一種基于小樣本的半監督高效視頻SAR陰影追蹤方法
本申請涉及雷達目標識別領域,尤其涉及一種基于小樣本的半監督高效視頻sar陰影追蹤方法。
背景技術:
1、隨著合成孔徑雷達(sar)技術的快速發展,sar圖像在地表監測、災害評估和軍事偵察等領域的應用越來越廣泛。特別是在復雜環境下,陰影區域的準確跟蹤對于目標識別和地物分類至關重要。然而,在sar圖像中,陰影區域通常由于成像幾何和反射特性而導致信號衰減,表現為低亮度區域,這對后續的目標檢測和分類任務構成了挑戰。因此,準確地識別和跟蹤陰影區域成為提升sar圖像處理性能的關鍵。
2、當前,大多數陰影跟蹤算法依賴于大量的標注數據進行訓練,這在小樣本場景中變得尤為困難。因此,如何有效利用有限的標注樣本和大量的無標注樣本,提升陰影跟蹤的準確性,成為亟待解決的問題。
3、近年來,半監督學習技術因其能夠結合有標簽和無標簽數據的優勢,逐漸引起研究者的關注。同時,基于半監督學習的圖像處理技術在多個領域取得了顯著進展,然而針對視頻sar圖像的陰影跟蹤方法仍然相對匱乏,特別是在小樣本條件下的應用場景。
技術實現思路
1、為了解決現有陰影跟蹤傳統算法中依賴大量標注數據進行訓練的問題,本申請提供了一種基于小樣本的半監督高效視頻sar陰影追蹤方法,通過優化模型結構和引入先進的半監督學習技術,提升陰影區域的跟蹤準確率和魯棒性,以適應各種復雜環境下的實際應用需求。
2、本申請采用的技術方案為:
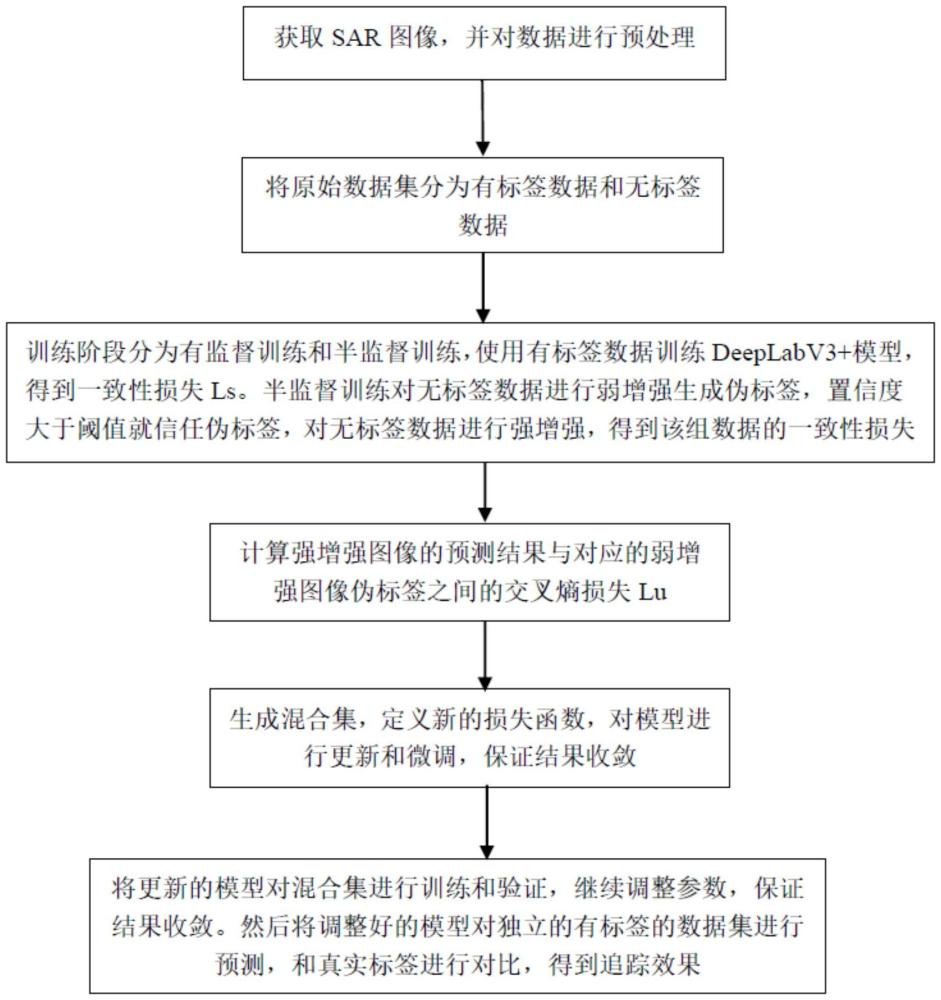
3、一種基于小樣本的半監督高效視頻sar陰影追蹤方法,包括下列步驟:
4、步驟1、步驟1、獲取sar圖像并對其進行圖像預處理(以適應設置的語義分割模型,如deeplabv3+模型),基于圖像預處理后的若干幅各sar圖像得到原始數據集;其中,圖像預處理包括:圖像二值化處理,以及將二值化處理后的圖像進行圖像尺寸歸一化處理;
5、該步驟中,二值化處理為:將背景的像素點設為0,將目標的像素點設為1,統一的圖像尺寸可以設置為512×512。
6、步驟2,將原始數據集分為有標簽原始數據集和無標簽原始數據集;
7、步驟3,對有標簽原始數據集進行第一訓練集和第一驗證集的劃分,再基于第一訓練集對設置的語義分割模型進行有監督訓練以優化模型的網絡參數(如權重和偏置項),并基于第一驗證集對語義分割模的超參數進行調優;且有監督訓練時的損失函數采用一致性損失,如交叉熵損失;
8、其中,語義分割模型用于識別多個目標并進行分割,其輸出層用于對輸入數據進行n+1分類及其分割,其中,即包括n個所需的目標類別和一個未知類別;
9、步驟4,基于無標簽原始數據集對有監督訓練好的語義分割模型進行半監督訓練;
10、對無標簽原始數據集每一無標簽原始數據樣本進行圖像弱增強處理,以得到每一無標簽原始數據樣本的至少一個弱增強樣本;
11、將弱增強樣本輸入到監督訓練好的語義分割模型中,基于其輸出的預測類別獲取當前弱增強樣本的偽標簽;
12、對無標簽原始數據集每一無標簽原始數據樣本進行圖像強增強處理,以得到每一無標簽原始數據樣本的至少一個強增強樣本;
13、對每一個無標簽原始數據樣本j,基于一個弱增強樣本和一個強增強樣本得到對應于j的一對弱強樣本對;
14、基于有標簽原始數據集和所有弱強樣本對組成混合集,再以該混合集作為第二訓練集對有監督訓練好的語義分割模型進行二次訓練;
15、二次訓練時采用的總損失函數為:有標簽原始數據集所對應的第一一致性損失和基于所有弱強樣本對的第二一致性損失的加權和;其中,對第二一致性損失,以弱強樣本對中的強增強樣本為模型輸入,對應的弱增強樣本的偽標簽視為真實標簽;
16、步驟5,從混合集中提取微調數據集對二次訓練后的語義分割模型進行微調,微調時的損失函數采用一致性損失;且該微調數據集中,將弱強樣本對分別視為一個模型輸入樣本,并將其對應的偽標簽視為各樣本的真實標簽;
17、基于微調后的語義分割模型得到用于sar陰影追蹤的分割模型,基于該分割模型實現對待追蹤的sar圖像的陰影區域預測。即需要對待追蹤的sar圖像進行預處理以適應語義分割模型的輸入。
18、進一步的,步驟4還包括:
19、將預測置信度(語義分割模型輸出)大于預置閾值的偽標簽視為可靠偽標簽;
20、對存在可靠偽標簽每一個原始數據樣本,基于一個強增強樣本和一個可靠偽標簽所對應弱增強樣本組成當前原始數據樣本j的弱強樣本對。
21、進一步的,步驟5中提取出的微調數據集中的弱強樣本對為存在可靠偽標簽的弱強樣本對。
22、進一步地,步驟2中,有標簽數據和無標簽數據的占比為2:8,以構成小樣本數據集。
23、進一步的,步驟3中,第一訓練集和第一驗證集的占比分別為80%和10%。
24、進一步的,語義分割模型采用deeplabv3+模型,其主干網絡為mobilenet,優化器選擇sgd(隨機梯度下降),基于所設置的初始學習率、最小學習率lrmin、最大學習率lrmax和訓練的總輪數t采用的學習率下降方式為余弦退火方式。
25、進一步的,步驟4中,圖像弱增強處理包括:對數據進行隨機翻轉(如以50%的概率)、進行隨機裁剪和進行隨機旋轉(如10°)。
26、進一步的,步驟4中,圖像強增強處理包括:隨機遮擋圖像、將兩張圖像以指定比例的線性組合所生成的新圖像,以及噪聲添加。
27、進一步地,所述步驟4中,第二一致性損失為以強增強圖像為輸入、對應的偽標簽/可靠偽標簽視為真實標簽的分類交叉熵損失。
28、進一步地,步驟4中,總損失函數為:total?loss=ls+λ*lu,其中,ls、lu分別為第一和第二一致性損失,λ為預置的權重系數,表示無標簽損失在總損失中的貢獻,優選的,可將其設置為λ=0.67。
29、進一步地,步驟5還包括,基于微調后的語義分割模型所預測的陰影區域,計算其與真實陰影區域之間的交并比,當其大于0.5時,視為sar陰影追蹤成功。進而可以計算出追蹤率,以此來評價該模型是否達到目的。
30、本申請提供的技術方案至少帶來如下有益效果:
31、本申請可以在減少有標簽數據的同時,提高了陰影追蹤的準確性。
技術特征:
1.一種基于小樣本的半監督高效視頻sar陰影追蹤方法,其特征在于,包括下列步驟:
2.如權利要求1所述的方法,其特征在于,步驟1中,二值化處理為:將背景的像素點設為0,將目標的像素點設為1。
3.如權利要求1所述的方法,其特征在于,步驟2中,有標簽數據和無標簽數據的占比為2:8。
4.如權利要求1所述的方法,其特征在于,步驟3中,第一訓練集和第一驗證集的占比分別為80%和10%。
5.如權利要求1所述的方法,其特征在于,語義分割模型采用deeplabv3+模型,其主干網絡為mobilenet,優化器選擇sgd,基于所設置的初始學習率、最小學習率lrmin、最大學習率lrmax和訓練的總輪數t采用的學習率下降方式為余弦退火方式。
6.如權利要求1所述的方法,其特征在于,步驟4中,圖像弱增強處理包括:對數據進行隨機翻轉、進行隨機裁剪和進行隨機旋轉;圖像強增強處理包括:隨機遮擋圖像、將兩張圖像以指定比例的線性組合所生成的新圖像,以及噪聲添加。
7.如權利要求1所述的方法,其特征在于,所述步驟4中,第二一致性損失為以強增強圖像為輸入、對應的偽標簽/可靠偽標簽視為真實標簽的分類交叉熵損失。
8.如權利要求1所述的方法,其特征在于,步驟4中,總損失函數為:total?loss=ls+λ*lu,其中,ls、lu分別為第一和第二一致性損失,λ為預置的權重系數,表示無標簽損失在總損失中的貢獻,優選的,可將其設置為λ=0.67。
9.如權利要求1所述的方法,其特征在于,步驟4還包括:
10.如權利要求1所述的方法,其特征在于,步驟5中提取出的微調數據集中的弱強樣本對為存在可靠偽標簽的弱強樣本對,其中,可靠偽標簽指某個弱增強樣本的預測置信度大于預置閾值的偽標簽。
技術總結
本申請公開了一種基于小樣本的半監督高效視頻SAR陰影追蹤方法,屬于雷達目標識別領域。本申請所提方法解決了傳統陰影跟蹤技術的局限性,通過改進的分割模型和半監督策略策略,提升了陰影區域的檢測精度和魯棒性;基于所設計的新的混合訓練策略,有效的整合了有標簽與無標簽數據,顯著提高了模型的學習效率和泛化能力。通過將深度學習技術和半監督學習策略結合,充分利用有限的標注數據與豐富的無標注數據,解決了傳統方法在小樣本條件下的不足,有效提升SAR圖像中陰影區域的檢測和跟蹤精度。
技術研發人員:楊夏青,高森浩,張冰杰,齊智靈,師君,陳家輝,黃金元,余湋,劉田
受保護的技術使用者:電子科技大學
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!