一種語言模型優化方法及裝置與流程
本發明涉及語音識別技術領域,特別是涉及一種語言模型優化方法及裝置。
背景技術:
n-gram語言模型是現階段語音識別中最為常用的一種語言模型,可以通過對分詞后的文本進行統計計算獲得。這種模型基于馬爾科夫假設,認為句子中第n個詞的出現概率至于前面的n-1個詞有關。在自然語言處理中應用廣泛,主要用途為判斷某句話的成句概率。
但n-gram語言模型本身具有語義孤立的缺陷,即無法認知不同單詞之間的聯系,僅憑統計信息決定模型參數。舉例來講,我們可以理解“高興”與“開心”是兩個語義相近的詞,所以句子中可以使用“高興”的位置,使用“開心”來代替也常常是可行的。但是,假如我們用于訓練n-gram語言模型的訓練語料中只有出現“高興”而沒有出現“開心”,則對于“我今天很高興”這句話會給出較高成句概率,而對于“我今天很開心”則無法給出高的成句概率。
可見,傳統n-gram語言模型對訓練語料的需求量很大,且一些時候效果不盡如人意。
技術實現要素:
本發明提供了一種語言模型優化方法及裝置,以解決現有技術中的語言模型中成句概率低的問題。
為了解決上述問題,本發明公開了一種語言模型優化方法,所述方法包括:從訓練的語料中獲取第一詞向量以及第二詞向量,其中,所述第一詞向量為第一詞語的向量,所述第二詞向量為第二詞語的向量,所述第二詞語在語料中出現的概率低于所述第一詞語在語料中出現的概率,且所述第一詞語與所述第二詞語語義相近;計算所述第一詞向量與所述第二詞向量夾角的余弦值;獲取語言模型中第一詞語組的出現概率對數;其中,所述第一詞語組為第一詞語與第三詞語組合;將所述第二詞語與所述第三詞語進行組合,生成第二詞語組;依據所述第一詞語組的出現概率對數以及所述夾角的余弦值,計算所述第二詞語組的出現概率對數;將所述第二詞語組與所述第二詞語組的出現概率對數對應添加至語言模型中。
優選地,所述計算所述第一詞向量與所述第二詞向量夾角的余弦值的步驟包括:通過以下公式對第一詞向量以及第二詞向量夾角的余弦值進行計算:cosa=<b,c>/|b||c|,其中a為第一詞向量與所述第二詞向量的夾角,b為第一詞向量,c為第二詞向量。
優選地,所述依據所述第一詞語組的出現概率對數以及所述夾角的余弦值,計算所述第二詞語組的出現概率對數的步驟包括:依據所述第一詞語組的出現概率對數計算出第一詞語組的出現概率;將所述第一詞語組的出現概率,與第一詞向量以及第二詞向量夾角的余弦值相乘,計算所述第二詞語組的出現概率;依據所述第二詞語組的出現概率計算所述第二詞語組的出現概率對數。
優選地,在所述從訓練的語料中獲取第一詞向量以及第二詞向量的步驟之前,所述方法還包括:對語料進行訓練,生成詞向量以及語言模型,其中,所述語言模型中包含多個詞語、各詞語的出現概率對數、多個詞語組以及各詞語組的出現概率對數,所述詞向量為各所述詞語對應的向量。
優選地,所述余弦值的范圍值為(0-1)。
為了解決上述問題,本發明還公開了一種語言模型優化裝置,所述裝置包括:第一獲取模塊,用于從從訓練的語料中獲取第一詞向量以及第二詞向量,其中,所述第一詞向量為第一詞語的向量,所述第二詞向量為第二詞語的向量,所述第二詞語在語料出現的概率低于所述第一詞語在語料中出現的概率,且所述第一詞語與所述第二詞語語義相近;第一計算模塊,用于計算所述第一詞向量與所述第二詞向量夾角的余弦值;第二獲取模塊,用于獲取語言模型中第一詞語組的出現概率對數;其中,所述第一詞語組為第一詞語與第三詞語組合;第一生成模塊,用于將所述第二詞語與所述第三詞語進行組合,生成第二詞語組;第二計算模塊,用于依據所述第一詞語組的出現概率對數以及所述夾角的余弦值,計算所述第二詞語組的出現概率對數;添加模塊,用于將所述第二詞語組與所述第二詞語組的出現概率對數對應添加至所述語言模型中。
優選地,所述第一計算模塊具體用于:通過以下公式對第一詞向量以及第二詞向量夾角的余弦值進行計算:cosa=<b,c>/|b||c|,其中a為第一詞向量與所述第二詞向量的夾角,b為第一詞向量,c為第二詞向量。
優選地,所述第二計算模塊包括:第一計算子模塊,用于依據所述第一詞語組的出現概率對數計算出第一詞語組的出現概率;第二計算子模塊,用于將所述第一詞語組的出現概率,與第一詞向量以及第二詞向量夾角的余弦值相乘,計算所述第二詞語組的出現概率;第三計算子模塊,用于依據所述第二詞語組的出現概率計算所述第二詞語組的出現概率對數。
優選地,所述裝置還包括:訓練模塊,用于在所述第一獲取模塊從訓練的語料中獲取第一詞向量以及第二詞向量之前,對語料進行訓練,生成詞向量以及語言模型,其中,所述語言模型中包含多個詞語、各詞語的出現概率對數、多個詞語組以及各詞語組的出現概率對數,所述詞向量為各所述詞語對應的向量。
優選地,所述余弦值的范圍值為(0-1)。
與現有技術相比,本發明具有以下優點:
本發明實施例提供的一種語言模型優化方案,從訓練的語料中獲取第一詞向量以及第二詞向量,其中,第一詞向量為第一詞語的向量,第二詞向量為第二詞語的向量,第二詞語在語料出現的概率低于第一詞語在語料中出現的概率,且第一詞語與第二詞語語義相近;計算第一詞向量與第二詞向量夾角的余弦值;獲取語言模型中第一詞語組的出現概率對數;其中,第一詞語組為第一詞語與第三詞語組合;將第二詞語與第三詞語進行組合,生成第二詞語組;依據第一詞語組的出現概率對數以及夾角的余弦值,計算第二詞語組的出現概率對數;將第二詞語組與第二詞語組的出現概率對數對應添加至語言模型中。可見,通過本發明提供的語言模型優化方案,用一份分好詞的語料進行訓練可以同時得到語言模型和詞向量。詞向量可以提供兩個詞之間的相似度信息,利用這一信息對n-gram語言模型中的條件概率進行調整,達到優化語言模型的效果,提升用戶的使用體驗。
附圖說明
圖1是本發明實施例一的一種語言模型優化方法的步驟流程圖;
圖2是本發明實施例二的一種語言模型優化方法的步驟流程圖;
圖3是本發明實施例三的一種語言模型優化裝置的結構框圖;
圖4是本發明實施例四的一種語言模型優化裝置的結構框圖。
具體實施方式
為使本發明的上述目的、特征和優點能夠更加明顯易懂,下面結合附圖和具體實施方式對本發明作進一步詳細的說明。
實施例一
參照圖1,示出了本發明實施例一的一種語言模型優化方法的步驟流程圖。
本發明實施例提供的語言模型優化方法包括以下步驟:
步驟101:從從訓練的語料中獲取第一詞向量以及第二詞向量。
其中,第一詞向量為第一詞語的向量,第二詞向量為第二詞語的向量,第二詞語在語料出現的概率低于第一詞語在語料中出現的概率,第一詞語與第二詞語的語義相近。
步驟102:計算第一詞向量與第二詞向量夾角的余弦值。
根據獲取的詞向量,可以利用兩個向量夾角余弦值公式進行計算。
目前常用的方法為,采用分散式標識方法將每個詞標識為一種低維實數向量,該向量就是詞語對應的詞向量。
步驟103:獲取語言模型中第一詞語組的出現概率對數。
例如:第一詞語組為“今天天氣”,在語言模型中獲取“今天天氣”的出現概率對數。
在語言模型中會有一條路徑為:
-0.1760913今天天氣,表示今天天氣出現概率的對數。
通過上述路徑可知,今天天氣的出現概率對數為-0.1760913。
其中,第一詞語組為第一詞語與第三詞語組合。
需要說明的是,本申請中的語言模型特指為n-gram語言模型。
步驟104:將第二詞語與第三詞語進行組合,生成第二詞語組。
步驟105:依據第一詞語組的出現概率對數以及夾角的余弦值,計算第二詞語組的出現概率對數。
步驟106:將第二詞語組與第二詞語組的出現概率對數對應添加至語言模型中。
將第二詞組的出現概率對數添加至語言模型中,當進行語音識別時,提高成句概率。
本發明實施例提供的一種語言模型優化方法,從訓練的語料中獲取第一詞向量以及第二詞向量,其中,第一詞向量為第一詞語的向量,第二詞向量為第二詞語的向量,第二詞語在語料出現的概率低于第一詞語在語料中出現的概率,且第一詞語與第二詞語語義相近;計算第一詞向量與第二詞向量夾角的余弦值;獲取語言模型中第一詞語組的出現概率對數;其中,第一詞語組為第一詞語與第三詞語組合;將第二詞語與第三詞語進行組合,生成第二詞語組;依據第一詞語組的出現概率對數以及夾角的余弦值,計算第二詞語組的出現概率對數;將第二詞語組與第二詞語組的出現概率對數對應添加至語言模型中。可見,通過本發明提供的語言模型優化方法,用一份分好詞的語料進行訓練可以同時得到語言模型和詞向量。詞向量可以提供兩個詞之間的相似度信息。利用這一信息對n-gram語言模型中的條件概率進行調整,達到優化語言模型的效果,提升用戶的使用體驗。
實施例二
參照圖2,示出了本發明實施例二的一種語言模型優化方法的步驟流程圖。
本發明實施例提供的語言模型優化方法包括以下步驟:
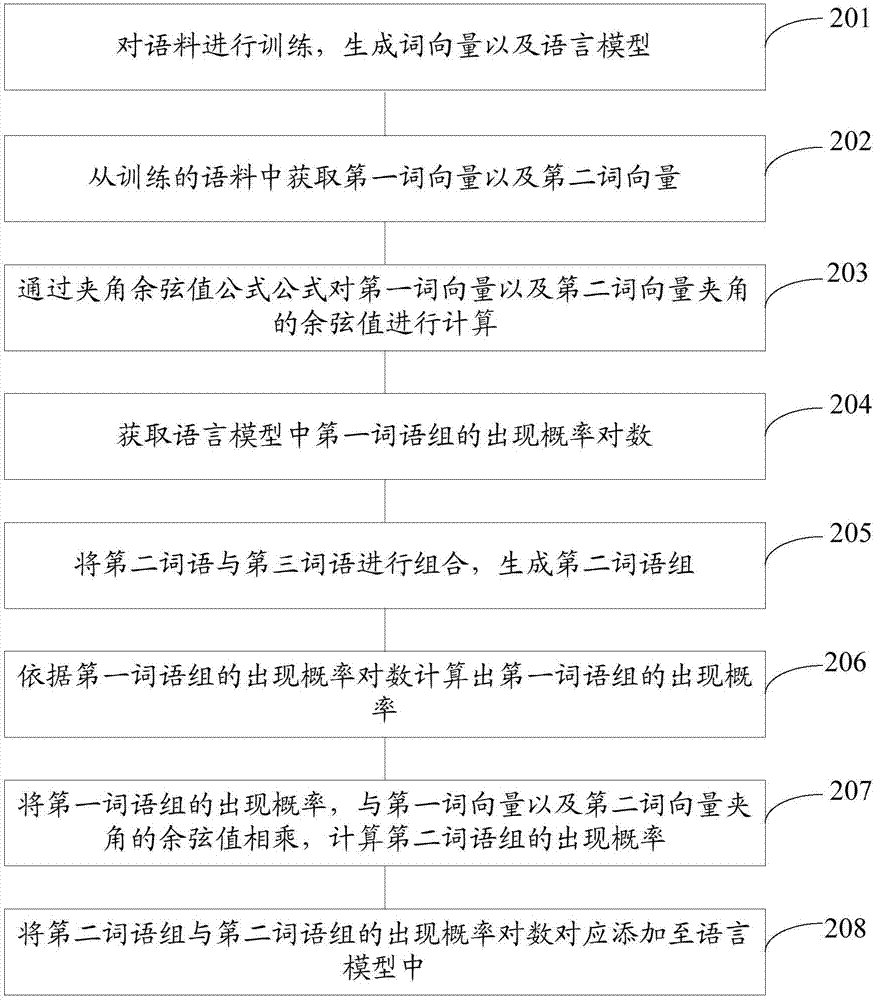
步驟201:對語料進行訓練,生成詞向量以及語言模型。
其中,語言模型中包含多個詞語、各詞語的出現概率對數、多個詞語組以及各詞語組的出現概率對數,詞向量為各詞語對應的向量。。
步驟202:從訓練的語料中獲取第一詞向量以及第二詞向量。
其中,第一詞向量為第一詞語的向量,第二詞向量為第二詞語的向量,第二詞語在語料出現的概率低于第一詞語在語料中出現的概率,且第一詞語與第二詞語語義相近。
步驟203:通過以下公式對第一詞向量以及第二詞向量夾角的余弦值進行計算:
cosa=<b,c>/|b||c|,其中a為第一詞向量與第二詞向量的夾角,b為第一詞向量,c為第二詞向量。
根據獲取的詞向量,可以利用兩個向量夾角余弦值公式進行計算。
目前常用的方法為,采用分散式標識方法將每個詞標識為一種低維實數向量,該向量就是詞語對應的詞向量。
步驟204:獲取語言模型中第一詞語組的出現概率對數。
其中,第一詞語組為第一詞語與第三詞語組合。
例如:第一詞語組為“今天天氣”,在語言模型中獲取“今天天氣”的出現概率對數。
在語言模型中會有一條路徑為:
-0.1760913今天天氣,表示今天天氣出現概率的對數。
通過上述路徑可知,今天天氣的出現概率對數為-0.1760913。
步驟205:將第二詞語與第三詞語進行組合,生成第二詞語組。
例如,第二詞語和第三詞語分別為“明天”、“天氣”,則第二詞語組為“明天天氣”。
步驟206:依據第一詞語組的出現概率對數計算出第一詞語組的出現概率。
例如:獲取的第一詞組的出現概率對數為“今天天氣”對應的出現概率對數,且“今天天氣”的出現概率對數為-0.1760913,其小數值為10^(-0.1760913)約為0.667,則“今天天氣的出現概率為0.667。
步驟207:將第一詞語組的出現概率,與第一詞向量以及第二詞向量夾角的余弦值相乘,計算第二詞語組的出現概率。
例如:“明天天氣”這個二元組的條件概率為0.78423*0.6667與等于0.5228。
對0.5228進行對數計算,則“明天天氣”的出現概率對數為-0.28166。步驟209:依據第二詞語組的出現概率計算第二詞語組的出現概率對數。
步驟208:將第二詞語組與第二詞語組的出現概率對數對應添加至語言模型中。
在語言模型中添加“-0.28166明天天氣”,其中-0.28166為0.5228以十為底的對數。
這樣一來,即使訓練語料中沒有出現過“明天”這個詞,對它在句子中可能出現的概率也有一個較好的估計。依照需要,對所有語料中未出現而關心的詞做這樣的概率補充。這樣修改后的語言模型在各類任務中都會具有更優秀的使用價值。
本發明實施例提供的一種語言模型優化方法,從訓練的語料中獲取第一詞向量以及第二詞向量,其中,第一詞向量為第一詞語的向量,第二詞向量為第二詞語的向量,第二詞語在語料出現的概率低于第一詞語在語料中出現的概率,且第一詞語與第二詞語語義相近;計算第一詞向量與第二詞向量夾角的余弦值;獲取語言模型中第一詞語組的出現概率對數;其中,第一詞語組為第一詞語與第三詞語組合;將第二詞語與第三詞語進行組合,生成第二詞語組;依據第一詞語組的出現概率對數以及夾角的余弦值,計算第二詞語組的出現概率對數;將第二詞語組與第二詞語組的出現概率對數對應添加至語言模型中。可見,通過本發明提供的語言模型優化方法,用一份分好詞的語料進行訓練可以同時得到語言模型和詞向量。詞向量可以提供兩個詞之間的相似度信息。利用這一信息對n-gram語言模型中的條件概率進行調整,達到優化語言模型的效果,提升用戶的使用體驗。
實施例三
參照圖3,示出了本發明實施例三的一種語言模型優化裝置的結構框圖。
本發明實施例提供的語言模型優化裝置包括:第一獲取模塊301,用于從訓練的語料中獲取第一詞向量以及第二詞向量,其中,所述第一詞向量為第一詞語的向量,所述第二詞向量為第二詞語的向量,所述第二詞語在語料出現的概率低于所述第一詞語在語料中出現的概率,且所述第一詞語與所述第二詞語語義相近;第一計算模塊302,用于計算所述第一詞向量與所述第二詞向量夾角的余弦值;第二獲取模塊303,用于獲取所述語言模型中第一詞語組的出現概率對數;其中,所述第一詞語組為第一詞語與第三詞語組合;第一生成模塊304,用于將所述第二詞語與所述第三詞語進行組合,生成第二詞語組;第二計算模塊305,用于依據所述第一詞語組的出現概率對數以及所述夾角的余弦值,計算所述第二詞語組的出現概率對數;添加模塊306,用于將所述第二詞語組與所述第二詞語組的出現概率對數對應添加至所述語言模型中。
本發明實施例提供的一種語言模型優化裝置,從訓練的語料中獲取第一詞向量以及第二詞向量,其中,第一詞向量為第一詞語的向量,第二詞向量為第二詞語的向量,第二詞語在語料出現的概率低于第一詞語在語料中出現的概率,且第一詞語與第二詞語語義相近;計算第一詞向量與第二詞向量夾角的余弦值;獲取語言模型中第一詞語組的出現概率對數;其中,第一詞語組為第一詞語與第三詞語組合;將第二詞語與第三詞語進行組合,生成第二詞語組;依據第一詞語組的出現概率對數以及夾角的余弦值,計算第二詞語組的出現概率對數;將第二詞語組與第二詞語組的出現概率對數對應添加至語言模型中。可見,通過本發明提供的語言模型優化裝置,用一份分好詞的語料進行訓練可以同時得到語言模型和詞向量。詞向量可以提供兩個詞之間的相似度信息。利用這一信息對n-gram語言模型中的條件概率進行調整,達到優化語言模型的效果,提升用戶的使用體驗。
實施例四
參照圖4,示出了本發明實施例四的一種語言模型優化裝置的結構框圖。
本發明實施例提供的語言模型優化裝置包括:第一獲取模塊401,用于從訓練的語料中獲取第一詞向量以及第二詞向量,其中,所述第一詞向量為第一詞語的向量,所述第二詞向量為第二詞語的向量,所述第二詞語在語料出現的概率低于所述第一詞語在語料中出現的概率,且所述第一詞語與所述第二詞語語義相近;第一計算模塊402,用于計算所述第一詞向量與所述第二詞向量夾角的余弦值;第二獲取模塊403,用于獲取所述語言模型中第一詞語組的出現概率對數;其中,所述第一詞語組為第一詞語與第三詞語組合;第一生成模塊404,用于將所述第二詞語與所述第三詞語進行組合,生成第二詞語組;第二計算模塊405,用于依據所述第一詞語組的出現概率對數以及所述夾角的余弦值,計算所述第二詞語組的出現概率對數;添加模塊406,用于將所述第二詞語組與所述第二詞語組的出現概率對數對應添加至所述語言模型中。
優選地,所述第一計算模塊402具體用于:通過以下公式對第一詞向量以及第二詞向量夾角的余弦值進行計算:cosa=<b,c>/|b||c|,其中a為第一詞向量與所述第二詞向量的夾角,b為第一詞向量,c為第二詞向量。
優選地,所述第二計算模塊405包括:第一計算子模塊4051,用于依據所述第一詞語組的出現概率對數計算出第一詞語組的出現概率;第二計算子模塊4052,用于將所述第一詞語組的出現概率,與第一詞向量以及第二詞向量夾角的余弦值相乘,計算所述第二詞語組的出現概率;第三計算子模塊4053,用于依據所述第二詞語組的出現概率計算所述第二詞語組的出現概率對數。
優選地,所述裝置還包括:訓練模塊407,用于在所述第一獲取模塊從訓練的語料中獲取第一詞向量以及第二詞向量之前,對語料進行訓練,生成詞向量以及語言模型,其中,所述語言模型中包含多個詞語、各詞語的出現概率對數、多個詞語組以及各詞語組的出現概率對數,所述詞向量為各所述詞語對應的向量。
優選地,所述余弦值的范圍值為(0-1)。
本發明實施例提供的一種語言模型優化裝置,從訓練的語料中獲取第一詞向量以及第二詞向量,其中,第一詞向量為第一詞語的向量,第二詞向量為第二詞語的向量,第二詞語在語料出現的概率低于第一詞語在語料中出現的概率,且第一詞語與第二詞語的語義相近;計算第一詞向量與第二詞向量夾角的余弦值;獲取語言模型中第一詞語組的出現概率對數;其中,第一詞語組為第一詞語與第三詞語組合;將第二詞語與第三詞語進行組合,生成第二詞語組;依據第一詞語組的出現概率對數以及夾角的余弦值,計算第二詞語組的出現概率對數;將第二詞語組與第二詞語組的出現概率對數對應添加至語言模型中。可見,通過本發明提供的語言模型優化裝置,用一份分好詞的語料進行訓練可以同時得到語言模型和詞向量。詞向量可以提供兩個詞之間的相似度信息。利用這一信息對n-gram語言模型中的條件概率進行調整,達到優化語言模型的效果,提升用戶的使用體驗。
本說明書中的各個實施例均采用遞進的方式描述,每個實施例重點說明的都是與其他實施例的不同之處,各個實施例之間相同相似的部分互相參見即可。對于系統實施例而言,由于其與方法實施例基本相似,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
以上對本發明所提供的一種語言模型優化方法及裝置,進行了詳細介紹,本文中應用了具體個例對本發明的原理及實施方式進行了闡述,以上實施例的說明只是用于幫助理解本發明的方法及其核心思想;同時,對于本領域的一般技術人員,依據本發明的思想,在具體實施方式及應用范圍上均會有改變之處,綜上所述,本說明書內容不應理解為對本發明的限制。
- 還沒有人留言評論。精彩留言會獲得點贊!