情緒識(shí)別方法、裝置及存儲(chǔ)介質(zhì)與流程
本公開涉及情緒識(shí)別領(lǐng)域,尤其涉及情緒識(shí)別方法、裝置及存儲(chǔ)介質(zhì)。
背景技術(shù):
1、目前,終端通過拍攝圖像或采集音頻的方式識(shí)別終端用戶當(dāng)前的情緒。然而,受圖像質(zhì)量和音頻質(zhì)量的影響,情緒識(shí)別的結(jié)果并不準(zhǔn)確。
技術(shù)實(shí)現(xiàn)思路
1、為克服相關(guān)技術(shù)中存在的問題,本公開提供一種情緒識(shí)別方法、裝置及存儲(chǔ)介質(zhì)。
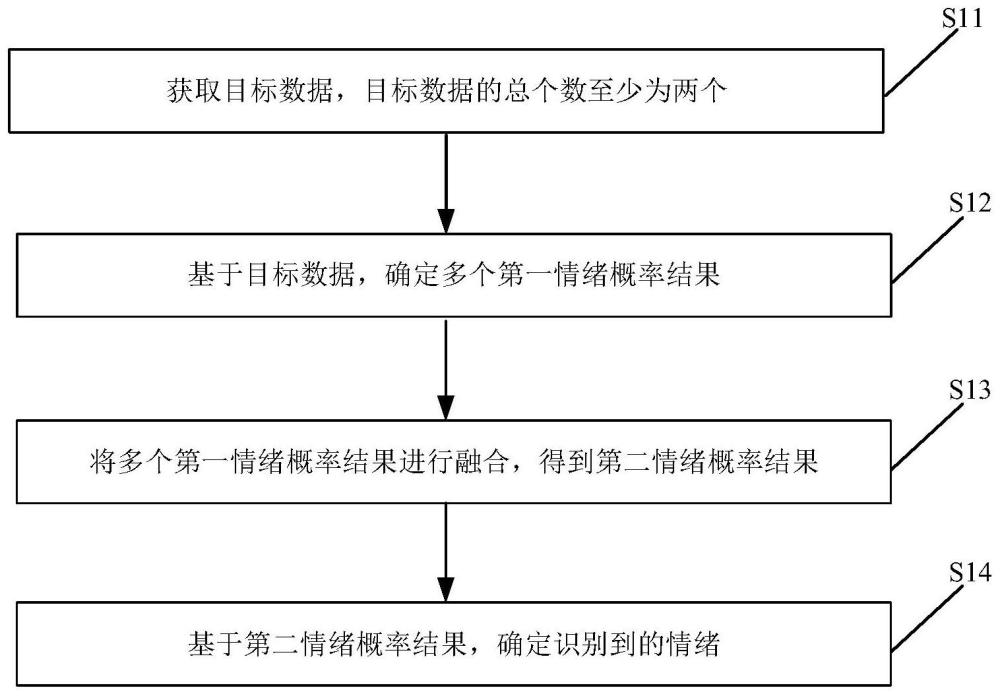
2、根據(jù)本公開實(shí)施例的第一方面,提供一種情緒識(shí)別方法,包括:獲取目標(biāo)數(shù)據(jù),所述目標(biāo)數(shù)據(jù)的總個(gè)數(shù)至少為兩個(gè);基于所述目標(biāo)數(shù)據(jù),確定多個(gè)第一情緒概率結(jié)果;將所述多個(gè)第一情緒概率結(jié)果進(jìn)行融合,得到第二情緒概率結(jié)果;基于所述第二情緒概率結(jié)果,確定識(shí)別到的情緒。
3、在一種實(shí)施方式中,所述基于所述目標(biāo)數(shù)據(jù),確定多個(gè)第一情緒概率結(jié)果,包括:將所述目標(biāo)數(shù)據(jù)輸入神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果。
4、在一種實(shí)施方式中,所述目標(biāo)數(shù)據(jù)包括圖像,所述將所述目標(biāo)數(shù)據(jù)輸入神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果,包括:響應(yīng)于所述圖像中包括人臉特征,將所述圖像輸入第一神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果。
5、在一種實(shí)施方式中,所述目標(biāo)數(shù)據(jù)包括圖像和音頻,所述將所述目標(biāo)數(shù)據(jù)輸入神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果,包括:響應(yīng)于所述圖像中不包括人臉特征,將所述音頻輸入第二神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果。
6、在一種實(shí)施方式中,所述目標(biāo)數(shù)據(jù)包括圖像和音頻,所述將所述目標(biāo)數(shù)據(jù)輸入神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果,包括:響應(yīng)于所述圖像中包括人臉特征,將所述圖像輸入所述第一神經(jīng)網(wǎng)絡(luò)模型,獲取每個(gè)圖像對(duì)應(yīng)的第一神經(jīng)網(wǎng)絡(luò)模型中間層輸出的m個(gè)數(shù)值;將所述音頻輸入所述第二神經(jīng)網(wǎng)絡(luò)模型,獲取每個(gè)音頻對(duì)應(yīng)的第二神經(jīng)網(wǎng)絡(luò)模型中間層輸出的n個(gè)數(shù)值;將第一圖像對(duì)應(yīng)的所述m個(gè)數(shù)值和第一音頻對(duì)應(yīng)所述n個(gè)數(shù)值輸入第三神經(jīng)網(wǎng)絡(luò)模型,得到第一情緒概率結(jié)果,所述第一音頻表示所述音頻中的任意一個(gè)音頻,所述第一圖像表示所述圖像中的任意一個(gè)圖像,所述第一音頻在所述音頻中按照獲取時(shí)間排序后的位置和所述第一圖像在所述圖像中按照獲取時(shí)間排序后的位置相同。
7、在一種實(shí)施方式中,所述目標(biāo)數(shù)據(jù)包括音頻,所述第一情緒概率結(jié)果中包括第一情緒的概率和第二情緒的概率,所述基于所述第二情緒概率結(jié)果,確定識(shí)別到的情緒,包括:響應(yīng)于所述第一情緒的概率和所述第二情緒的概率相加大于或等于第一閾值,且所述第一情緒的概率和所述第二情緒的概率相減小于或等于第一閾值,提取所述音頻的音頻特征;將所述音頻特征輸入第四神經(jīng)網(wǎng)絡(luò)模型,得到輸出結(jié)果,所述輸出結(jié)果包括情緒識(shí)別為第一情緒或情緒識(shí)別為第二情緒。
8、在一種實(shí)施方式中,所述音頻特征包括以下至少一項(xiàng):時(shí)域相關(guān)的特征;頻域相關(guān)的特征;梅爾頻率倒譜系數(shù)mfcc相關(guān)的特征。
9、在一種實(shí)施方式中,所述確定識(shí)別到的情緒后,所述方法還包括:響應(yīng)于所述識(shí)別到的情緒與最近一次記載的情緒不同,記載所述識(shí)別到的情緒以及所述識(shí)別到的情緒關(guān)聯(lián)的時(shí)間信息和位置信息。
10、在一種實(shí)施方式中,所述第一神經(jīng)網(wǎng)絡(luò)模型采用如下方式訓(xùn)練得到:采集第一圖像數(shù)據(jù)集和第二圖像數(shù)據(jù)集,所述第二圖像數(shù)據(jù)集中的圖像質(zhì)量低于所述第一圖像數(shù)據(jù)集中的圖像質(zhì)量;利用所述第一圖像數(shù)據(jù)集對(duì)待訓(xùn)練模型進(jìn)行訓(xùn)練;利用所述第二圖像數(shù)據(jù)集調(diào)整所述待訓(xùn)練模型的參數(shù),得到所述第一神經(jīng)網(wǎng)絡(luò)模型。
11、在一種實(shí)施方式中,所述第二神經(jīng)網(wǎng)絡(luò)模型采用如下方式訓(xùn)練得到:采集第一音頻數(shù)據(jù)集和第二音頻數(shù)據(jù)集,所述第二音頻數(shù)據(jù)集中的音頻質(zhì)量低于所述第一音頻數(shù)據(jù)集中的音頻質(zhì)量;利用所述第一音頻數(shù)據(jù)集對(duì)待訓(xùn)練模型進(jìn)行訓(xùn)練;利用所述第二音頻數(shù)據(jù)集調(diào)整所述待訓(xùn)練模型的參數(shù),得到所述第二神經(jīng)網(wǎng)絡(luò)模型。
12、根據(jù)本公開實(shí)施例的第二方面,提供一種情緒識(shí)別裝置,包括:獲取單元,用于獲取目標(biāo)數(shù)據(jù),所述目標(biāo)數(shù)據(jù)的總個(gè)數(shù)至少為兩個(gè);確定單元,用于基于所述目標(biāo)數(shù)據(jù),確定多個(gè)第一情緒概率結(jié)果;處理單元,用于將所述多個(gè)第一情緒概率結(jié)果進(jìn)行融合,得到第二情緒概率結(jié)果;所述確定單元,還用于基于所述第二情緒概率結(jié)果,確定識(shí)別到的情緒。
13、在一種實(shí)施方式中,所述確定單元采用如下方式基于所述目標(biāo)數(shù)據(jù),確定多個(gè)第一情緒概率結(jié)果:將所述目標(biāo)數(shù)據(jù)輸入神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果。
14、在一種實(shí)施方式中,所述目標(biāo)數(shù)據(jù)包括圖像,所述確定單元采用如下方式將所述目標(biāo)數(shù)據(jù)輸入神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果:響應(yīng)于所述圖像中包括人臉特征,將所述圖像輸入第一神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果。
15、在一種實(shí)施方式中,所述目標(biāo)數(shù)據(jù)包括圖像和音頻,所述確定單元采用如下方式將所述目標(biāo)數(shù)據(jù)輸入神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果:響應(yīng)于所述圖像中不包括人臉特征,將所述音頻輸入第二神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果。
16、在一種實(shí)施方式中,所述目標(biāo)數(shù)據(jù)包括圖像和音頻,所述確定單元采用如下方式將所述目標(biāo)數(shù)據(jù)輸入神經(jīng)網(wǎng)絡(luò)模型,得到多個(gè)第一情緒概率結(jié)果:響應(yīng)于所述圖像中包括人臉特征,將所述圖像輸入所述第一神經(jīng)網(wǎng)絡(luò)模型,獲取每個(gè)圖像對(duì)應(yīng)的第一神經(jīng)網(wǎng)絡(luò)模型中間層輸出的m個(gè)數(shù)值;將所述音頻輸入所述第二神經(jīng)網(wǎng)絡(luò)模型,獲取每個(gè)音頻對(duì)應(yīng)的第二神經(jīng)網(wǎng)絡(luò)模型中間層輸出的n個(gè)數(shù)值;將第一圖像對(duì)應(yīng)的所述m個(gè)數(shù)值和第一音頻對(duì)應(yīng)所述n個(gè)數(shù)值輸入第三神經(jīng)網(wǎng)絡(luò)模型,得到第一情緒概率結(jié)果,所述第一音頻表示所述音頻中的任意一個(gè)音頻,所述第一圖像表示所述圖像中的任意一個(gè)圖像,所述第一音頻在所述音頻中按照獲取時(shí)間排序后的位置和所述第一圖像在所述圖像中按照獲取時(shí)間排序后的位置相同。
17、在一種實(shí)施方式中,所述目標(biāo)數(shù)據(jù)包括音頻,所述第一情緒概率結(jié)果中包括第一情緒的概率和第二情緒的概率,所述確定單元采用如下方式基于所述第二情緒概率結(jié)果,確定識(shí)別到的情緒:響應(yīng)于所述第一情緒的概率和所述第二情緒的概率相加大于或等于第一閾值,且所述第一情緒的概率和所述第二情緒的概率相減小于或等于第一閾值,提取所述音頻的音頻特征;將所述音頻特征輸入第四神經(jīng)網(wǎng)絡(luò)模型,得到輸出結(jié)果,所述輸出結(jié)果包括情緒識(shí)別為第一情緒或情緒識(shí)別為第二情緒。
18、在一種實(shí)施方式中,所述音頻特征包括以下至少一項(xiàng):時(shí)域相關(guān)的特征;頻域相關(guān)的特征;梅爾頻率倒譜系數(shù)mfcc相關(guān)的特征。
19、在一種實(shí)施方式中,所述確定識(shí)別到的情緒后,所述方法還包括:響應(yīng)于所述識(shí)別到的情緒與最近一次記載的情緒不同,記載所述識(shí)別到的情緒以及所述識(shí)別到的情緒關(guān)聯(lián)的時(shí)間信息和位置信息。
20、在一種實(shí)施方式中,所述處理單元采用如下如下方式訓(xùn)練得到第一神經(jīng)網(wǎng)絡(luò)模型:采集第一圖像數(shù)據(jù)集和第二圖像數(shù)據(jù)集,所述第二圖像數(shù)據(jù)集中的圖像質(zhì)量低于所述第一圖像數(shù)據(jù)集中的圖像質(zhì)量;利用所述第一圖像數(shù)據(jù)集對(duì)待訓(xùn)練模型進(jìn)行訓(xùn)練;利用所述第二圖像數(shù)據(jù)集調(diào)整所述待訓(xùn)練模型的參數(shù),得到所述第一神經(jīng)網(wǎng)絡(luò)模型。
21、在一種實(shí)施方式中,所述處理單元采用如下如下方式訓(xùn)練得到第二神經(jīng)網(wǎng)絡(luò)模型:采集第一音頻數(shù)據(jù)集和第二音頻數(shù)據(jù)集,所述第二音頻數(shù)據(jù)集中的音頻質(zhì)量低于所述第一音頻數(shù)據(jù)集中的音頻質(zhì)量;利用所述第一音頻數(shù)據(jù)集對(duì)待訓(xùn)練模型進(jìn)行訓(xùn)練;利用所述第二音頻數(shù)據(jù)集調(diào)整所述待訓(xùn)練模型的參數(shù),得到所述第二神經(jīng)網(wǎng)絡(luò)模型。
22、根據(jù)本公開實(shí)施例的第三方面,提供一種電子設(shè)備,包括:存儲(chǔ)器,用于存儲(chǔ)指令;以及處理器,用于調(diào)用存儲(chǔ)器存儲(chǔ)的指令執(zhí)行第一方面以及第一方面任意一種實(shí)施方式或第二方面以及第二方面任意一種實(shí)施方式中的情緒識(shí)別方法。
23、根據(jù)本公開實(shí)施例的第四方面,提供一種存儲(chǔ)介質(zhì),存儲(chǔ)介質(zhì)中存儲(chǔ)有指令,指令被處理器執(zhí)行時(shí),執(zhí)行第一方面或第一方面任意一種實(shí)施方式中的情緒識(shí)別方法。
24、本公開的實(shí)施例提供的技術(shù)方案可以包括以下有益效果:通過將多個(gè)識(shí)別結(jié)果按照預(yù)設(shè)比列融合,得到融合后的識(shí)別結(jié)果能夠有效提高情緒識(shí)別的準(zhǔn)確度,且無需終端較高的算力,節(jié)省功耗,提升用戶體驗(yàn)。
25、應(yīng)當(dāng)理解的是,以上的一般描述和后文的細(xì)節(jié)描述僅是示例性和解釋性的,并不能限制本公開。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!