多問題和挑戰(zhàn)。
3、llm是當(dāng)前人工智能領(lǐng)域中最先進(jìn)的自然語言處理技術(shù)之一,能夠處理各種復(fù)雜的語言任務(wù)。其大規(guī)模參數(shù)和強(qiáng)大的語言建模能力使其在對話、文本生成、翻譯等領(lǐng)域取得了顯著的成果,但同時也面臨著計算資源消耗大、推理效率等問題。
4、mig(multi-instance?gpu,即多實(shí)例gpu)技術(shù)允許將gpu分割為多個實(shí)例,使得多個任務(wù)可以共享一個gpu資源,如將llm推理任務(wù)作為工作負(fù)載部署在mig上,但在實(shí)際應(yīng)用中面臨資源利用不足、遷移效率低、gpu碎片化等問題。
5、綜上所述,當(dāng)前大型語言模型的gpu資源分配存在以下缺點(diǎn):
6、1.缺乏智能化的工作負(fù)載放置策略:傳統(tǒng)的工作負(fù)載分配策略大多采用簡單的“先到先得”或固定的負(fù)載均衡算法,忽略了不同工作負(fù)載對gpu資源的具體需求,無法實(shí)現(xiàn)精細(xì)化的資源管理。
7、2.gpu碎片化問題:隨著任務(wù)增減,gpu資源可能變得碎片化,導(dǎo)致gpu部分資源無法被充分利用。現(xiàn)有的分區(qū)和遷移策略無法有效解決這個問題。
8、3.遷移效率低:任務(wù)從一個gpu遷移到另一個gpu時,會有一定的開銷,當(dāng)前的技術(shù)缺乏高效的遷移規(guī)劃,可能導(dǎo)致任務(wù)遷移過程中的性能下降。
9、4.llm推理任務(wù)運(yùn)行在mig上,沒有充分利用mig的計算和內(nèi)存資源。
技術(shù)實(shí)現(xiàn)思路
1、本發(fā)明要解決的技術(shù)問題:針對現(xiàn)有技術(shù)的上述問題,提供一種多實(shí)例gpu下的工作負(fù)載配置優(yōu)化方法及系統(tǒng),確保高效地利用多實(shí)例gpu的分區(qū)功能,實(shí)現(xiàn)最優(yōu)工作負(fù)載放置和遷移,進(jìn)而實(shí)現(xiàn)llm推理任務(wù)更加高效運(yùn)行。
2、為了解決上述技術(shù)問題,本發(fā)明采用的技術(shù)方案為:
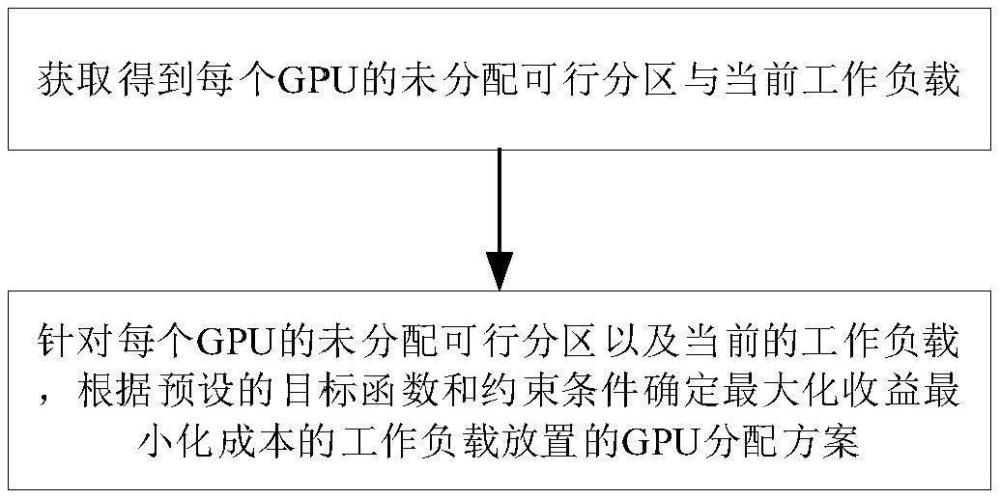
3、一種多實(shí)例gpu下的工作負(fù)載配置優(yōu)化方法,包括下述步驟:從當(dāng)前已有的gpu中獲取得到每個gpu的未分配可行分區(qū),所述未分配可行分區(qū)是指gpu未分配但是可以分配的區(qū)域的集合;獲取每個gpu當(dāng)前的工作負(fù)載;針對每個gpu的未分配可行分區(qū)以及當(dāng)前的工作負(fù)載,根據(jù)預(yù)設(shè)的目標(biāo)函數(shù)和約束條件確定最大化收益最小化成本的工作負(fù)載放置的gpu分配方案,所述目標(biāo)函數(shù)包括實(shí)現(xiàn)最大化工作負(fù)載的收益,同時最小化gpu使用成本、重新分區(qū)成本、工作負(fù)載遷移成本以及資源浪費(fèi)成本,所述約束條件用于確保在gpu上放置的工作負(fù)載不會超過其可用的計算實(shí)例和內(nèi)存。
4、進(jìn)一步的,所述目標(biāo)函數(shù)的函數(shù)表達(dá)式為:
5、
6、上式中:
7、是通過放置工作負(fù)載w到未分配可行分區(qū)所在的gpu?g來實(shí)現(xiàn)最大化收益,pw是放置工作負(fù)載w所帶來的收益,xwg是決策變量,表示工作負(fù)載w是否被分配到gpu?g,是則為1,否則為0;
8、是使用gpu?g的成本,qg為使用gpu?g的成本,yg為gpu?g的使用標(biāo)記,如果gpu?g被使用,則為1,否則為0;
9、是重新分區(qū)的成本,表示重新配置gpu?g的懲罰因子;
10、是工作負(fù)載w從已分區(qū)的gpu?g′遷移到gpu?g的工作負(fù)載遷移成本,表示遷移工作負(fù)載w的懲罰因子,xwg′為gpu?g′的分配標(biāo)記,如果工作負(fù)載w被分配到gpu?g′,則為1,否則為0,xwg為gpu?g的分配標(biāo)記,如果工作負(fù)載w被分配到gpu?g,則為1,否則為0;
11、是gpu?g的資源浪費(fèi)成本,是gpu?g上未使用資源的懲罰因子,ug是gpu?g上浪費(fèi)的計算資源,vg是gpu?g上浪費(fèi)的內(nèi)存資源。
12、進(jìn)一步的,所述約束條件包括:
13、每個未分配可行分區(qū)所在的gpu?g上的工作負(fù)載不能超過其計算實(shí)例的總量,表達(dá)式如下:
14、
15、對于已分區(qū)的gpu?g′,每個分區(qū)內(nèi)的工作負(fù)載總量不能超過該分區(qū)的計算能力,表達(dá)式如下:
16、
17、已分區(qū)的gpu?g′中的分區(qū)數(shù)量不超過可用的計算實(shí)例數(shù),表達(dá)式如下:
18、
19、上式中,cg表示gpu?g的總計算切片數(shù),cg′表示gpu?g′的總計算切片數(shù),zg′為分配輔助變量,如果工作負(fù)載w被分配到在已有工作負(fù)載的gpu集合g′中的可用分區(qū)集合p的已分區(qū)gpu?g′時為1,否則為0。
20、進(jìn)一步的,所述約束條件還包括:
21、每個工作負(fù)載只能放置在一個gpu或分區(qū)中,表達(dá)式如下:
22、
23、每個gpu上的工作負(fù)載計算需求不能超過總計算能力:
24、
25、每個gpu的工作負(fù)載內(nèi)存需求不能超過總內(nèi)存:
26、
27、上式中,cw為工作負(fù)載w所需的計算切片,ug為gpu?g上的計算資源使用量;mw為工作負(fù)載w所需的內(nèi)存,sg為跨gpu切片的公共內(nèi)存因子,mg為gpu?g的總內(nèi)存大小。
28、進(jìn)一步的,所述約束條件還包括:
29、計算未分配可行分區(qū)所在的gpu?g上因計算和內(nèi)存使用不均衡導(dǎo)致浪費(fèi)的計算資源ug,表達(dá)式如下:
30、
31、計算未分配可行分區(qū)所在的gpu?g上計算資源使用量ug的區(qū)間,表達(dá)式如下:
32、
33、計算未分配可行分區(qū)所在的gpu?g上計算資源已滿時浪費(fèi)的內(nèi)存資源vg,表達(dá)式如下:
34、
35、上式中,vg為gpu?g上的內(nèi)存使用量,δg為輔助二進(jìn)制變量,表示gpu?g的計算切片是否已滿,是則為1,否則為0。
36、進(jìn)一步的,當(dāng)前已有的gpu包括虛擬gpu,所述約束條件還包括:
37、當(dāng)虛擬gpu使用時原始gpu不再使用,表達(dá)式如下:
38、
39、上式中,yg′為gpu?g′的使用標(biāo)記,如果gpu?g′被使用,則為1,否則為0。
40、本發(fā)明還提出一種多實(shí)例gpu下的工作負(fù)載配置優(yōu)化系統(tǒng),包括:
41、預(yù)處理模塊:用于從當(dāng)前已有的gpu中獲取得到每個gpu的未分配可行分區(qū),所述未分配可行分區(qū)是指gpu未分配但是可以分配的區(qū)域的集合;獲取每個gpu當(dāng)前的工作負(fù)載;
42、資源分配模塊,用于針對每個gpu的未分配可行分區(qū)以及當(dāng)前的工作負(fù)載,根據(jù)預(yù)設(shè)的目標(biāo)函數(shù)和約束條件確定最大化收益最小化成本的工作負(fù)載放置的gpu分配方案,所述目標(biāo)函數(shù)包括實(shí)現(xiàn)最大化工作負(fù)載的收益,同時最小化gpu使用成本、重新分區(qū)成本、工作負(fù)載遷移成本以及資源浪費(fèi)成本,所述約束條件用于確保在gpu上放置的工作負(fù)載不會超過其可用的計算實(shí)例和內(nèi)存。
43、本發(fā)明還提出一種多實(shí)例gpu下的工作負(fù)載配置優(yōu)化裝置,包括相互連接的微處理器和存儲器,所述微處理器被編程或配置以執(zhí)行任意一項所述多實(shí)例gpu下的工作負(fù)載配置優(yōu)化方法。
44、本發(fā)明還提出一種計算機(jī)可讀存儲介質(zhì),該計算機(jī)可讀存儲介質(zhì)中存儲有計算機(jī)程序或指令,該計算機(jī)程序或指令被編程或配置以通過處理器執(zhí)行任意一項所述多實(shí)例gpu下的工作負(fù)載配置優(yōu)化方法。
45、本發(fā)明還提出一種計算機(jī)程序產(chǎn)品,包括計算機(jī)程序或指令,該計算機(jī)程序或指令被編程或配置以通過處理器執(zhí)行任意一項所述多實(shí)例gpu下的工作負(fù)載配置優(yōu)化方法。
46、和現(xiàn)有技術(shù)相比,本發(fā)明主要具有下述優(yōu)點(diǎn):
47、本發(fā)明構(gòu)建的目標(biāo)函數(shù)通過最大化工作負(fù)載放置的收益并最小化gpu使用、遷移和資源浪費(fèi)的成本,構(gòu)建的約束條件保證了能夠在每個gpu或分區(qū)中合理放置工作負(fù)載的同時,避免超出gpu的計算或內(nèi)存能力。本發(fā)明基于每個gpu的未分配可行分區(qū),通過目標(biāo)函數(shù)和約束條件對工作負(fù)載進(jìn)行重新分配,可以最大化gpu利用率、減少計算和內(nèi)存浪費(fèi),同時支持工作負(fù)載的高效伸縮以適應(yīng)多實(shí)例gpu下頻繁的工作負(fù)載切換要求,盡量減少遷移工作負(fù)載和重分區(qū)的時間和計算開銷,以提高整體計算效率。
- 還沒有人留言評論。精彩留言會獲得點(diǎn)贊!