一種基于串行抵消列表極化碼譯碼的動態(tài)分布排序算法的制作方法
本發(fā)明涉及一種基于串行抵消列表極化碼譯碼的動態(tài)分布排序算法。
背景技術(shù):
Arlkan提出,極性碼是信道編碼的第一類,幾乎可實(shí)現(xiàn)對稱的二進(jìn)制輸入離散無記憶信道的容量(B-DMCs)。由于其較低的計(jì)算復(fù)雜度為O(NlogN),其中N為極化碼長度;以及快速傅氏變換Fast Fourier Transformation(FFT)形式的譯碼結(jié)構(gòu),串行抵消譯碼successive cancellation(SC)算法已經(jīng)成為最有效的極化譯碼算法之一。然而相比于最大似然maximum likelihood(ML)解碼器,串行抵消譯碼器的解碼性能仍然有較大的衰落。為了縮小由傳統(tǒng)的串行抵消譯碼器的次最優(yōu)路徑選擇帶來的性能差距,列表串行抵消譯碼算法(list SC polar decoder)應(yīng)運(yùn)而生。加入列表(L)后,帶來了更多的路徑選擇的機(jī)會。
SCL譯碼算法的主要思想是在譯碼樹擴(kuò)展中選出最優(yōu)的L條路徑,并對最優(yōu)的L條路徑再一次擴(kuò)展。級每一層譯碼都會涉及一個(gè)從2L個(gè)候選節(jié)點(diǎn)中篩選出最優(yōu)的L個(gè)節(jié)點(diǎn)的排序操作。串行抵消列表譯碼器的主要缺點(diǎn)是,隨著列表L大小的增大,譯碼器排序部分的的復(fù)雜度非線性增加。在路徑擴(kuò)展過程中,需要從2L個(gè)擴(kuò)展路徑中標(biāo)選出L個(gè)具有最大路徑度量值的路徑作為候選路徑。若選擇類似于冒泡排序或者選擇排序方法來實(shí)現(xiàn),其運(yùn)算復(fù)雜度為O(L2);若選擇類似于堆排序方法來實(shí)現(xiàn),其運(yùn)算復(fù)雜度為O(Llog2L),但同時(shí)也增加了所需的內(nèi)存單元。此外,兩種算法的延時(shí)較大,不利于高速的硬件實(shí)現(xiàn)。
技術(shù)實(shí)現(xiàn)要素:
發(fā)明目的:本發(fā)明的目的是提供一種能夠解決現(xiàn)有技術(shù)中存在的缺陷的基于串行抵消列表極化碼譯碼的動態(tài)分布排序算法。
技術(shù)方案:為達(dá)到此目的,本發(fā)明采用以下技術(shù)方案:
本發(fā)明所述的基于串行抵消列表極化碼譯碼的動態(tài)分布排序算法,包括以下步驟:
S1:針對L條路徑進(jìn)行擴(kuò)展:每個(gè)父節(jié)點(diǎn)的兩個(gè)擴(kuò)展子節(jié)點(diǎn)分別設(shè)為FC和NC,其中FC為較優(yōu)路徑,NC為較差路徑,并將得到的L個(gè)FC節(jié)點(diǎn)設(shè)為集合FCS,將得到的L個(gè)NC節(jié)點(diǎn)設(shè)為集合NCS;
S2:將L個(gè)FC節(jié)點(diǎn)設(shè)為L條最優(yōu)路徑,用集合C表示;
S3:初始化i=1,i為排序輪數(shù);
S4:根據(jù)實(shí)際性能要求設(shè)定最大排序輪數(shù)n,且1≤n≤L-1;
S5:對于第i輪排序,將集合FCS中所剩的L-i+1個(gè)FC節(jié)點(diǎn)中選出最差的路徑FCi,將集合NCS中所剩的L-i+1個(gè)NC節(jié)點(diǎn)中選出最優(yōu)的路徑NCi;
S6:比較FCi與NCi:如果FCi較優(yōu),則排序結(jié)束,跳轉(zhuǎn)到步驟S12;否則,繼續(xù)進(jìn)行步驟S7;
S7:將集合C中的FCi路徑替換為NCi節(jié)點(diǎn);
S8:將集合FCS中的FCi元素刪除,則集合FCS中的元素個(gè)數(shù)變?yōu)長-i;
S9:將集合NCS中的NCi元素刪除,則集合NCS中的元素個(gè)數(shù)變?yōu)長-i;
S10:更新i值,i=i+1;
S11:如果i<n,則跳轉(zhuǎn)到步驟S5進(jìn)行下一輪排序;否則,則繼續(xù)進(jìn)行步驟S12;
S12:排序完成,最優(yōu)的L條路徑為集合C中的路徑。
有益效果:與現(xiàn)有技術(shù)相比,本發(fā)明具有如下的有益效果:
1)本發(fā)明利用了SCL譯碼要求中,從2L條擴(kuò)展路徑中選取L條最優(yōu)路徑的特點(diǎn),對于L條所選路徑不需要知道順序結(jié)果,避免了直接排序;
2)本發(fā)明利用了擴(kuò)展節(jié)點(diǎn)中L個(gè)FCs節(jié)點(diǎn)很大可能性為最終的L條最優(yōu)路徑,以FC節(jié)點(diǎn)為基礎(chǔ),用替換掉較差FC的方式調(diào)整排序結(jié)果,極大降低了排序復(fù)雜度;
3)本發(fā)明將復(fù)雜度為O(L2)的冒泡排序或復(fù)雜度為O(Llog2L)的堆排序降低到了復(fù)雜度為O(L)的動態(tài)分布式排序;
4)本發(fā)明是動態(tài)排序,其排序延時(shí)不是固定的。由于FC節(jié)點(diǎn)大比例優(yōu)于NC節(jié)點(diǎn),在針對一幀極化碼的每層動態(tài)排序中,大多數(shù)排序只需要一輪排序,即沒有NC節(jié)點(diǎn)與FC節(jié)點(diǎn)的替換。
附圖說明
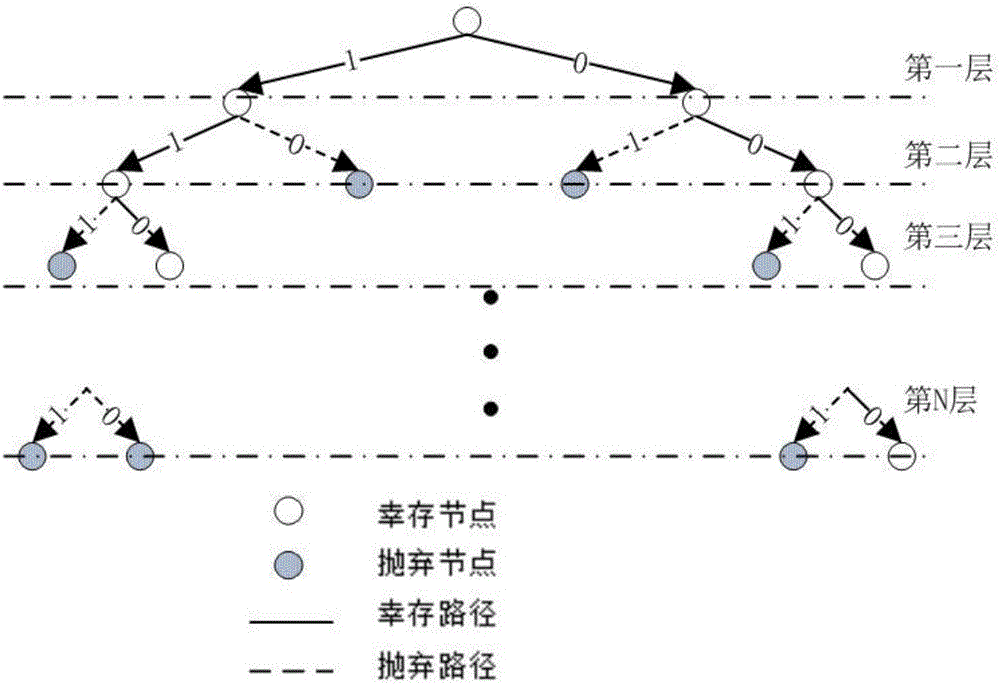
圖1為N比特Polar碼的搜索碼樹;
圖2為采用本發(fā)明具體實(shí)施方式方法與采用一般SCL譯碼算法的誤幀率性能對比圖;
圖3為本發(fā)明具體實(shí)施方式中DS2算法的平均計(jì)算周期;
圖4為本發(fā)明具體實(shí)施方式中DS3算法的平均計(jì)算周期。
具體實(shí)施方式
下面結(jié)合具體實(shí)施方式對本發(fā)明的技術(shù)方案作進(jìn)一步的介紹。
1、搜索碼樹
Polar碼的SCL譯碼算法本質(zhì)上是寬度優(yōu)先的樹形搜索算法,N比特Polar碼的搜索碼樹如圖1所示,L為保留路徑數(shù)。圖1中第N層中路徑度量值(Path Metric,PM)最大的路徑(幸存路徑)即為譯碼輸出次數(shù)表示向量,標(biāo)號為1到N的N個(gè)譯碼結(jié)果。
2、SCL算法
對于參數(shù)為的Polar碼,N為碼長,K為信息位數(shù)量。對應(yīng)信道WN的輸出向量為表示接受的標(biāo)號為1到N的N個(gè)接受數(shù)據(jù)。A為信息位分布情況集合。為凍結(jié)位的值,通常設(shè)為0。譯碼的路徑度量值定義為信道轉(zhuǎn)移概率常采用其對數(shù)形式。為了降低計(jì)算和存儲的復(fù)雜度,我們采用等價(jià)的路徑度量值定義如下:
其譯碼的遞推公式如下:
其中表示N比特譯碼器的第i個(gè)譯碼PM值,表示對應(yīng)節(jié)點(diǎn)的部分和。與表示連接節(jié)點(diǎn)上層迭代的兩個(gè)部分和。表示異或計(jì)算,max*代表Jacobi對數(shù):
初始化條件其中σ2為噪聲方差。max(x1,x2)為取x1,x2中的最大值。
3、本具體實(shí)施方式
在路徑擴(kuò)展過程中,需要從2L個(gè)擴(kuò)展路徑中標(biāo)選出L個(gè)具有最大路徑度量值的路徑作為候選路徑。若選擇類似于冒泡排序或者選擇排序方法來實(shí)現(xiàn),其運(yùn)算復(fù)雜度為O(L2);若選擇類似于堆排序方法來實(shí)現(xiàn),其運(yùn)算復(fù)雜度為O(Llog2L),但同時(shí)也增加了所需的內(nèi)存單元。此外,兩種算法的延時(shí)較大,不利于高速的硬件實(shí)現(xiàn)。
本具體實(shí)施方式公開了一種基于串行抵消列表極化碼譯碼的動態(tài)分布排序算法包括以下步驟:
S1:針對L條路徑進(jìn)行擴(kuò)展:每個(gè)父節(jié)點(diǎn)的兩個(gè)擴(kuò)展子節(jié)點(diǎn)分別設(shè)為FC和NC,其中FC為較優(yōu)路徑,NC為較差路徑,并將得到的L個(gè)FC節(jié)點(diǎn)設(shè)為集合FCS,將得到的L個(gè)NC節(jié)點(diǎn)設(shè)為集合NCS;
S2:將L個(gè)FC節(jié)點(diǎn)設(shè)為L條最優(yōu)路徑,用集合C表示;
S3:初始化i=1,i為排序輪數(shù);
S4:根據(jù)實(shí)際性能要求設(shè)定最大排序輪數(shù)n,且1≤n≤L-1;
S5:對于第i輪排序,將集合FCS中所剩的L-i+1個(gè)FC節(jié)點(diǎn)中選出最差的路徑FCi,將集合NCS中所剩的L-i+1個(gè)NC節(jié)點(diǎn)中選出最優(yōu)的路徑NCi;
S6:比較FCi與NCi:如果FCi較優(yōu),則排序結(jié)束,跳轉(zhuǎn)到步驟S12;否則,繼續(xù)進(jìn)行步驟S7;
S7:將集合C中的FCi路徑替換為NCi節(jié)點(diǎn);
S8:將集合FCS中的FCi元素刪除,則集合FCS中的元素個(gè)數(shù)變?yōu)長-i;
S9:將集合NCS中的NCi元素刪除,則集合NCS中的元素個(gè)數(shù)變?yōu)長-i;
S10:更新i值,i=i+1;
S11:如果i<n,則跳轉(zhuǎn)到步驟S5進(jìn)行下一輪排序;否則,則繼續(xù)進(jìn)行步驟S12;
S12:排序完成,最優(yōu)的L條路徑為集合C中的路徑。
本具體實(shí)施方式公開的分布式排序算法(DS)近似于一般的排序算法,但其存儲和比較復(fù)雜度均低于一般排序算法。當(dāng)前面的比較不滿足條件時(shí),算法退出,不再進(jìn)行后續(xù)比較,大大降低了平均的比較復(fù)雜度。由分析及相關(guān)仿真可知,PMs中較大的i值對應(yīng)的路徑度量值越小,很有可能是需要丟棄的,對算法的影響因素占主導(dǎo)。僅取i=L-1~L-n完成路徑的擴(kuò)展及度量值排序,稱為DSn,設(shè)定參數(shù)n為最大比較輪數(shù)。此時(shí),算法1中對的排序操作是不需要的,只需要查找其最大、最小、次大及次小值等若干值即可。硬件實(shí)現(xiàn)中,我們可做進(jìn)一步的變化,查找的最小、次小值來代替查找的最小、次小值,在復(fù)雜度相同的情況下,提高譯碼性能。通過仿真可知,基于DS2(L=4)或DS3(L=8)的SCL譯碼算法與CRC校驗(yàn)相結(jié)合后,譯碼的誤診率性能損失幾乎可以忽略。當(dāng)L較大時(shí),如L=16、32,單純的DS2或DS3算法帶來的性能損失較大,對前N/2比特采用完全的DS算法,后N/2比特采用DS3算法來實(shí)現(xiàn)。
以L=4為例,基于DS2算法的路徑擴(kuò)展過程如下:1,將四條路徑分別區(qū)分出四個(gè)FC節(jié)點(diǎn)與四個(gè)NC節(jié)點(diǎn);2,在四個(gè)FC節(jié)點(diǎn)中找出最差的節(jié)點(diǎn)FC1,在四個(gè)NC節(jié)點(diǎn)中找出最優(yōu)的節(jié)點(diǎn)NC1;3,比較FC1與NC1,如果FC1較大,則排序結(jié)束,選取的四條較優(yōu)路徑為四個(gè)FC對應(yīng)的路徑,不必進(jìn)行下面的操作,反之進(jìn)行下面的操作;4,用NC1對應(yīng)的路徑替換FC1,且這兩個(gè)值不再進(jìn)入比較操作;5,在剩下的三個(gè)FC中選出最差的節(jié)點(diǎn)FC2,在剩下的三個(gè)NC節(jié)點(diǎn)中找出最優(yōu)的節(jié)點(diǎn)NC2;6,比較FC2與NC2,如果FC2較大,則排序結(jié)束,選取的四條較優(yōu)路徑為三個(gè)FC與NC1對應(yīng)的路徑,反之,選取的四條路徑為剩下兩個(gè)FC與NC1和NC2對應(yīng)的路徑,排序結(jié)束。DS2算法將度量值的比較復(fù)雜度由O(L2)降低為O(L)。DS2算法易于硬件的并行就流水線實(shí)現(xiàn),可降低復(fù)雜度,提高數(shù)據(jù)處理速率。
對于不同的L值,改進(jìn)的SCL譯碼與一般SCL譯碼的誤幀率性能對比如圖2所示,圖2中為碼長1024有效信息位512的極化碼。L=4時(shí),基于DS2算法的SCL譯碼與一般的SCL譯碼具有幾乎一致的誤幀率性能,可作為低復(fù)雜度硬件實(shí)現(xiàn)的一個(gè)較好選擇;L=8時(shí),基于DS3算法的SCL譯碼與一般的SCL譯碼具有幾乎一致的誤幀率性能,可作為低復(fù)雜度硬件實(shí)現(xiàn)的一個(gè)較好選。
本具體實(shí)施方式的另一個(gè)優(yōu)勢在于,本排序是一個(gè)動態(tài)的排序過程,排序所要進(jìn)行的輪數(shù)是不確定的。由于SCL譯碼過程本身具有的性質(zhì),L條路徑中的擴(kuò)展下的各FC節(jié)點(diǎn)很大可能性就是最終的所篩選出的L條最優(yōu)路徑。故在譯碼過程中大多數(shù)分布式排序過程只需要進(jìn)行一輪排序。通過仿真可以證明排序長度極低。
從圖3仿真中可以看出當(dāng)L=4時(shí)采用本具體實(shí)施方式中的DS2排序算法平均只需要進(jìn)行1.075輪排序(8個(gè)周期),在時(shí)序上也比嚴(yán)格排序有了很大提升(若使用傳統(tǒng)的冒泡排序需要的排序時(shí)鐘為L2數(shù)量級,即16個(gè)周期)。從圖4仿真中可以看出當(dāng)L=8時(shí)采用本具體實(shí)施方式中的DS3排序算法平均只需要進(jìn)行1.074輪排序(16個(gè)周期),在時(shí)序上也比嚴(yán)格排序有了很大提升(若使用傳統(tǒng)的冒泡排序需要的排序時(shí)鐘為L2數(shù)量級,即64個(gè)周期)。本具體實(shí)施方式中的分布式排序算法平均排序消耗在一輪左右,極大的降低了排序所浪費(fèi)的延時(shí)。
- 還沒有人留言評論。精彩留言會獲得點(diǎn)贊!
- 基于干擾合成的迫零及串行干擾消除的多用戶接收方法
- 一種lte全雙工系統(tǒng)自干擾級聯(lián)抵消的方法
- 用于網(wǎng)絡(luò)輔助的干擾抵消的信道狀態(tài)信息參考信號(csi-rs)處理的制作方法
- 同構(gòu)網(wǎng)絡(luò)中的共用參考信號干擾抵消觸發(fā)的制作方法
- 一種用于拖曳線列陣的逆波束形成干擾抵消方法
- 一種同時(shí)同頻全雙工極限自干擾抵消系統(tǒng)的制作方法
- 一種同時(shí)同頻全雙工極限自干擾抵消方法
- 低復(fù)雜度的gfsk符號間干擾抵消處理方法及裝置的制造方法
- 一種串行干擾抵消檢測系統(tǒng)的制作方法
- 基于反饋串行干擾抵消算法的地基偽衛(wèi)星接收機(jī)定位方法
- 在多層譯碼中譯碼恢復(fù)點(diǎn)補(bǔ)充增強(qiáng)信息(sei)消息和區(qū)刷新信息sei消息的方法
- 在多層譯碼中用于對參考圖片集(rps)進(jìn)行譯碼的方法
- 具有新穎的二進(jìn)制元素譯碼多標(biāo)準(zhǔn)視頻譯碼器的制造方法
- 增強(qiáng)安全性的lt碼編譯碼方法
- 基于算術(shù)碼與低密度奇偶校驗(yàn)碼的迭代聯(lián)合信源信道譯碼方法
- 一種新型譯碼器裝置的制造方法
- 用于內(nèi)插視頻譯碼的子像素的值的自適應(yīng)支持的制作方法
- 一種確定譯碼時(shí)刻的方法和裝置的制造方法
- 用于內(nèi)插視頻譯碼的子像素的值的自適應(yīng)支持的制作方法
- 一種確定譯碼時(shí)刻的方法和裝置的制造方法