一種語音模型壓縮方法、電子設備及存儲介質
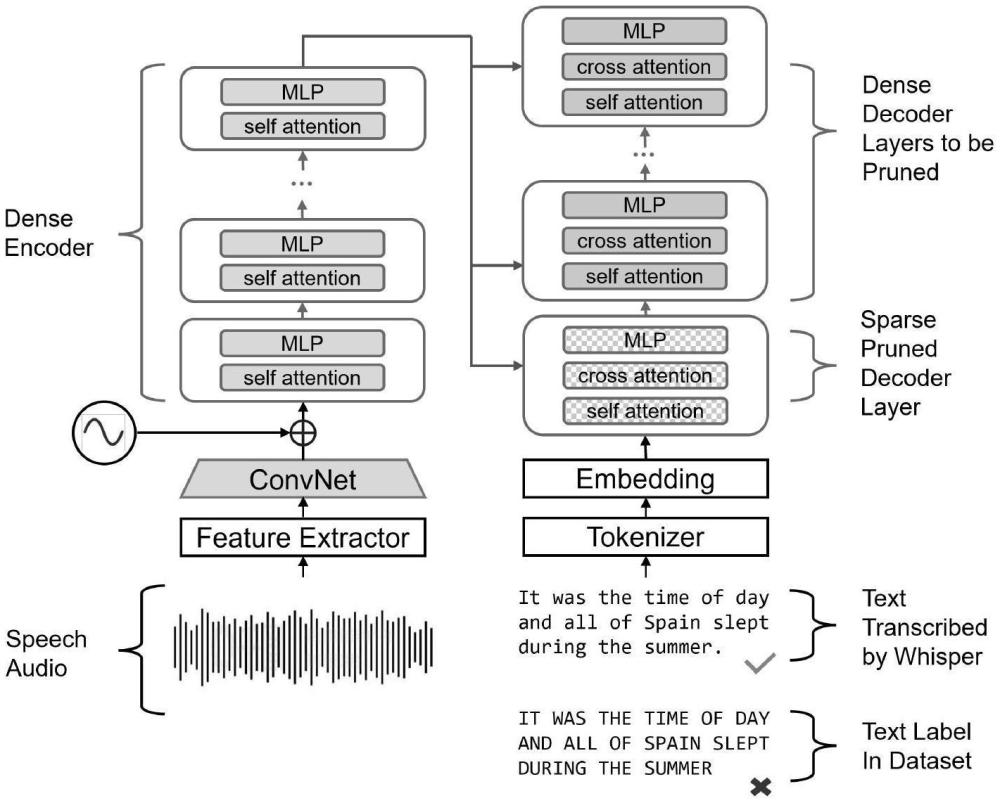
本發明主要涉及人工智能領域,尤其涉及一種僅需要前向傳播的基于混合稀疏度層級剪枝的大規模序列到序列語音識別模型壓縮方法、電子設備及存儲介質。
背景技術:
1、近年來,大規模序列到序列(seq2seq)語音識別模型如whisper因其卓越的語音識別性能而備受關注。這些模型具備復雜的編碼器-解碼器架構和大規模參數,通過對海量多樣化語音數據的訓練,能夠應對多種方言、口音及嘈雜環境。然而,其龐大的參數量帶來了高昂的計算開銷,使得該類模型難以部署在計算資源有限的設備上,限制了其廣泛應用。為了解決此問題,模型壓縮技術成為研究熱點,其中剪枝方法因能夠有效減少模型參數及推理開銷而受到廣泛應用。
2、然而,當前的剪枝方法主要應用于中等規模、僅含編碼器的自監督語音模型,難以直接應用于具有編碼器-解碼器架構的超大規模序列到序列語音識別模型,因為這些方法通常需要大量內存用于計算海森矩陣或在原始數據集上重新訓練,帶來了額外的資源需求和技術難題。
技術實現思路
1、有鑒于現有技術的上述缺陷,本發明所要解決的技術問題包括:
2、如何設計一種語音模型壓縮方法,從而克服上述技術問題。
3、為實現上述目的,本發明提供了一種語音識別模型壓縮方法,通過層級剪枝減少語音識別模型的參數;通過基于前向傳播的混合稀疏分配方法優化所述層級剪枝的效果;所述通過層級剪枝減少語音識別模型的參數包括編碼器剪枝和解碼器剪枝;所述通過基于前向傳播的混合稀疏分配方法優化所述層級剪枝的效果包括權重矩陣分組和重建誤差控制。
4、進一步地,所述解碼器剪枝為:通過校準數據集對解碼器進行逐層剪枝,并生成用于剪枝的校準特征;所述編碼器剪枝為:在解碼器剪枝后,再對模型的編碼器部分進行逐層剪枝。
5、進一步地,所述解碼器剪枝具體為:
6、將語音識別模型自身生成的轉錄文本用作文本模態的校準數據集,以保留模型原有的語義信息和格式;
7、對于音頻模態校準數據集,使用編碼器輸出的稠密特征作為輸入;
8、按層對解碼器中的自注意力、交叉注意力和前饋網絡進行剪枝,每次剪枝后記錄各層的重建誤差。
9、進一步地,所述編碼器剪枝具體為:
10、使用來自開源數據集的語音波形作為編碼器的校準數據集,以獲取真實數據的特征響應;
11、記錄重建誤差并控制誤差范圍,確保模型的音頻特征提取能力不會受到影響;
12、編碼器中的各層都被逐層處理,通過前向傳播僅記錄重建誤差,無需梯度計算。
13、進一步地,所述權重矩陣分組為:將模型中各層的權重矩陣按照功能分為多個組,包括自注意力層的鍵、查詢和值投影矩陣,交叉注意力層的投影矩陣,以及各層的前饋網絡權重;所述重建誤差控制為:對每組權重矩陣在不同稀疏度條件下進行前向傳播計算,以控制重建誤差。
14、進一步地,所述權重矩陣分組具體為:將編碼器和解碼器中的各權重矩陣分為八組;根據每個權重矩陣的重要性確定適合的稀疏度,使得不同組的稀疏度靈活可調。
15、進一步地,所述重建誤差控制具體為:
16、利用前向傳播計算不同稀疏條件下的重建誤差,以此作為判斷該稀疏度下參數保留程度的指標;
17、針對每個權重矩陣設置重建誤差閾值,并從候選稀疏度中選擇最大稀疏度配置,以保證重建誤差在閾值內;
18、對各組權重矩陣設定統一的閾值,從而簡化稀疏度選擇的復雜度。
19、一種電子設備,包括:
20、至少一個處理器;以及
21、與所述至少一個處理器通信連接的存儲器;其中,
22、所述存儲器存儲有可被所述至少一個處理器執行的指令,所述指令被所述至少一個處理器執行,以使所述至少一個處理器能夠前述的方法。
23、一種存儲有計算機指令的非瞬時計算機可讀存儲介質,其中,所述計算機指令用于使所述計算機執行前述的方法。
24、一種計算機程序產品,包括計算機程序,所述計算機程序在被處理器執行時實現前述的方法。
25、與現有技術方案相比,本發明的技術效果在于:
26、本發明提出了一種無需反向傳播的層級剪枝方法,專為具有編碼器-解碼器架構的大規模序列到序列語音識別模型設計。該方法通過依次剪枝解碼器和編碼器,避免了繁重的反向傳播計算。該方法能在無反向傳播或重訓練的情況下,將whisper-large模型的參數減少約60%,且對模型在各種數據集上的表現幾乎沒有影響。同時,該方法適用于多語言數據集,剪枝后模型在多語言能力上保持了良好的魯棒性和泛化性。此創新極大降低了大規模模型部署的門檻,使其在資源受限的環境中更易應用。
27、本發明提出了一種僅需要前向傳播的混合稀疏分配策略,通過對權重矩陣中重要參數的優化保留,使稀疏分配更加靈活有效,進一步提高模型的壓縮效率。該方法僅通過前向傳播便可完成模型的稀疏優化,避免了額外的重訓練過程。實驗表明,在60%稀疏條件下,該方法比傳統均勻稀疏剪枝在多項測試集上表現更優,尤其在稀疏度較高時能有效減少模型性能的下降。
28、以下將結合附圖對本發明的構思、具體結構及產生的技術效果作進一步說明,以充分地了解本發明的目的、特征和效果。
技術特征:
1.一種語音識別模型壓縮方法,其特征在于,通過層級剪枝減少語音識別模型的參數;通過基于前向傳播的混合稀疏分配方法優化所述層級剪枝的效果;所述通過層級剪枝減少語音識別模型的參數包括編碼器剪枝和解碼器剪枝;所述通過基于前向傳播的混合稀疏分配方法優化所述層級剪枝的效果包括權重矩陣分組和重建誤差控制。
2.根據權利要求1所述的語音識別模型壓縮方法,其特征在于,所述解碼器剪枝為:通過校準數據集對解碼器進行逐層剪枝,并生成用于剪枝的校準特征;所述編碼器剪枝為:在解碼器剪枝后,再對模型的編碼器部分進行逐層剪枝。
3.根據權利要求2所述的語音識別模型的壓縮方法,其特征在于,所述解碼器剪枝具體為:
4.根據權利要求2所述的語音識別模型壓縮方法,其特征在于,所述編碼器剪枝具體為:
5.根據權利要求1所述的語音識別模型壓縮方法,其特征在于,所述權重矩陣分組為:將模型中各層的權重矩陣按照功能分為多個組,包括自注意力層的鍵、查詢和值投影矩陣,交叉注意力層的投影矩陣,以及各層的前饋網絡權重;所述重建誤差控制為:對每組權重矩陣在不同稀疏度條件下進行前向傳播計算,以控制重建誤差。
6.根據權利要求5所述的語音識別模型壓縮方法,其特征在于,所述權重矩陣分組具體為:將編碼器和解碼器中的各權重矩陣分為八組;根據每個權重矩陣的重要性確定適合的稀疏度,使得不同組的稀疏度靈活可調。
7.根據權利要求5所述的語音識別模型壓縮方法,其特征在于,所述重建誤差控制具體為:
8.一種電子設備,包括:
9.一種存儲有計算機指令的非瞬時計算機可讀存儲介質,其中,所述計算機指令用于使所述計算機執行根據權利要求1-7中任一項所述的方法。
10.一種計算機程序產品,包括計算機程序,所述計算機程序在被處理器執行時實現根據權利要求1-7中任一項所述的方法。
技術總結
本發明公開了一種語音模型壓縮方法、電子設備及存儲介質。本發明專為具有編碼器?解碼器架構的大規模序列到序列語音識別模型設計。該方法通過依次剪枝解碼器和編碼器,避免了繁重的反向傳播計算。該方法能在無反向傳播或重訓練的情況下,將Whisper?large模型的參數減少約60%,且對模型在各種數據集上的表現幾乎沒有影響。同時,該方法適用于多語言數據集,剪枝后模型在多語言能力上保持了良好的魯棒性和泛化性。此創新極大降低了大規模模型部署的門檻,使其在資源受限的環境中更易應用。
技術研發人員:錢彥旻,顧天騰
受保護的技術使用者:上海交通大學
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!