用于室內掛鐘設計的模糊適應值交互式進化優化方法與流程
本發明屬于掛鐘設計領域,貼別是涉及一種用于室內掛鐘設計的交互式進化優化方法,可用于引導用戶進行室內掛鐘外觀方案的設計。
背景技術:
室內掛鐘是重要的生活家居類產品,除了計時功能外,它還是一道空間裝飾。好的掛鐘外觀設計不僅能給人視覺享受,還對家居氛圍起到烘托作用。由于室內掛鐘外觀設計元素豐富,藝術性較強,無法采用定量的目標函數衡量評價方案,而基于交互式進化方法可以增強用戶搜索能力,啟發用戶設計靈感,幫助用戶找到滿意的設計方案。
目前,已經公布的應用交互式進化優化方法進行產品外觀設計策略大致分為兩種類型。其一是可以采用多種形式的個體適應值機器賦值,改善人機交互環境:如中國發明專利“用于窗簾設計的交互式進化優化方法”(公開號:cn10263249a,公開日:2011.08.24)給出的多集勢模糊評價、精確值評價與自動評價;2009年出版的會議論文“classificationandregression-basedsurrogatemodel-assistedinteractivegeneticalgorithmwithindividual’sfuzzyfitness”將支持向量機代理模型用于計算個體模糊適應值;2011年出版的期刊《appliedsoftcomputing》第11期“largepopulationsizeigawithindividuals’fitnessnotassignedbyuser”將非用戶賦適應值也用于大規模種群進化。上述大規模種群個體適應值賦值方法,擴展了用戶評價個體適應值的能力,但尚存在如下問題:首先,上述方法對用戶評價過程的疲勞問題考慮不夠,為獲得區間適應值和模糊適應值,用戶仍需增加操作量;其次,受評價方法限制,代理模型只能逼近有限數量的語氣詞,對偏好表達仍然不足;而對非用戶賦適應值的估計,則模型誤差較大。其二是對個體適應值進行機器估計:如2010年出版的期刊《控制理論與應用》第6期“混合性能指標優化問題的大種群規模進化算法”按個體基因型相似性采用k-均值對種群劃分計算適應值;2015年出版的期刊《控制與決策》第7期“基于cp-nets的偏好感知交互式遺傳算法及其個性化搜索”采用代理模型進行適應值估計。上述個體適應值估計方法為大規模種群的進化提供了導向,但是尚存在如下問題:首先,這些適應值估計方法需要個體的距離或者個體基因模式的可分性作為估計的依據,但是通常交互式遺傳算法中適應值函數是未知的,而且對于搜索空間較復雜的情況很難確定個體基因型和表現型之間的映射關系,基因型的微小差別往往會導致表現型的明顯差異,所以基于基因距離的適應值估計與個體表現型存在誤差。其次,采用代理模型方法估計適應值提高了算法優化效率,但個體相似度的計算仍基于基因型,所以模型誤差依然存在。這說明,發明新的個體適應值估計方法是非常必要的。
技術實現要素:
本發明所要解決的技術問題是:克服現有技術的不足,提供一種減少設計人員負擔、增強算法的搜索能力且提高進化優化質量的用于室內掛鐘設計的模糊適應值交互式進化優化方法。
本發明的技術方案是:
一種用于室內掛鐘設計的模糊適應值交互式進化優化方法,采用大規模進化種群和個體模糊適應值估計策略的交互式遺傳算法作為優化算法,它包括參數設置界面、交互界面和結果輸出界面,系統劃分為載入模塊、處理模塊和交互式遺傳算法模塊三個功能模塊,三個功能模塊通過一個交互界面融合為整體,共同完成交互式進化設計;室內掛鐘各屬性樣本以.bmp格式儲存在數據庫中,載入模塊將掛鐘屬性模型文件讀入內存并在窗口界面中顯示;處理模塊實現對模型的貼圖,時針與分針統一固定在10:10;交互式遺傳算法模塊則將交互式遺傳算法整合到系統中。系統運行時,用戶首先設置遺傳參數,進入交互界面后點擊“初始化”按鈕,系統初始化并運行載入模塊和處理模塊,生成6個樣本,用戶通過樣本下方滑動條對個體進行單一數值評價,系統在后臺實現大規模種群個體模糊適應值估計;
該優化算法具體實現為:
(1)根據用戶評價時間與單一數值適應值估計用戶評價個體模糊適應值
式中,d(ci(t))表示
(2)根據個體表現型屬性與參照個體模糊適應值寬度計算個體表現型相似度:
式中,σ(xj(t))是參照個體xj(t)的模糊適應值寬度。
則xi(t)與xj(t)的表現型相似度為μij(xir)的平均值,記為μ(xi(t),xj(t)):
(3)利用個體表現型相似度對種群聚類并估計未評價個體模糊適應值:
剩余個體xj(t)的模糊適應值中心值d(xj(t))計算公式為:
式中,k是個體表現型相似度μ(xj(t),ci(t))最大值大于閾值θ(t)時的聚類中心:
閾值θ(t)由前一代個體適應值中心值刻劃:
式中,α是反映評價性能的參數。可以看出,閾值θ(t)隨進化代內最大適應值增加而增加,利用前一進化代的信息計算閾值,可以為下一代估計d(xj(t))提供依據;
(4)基于個體模糊適應值和表現型相似性構造個體選擇適應值,實現個體相似性選擇。
比較個體為xa(t),xb(t),則個體選擇適應值分別為f(xa(t)),f(xb(t)):
f(xa(t))=d(xa(t))·μ(xb(t),xa(t))
f(xb(t))=d(xb(t))·μ(xa(t),xb(t))
式中,d(xa(t)),d(xb(t))分別是個體xa(t),xb(t)的模糊適應值中心值;μ(xa(t),xb(t)),μ(xb(t),xa(t))分別是以個體xb(t)和xa(t)為參照個體,以xa(t)和xb(t)為比較個體的相似度。
優選地:將t(ci(t))與當前進化代內個體最長評價時間比值作為個體ci(t)的滿意度,記為hi:
個體ci(t)的模糊適應值
式中,d(ci(t))是用戶對個體ci(t)的評價值。
優選地:記第t-1代用戶評價值最高個體為xb(t-1),當前代t的個體cp(t),p=1,2,…,n與xb(t-1)的相似度為:
用戶評價個體數目nc:
nc的意義是依據相似度的數值大小,選擇最靠前的nc個個體推薦給用戶評價。
本發明的優點和積極效果是:
1、本發明有效降低設計人員的操作負擔,設計人員只需按單一數值評價少量產品款式即可,系統在后臺自動實現用戶評價個體模糊適應值估計。與傳統模糊適應值賦值相比,不需要輸入語氣詞,節省了一半的操作量。
2、本發明提出了一套完整的室內掛鐘外觀樣本生成、交互及進化設計方法,其特點在于采用了大規模進化種群的個體模糊適應值估計策略的交互式遺傳算法,根據用戶評價時間與單一數值適應值估計用戶評價個體模糊適應值;根據個體表現型屬性與參照個體模糊適應值寬度計算個體表現型相似度;利用個體表現型相似度對種群聚類并估計未評價個體模糊適應值;基于個體模糊適應值和表現型相似性構造個體選擇適應值,實現個體相似性選擇;與同類方法比較,本發明的設計結果明顯占有優勢。
3、本發明通過大規模種群進化,增強了算法的搜索能力;能夠對所有個體實現模糊適應值賦值,偏好信息量更加豐富,個體評價更準確,提高了進化優化質量。
附圖說明
圖1為本發明的總體流程圖;
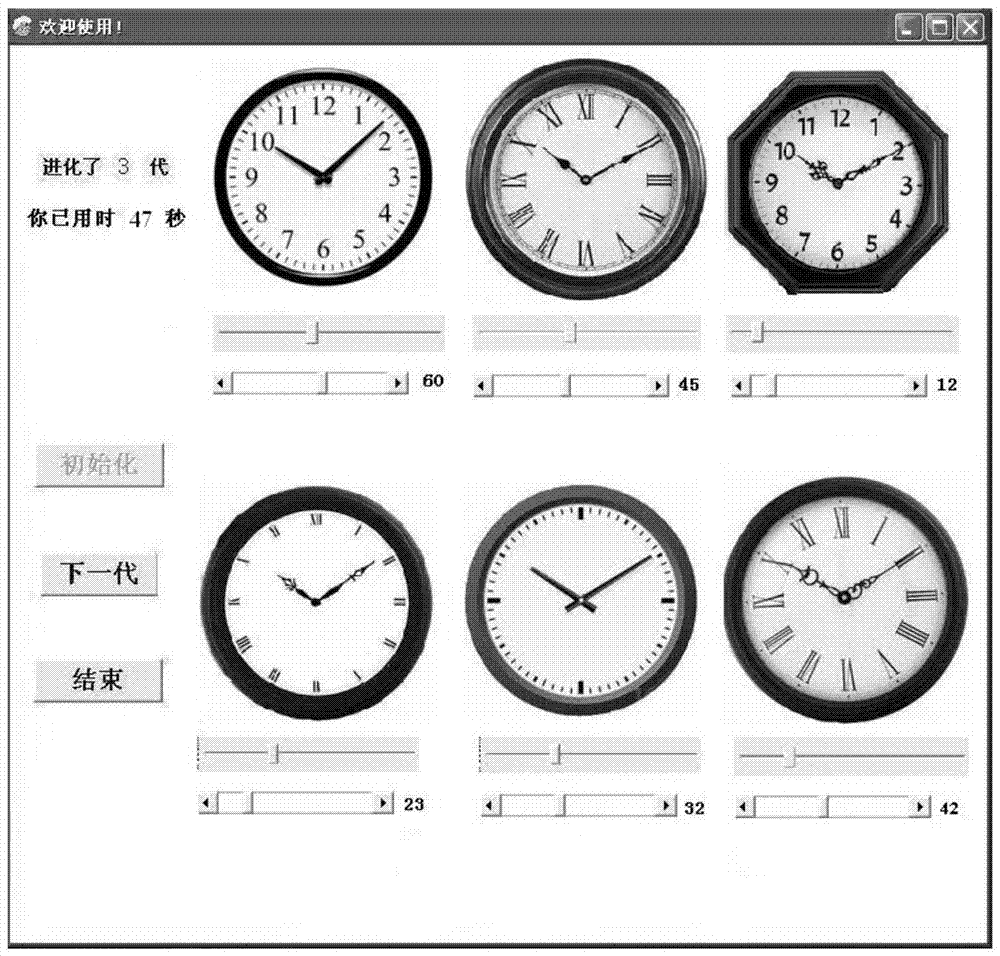
圖2為本發明的系統交互界面圖。
具體實施方式
參照附圖,對本發明實施做以下進一步詳述,以下實施例只是描述性的,不是限定性的,不能以此限定本發明的保護范圍。
一種用于室內掛鐘設計的模糊適應值交互式進化優化方法流程如圖1所示。其中,斜體字部分為用戶參與遺傳進化過程的交互環節;陰影部分為本發明的創新之處。
該方法的步驟如下:
步驟1.本系統包括參數設置界面、交互界面和結果輸出界面等。系統劃分為載入模塊、處理模塊和交互式遺傳算法模塊等3個功能模塊,三個模塊通過一個交互界面融合為整體,共同完成交互式進化設計。室內掛鐘各屬性樣本以.bmp格式儲存在數據庫中,載入模塊將掛鐘屬性模型文件讀入內存并在窗口界面中顯示;處理模塊實現對模型的貼圖,時針與分針統一固定在10:10;交互式遺傳算法模塊則將交互式遺傳算法整合到系統中。為保證系統整體的運行效率,采用按鈕形式控制算法的執行,系統交互界面如圖2所示。系統運行時,用戶首先設置遺傳參數,進入交互界面后點擊“初始化”按鈕,系統初始化并運行載入模塊和處理模塊,生成6個樣本,用戶通過樣本下方滑動條對個體評價,滑動條的顯示數值即為該個體的模糊適應值中心值,打分范圍為1-100。
步驟2個體相似性計算;
記第t代種群為x(t),種群規模為n,種群x(t)中的第i個個體為xi(t),i=1,2,…,n,則xi(t)的表現型可以表示為
式中,σ(xj(t))是參照個體xj(t)的模糊適應值寬度。
則xi(t)與xj(t)的表現型相似度為μij(xir)的平均值,記為μ(xi(t),xj(t)):
表現型相似度μij(xir)的特點在于:(1)個體屬性間差異越小,μ(xi(t),xj(t))越大,個體表現型就越接近,這符合事物相似性規律;(2)如果參照個體xj(t)的模糊適應值寬度σ(xj(t)越小,μ(xi(t),xj(t))就越小,這與一種評價現象相對應:即將比較個體與參照個體粗略比較時(此時評價準確性低,參照個體xj(t)的模糊適應值寬度大),兩個體相似度較大,然而將比較個體與參照個體仔細比較時(此時評價準確性高,參照個體xj(t)的模糊適應值寬度小),則兩個體相似度較小,反之亦然。(3)更重要地,當參照個體與比較個體互換后,如兩個體的模糊適應值寬度不相等,即σ(xj(t))≠σ(xi(t)),則μ(xi(t),xj(t))≠μ(xj(t),xi(t))。所以,式(5)刻劃的個體表現型相似性特征更符合人的評價規律,于對個體表現型的比較也更恰當。
步驟3.用戶評價個體選擇與種群聚類;
記第t-1代用戶評價值最高個體為xb(t-1),則根據式(2),當前代t的個體cp(t),p=1,2,…,n與xb(t-1)的相似度為:
用戶評價個體數目nc:
該方法特點在于:依據與前代優秀個體相似度排名,利用歷史信息為用戶推薦個體,對于選擇種群內代表性個體更有針對性。
根據個體的相似度可以將種群分成若干類。設x(t)可以被分為nc(t)個類,且nc(t)≤nmaxc(t),其中,nmaxc(t)為第t代種群的最大分類數。具體分類方法:首先,確定一個代表個體xj(t),然后從種群中搜索每一個個體xi(t),(i=1,2,…,n-1),將所有滿足μ(xi(t),xj(t))≥1-min{μij(xir)|r=1,2,…,ng}的個體作為第一類,設為c1(t),即c1(t)={xi(t)|μ(xi(t),xj(t))≥1-min{μij(xir)|r=1,2,…,ng}},xi(t)∈x(t)}。若令c1(t)表示類{c1(t)}的代表個體,可知c1(t)=xi(t)。劃分完第一類后,縮小種群空間,令x(t)←x(t)\{c1(t)},然后從種群中確定另一個個體作為第二類的代表個體,重復如上操作獲得第二類{c2(t)}。類似的,可以對種群x(t)繼續分類,直到x(t)為空,或者nc(t)=nmaxc(t)。當nc(t)=nmaxc(t)-1時,若x(t)中還有未分類的個體,那么把x(t)中的所有個體并為最后一類,而不考慮它們是否相似。完成上述分類過程后,種群x(t)被分為nc(t)個類,分別為{c1(t)},{c2(t)},…,{cnc(t)(t)},它們的代表個體分別為c1(t),c2(t),…,cnc(t)(t)。隨著進化進行,個體間的相似度逐漸增大,聚類中心數目逐漸減少。
步驟4.系統自動記錄用戶對每個個體的評價時間,通過樣本下方滑動塊顯示,該評價時間與用戶評價值在系統后臺用于估計個體模糊適應值;
由于評價的不確定性和認知的模糊性,個體適應值表現形式是一個以評價值為中心的模糊數。記第t代種群的用戶評價進化個體為ci(t),i=1,2,…,nc。其適應值的論域為[fmin,fmax],ci(t)的適應值可表示為
式中,d(ci(t))表示
由于采用了大種群規模進化,用戶只需要評價這些類內代表個體適應值。本發明中
根據研究,人對個體評價時間越長,對該個體的滿意度就越大,個體適應值越大;反之,評價時間越短,對該個體的滿意度就越小,個體適應值越小。另一方面,根據認知常識,人對于滿意度越大和越低的個體評價較為準確,評價不確定較小;而對于滿意度適中的個體,則評價較為困難,評價不確定性較大。針對認知的這種特征,設σ(ci(t))取值范圍為[σmin,σmax],t(ci(t))為個體ci(t)被評價時間。將t(ci(t))與當前進化代內個體最長評價時間比值作為個體ci(t)的滿意度,記為hi:
hi越大,
個體ci(t)的模糊適應值
與以往研究相比,本發明的模糊適應值估計方法特點是:用戶按單一數值習慣評價個體就可以獲得信息含量更豐富的模糊適應值,減輕了人的操作負擔;同時,因為式(5)是連續函數,所以語氣詞為連續數值,模糊適應值的偏好表達更為全面;另一方面,在進化過程中通過估計適應值寬度使得個體評價更加準確,會提高算法收斂性和優化質量。
步驟5.剩余個體模糊適應值估計
設個體xj(t)屬于類{ci(t)},記
假設
剩余個體xj(t)的模糊適應值中心值d(xj(t))計算公式為:
式中,k是個體表現型相似度μ(xj(t),ci(t))最大值大于閾值θ(t)時的聚類中心:
閾值θ(t)由前一代個體適應值中心值刻劃:
式中,α是反映評價性能的參數。可以看出,閾值θ(t)隨進化代內最大適應值增加而增加,利用前一進化代的信息計算閾值,可以為下一代估計d(xj(t))提供依據。
d(xj(t))表明,進化初期由于個體間相似性較小,閾值θ(t)較小,剩余個體適應值中心值d(xj(t))較小;隨著算法逐漸收斂,個體間相似性逐漸增大,閾值θ(t)也逐漸提高,剩余個體適應值中心值d(xj(t))逐漸增大。通過對各聚類中心相似度的加權估計中心值,提高了信息利用率,估計結果更加精確。
相似地,剩余個體xj(t)的模糊適應值寬度值σ(xj(t))計算公式為:
上述方法實現了對所有個體的模糊適應值估計,在大規模種群前提下,偏好信息更加豐富,更有利于進化優化。
步驟6.個體選擇
為了更客觀的選擇模糊適應值的個體,本發明考慮規模為2的聯賽選擇,設比較個體為xa(t),xb(t),則個體選擇適應值分別為f(xa(t)),f(xb(t)):
f(xa(t))=d(xa(t))·μ(xb(t),xa(t))(10)
f(xb(t))=d(xb(t))·μ(xa(t),xb(t))(11)
式中,d(xa(t)),d(xb(t))分別是個體xa(t),xb(t)的模糊適應值中心值;μ(xa(t),xb(t)),μ(xb(t),xa(t))分別是以個體xb(t)和xa(t)為參照個體,以xa(t)和xb(t)為比較個體的相似度。
該式考慮了模糊適應值中心值和寬度對個體選擇的共同影響。其中,中心值對適應值大小起主導作用,但由于認知的模糊性和不確定性,模糊適應值的比較不能完全由中心值決定,所以還要考慮寬度值的作用。這可以通過個體相似性體現,在式(10)中,μ(xb(t),xa(t))刻畫了以個體xa(t)為參照的xb(t)的相似性,體現了xa(t)的評價不確定性對xb(t)的影響,與中心值d(xa(t))乘積可以更好的突出個體的選擇性。所以,個體選擇條件為:當f(xa(t))>f(xb(t))時,選擇個體xa(t);f(xa(t))<f(xb(t)),選擇個體xb(t);當f(xa(t))=f(xb(t))時,隨機選擇xa(t),xb(t)。上述個體選擇方法的特點在于:個體選擇不直接采用模糊適應值,通過個體表現型相似性修正個體模糊適應值中心值實現個體比較,不僅符合評價規律,而且實現簡便,
步驟7.選擇操作后,經過交叉和變異,生成新一代種群。如果設計人員對新種群的款式樣本滿意,則保存最優設計方案,完成設計。否則,算法跳轉步驟2,設計人員點擊“下一代”進化按鈕,繼續對掛鐘樣本打分評價。在整個進化過程中,如果設計人員對當前的方案始終不夠滿意,可重新初始化種群,開始新的進化。
該算法與目前算法的比較
目前已有的應用于產品設計的算法主要有基于區間適應值的大種群規模交互式遺傳算法(interactivegeneticalgorithmswithlargepopulationsize,iga-lps)和基于模糊適應值的交互式遺傳算法(interactivegeneticalgorithmswithfuzzyindividuals’fitness,iga-fif)。本發明從進化代數、優化耗時和最優解適應值(中心值)等三個方面衡量方法性能。比較分為固定解優化測試(項目1)和非固定解優化測試(項目2)兩個部分進行,統計結果如下表所示。
可以看出,在項目1中,在進化代數方面,本發明的所有用戶均在最大進化代數內完成優化,平均進化代數為15.38,3種方法中最低,iga-fif進化代數最多。做平均值和方差雙樣本均值分析,t檢驗差異顯著(p<0.05)。原因在于,本發明的適應值準確,進化方向最為明確,進化過程更為順利。評價耗時方面,本發明每位用戶平均耗時6.05分鐘,仍為3種方法中最低,iga-fif耗時最多,t檢驗差異顯著(p<0.05)。這是因為,本發明采用單一數值評價,操作量最少;iga-lps需要對適應值上限和下限取值;iga-fif需要對語氣詞和中心值取值,所以造成耗時增加。最優解適應值方面,本發明最高,這反映出用戶對本發明優化結果最滿意。由于本發明在3種算法進化代數和評價耗時均為最少,同時最優解適應值最高,所以可以明顯減輕用戶疲勞。
在項目2中,采用本發明,20名用戶中,8名用戶在最大進化代數之前,獲得滿意解,并給出超過95分的評價值,這表明這8名用戶對優化結果十分滿意。從表中數據看,本發明所有用戶平均適應值為88.12,3種方法中最高。這種高評分低分布差異表明,用戶可以獲得滿意解,并且設定20代為最大進化代數是足夠的。在進化代數和優化耗時方面,本發明都是最低的,且t檢驗差異顯著。這表明,在非固定解優化測試條件下,本發明仍可以顯著降低用戶操作負擔,減輕疲勞。
- 還沒有人留言評論。精彩留言會獲得點贊!