一種大模型檢索增強生成的自適應切片的文檔切分方法與流程
所屬的技術人員知道,本發明可以實現為系統、方法或計算機程序產品,因此,本公開可以具體實現為以下形式,即:可以是完全的硬件、也可以是完全的軟件(包括固件、駐留軟件、微代碼等),還可以是硬件和軟件結合的形式,本文一般稱為“電路”、“模塊”或“系統”。此外,在一些實施例中,本發明還可以實現為在一個或多個計算機可讀介質中的計算機程序產品的形式,該計算機可讀介質中包含計算機可讀的程序代碼。可以采用一個或多個計算機可讀的介質的任意組合。計算機可讀介質可以是計算機可讀信號介質或者計算機可讀存儲介質。計算機可讀存儲介質例如可以是一一但不限于——電、磁、光、電磁、紅外線、或半導體的系統、裝置或器件,或者任意以上的組合。計算機可讀存儲介質的更具體的例子(非窮舉的列表)包括:具有一個或多個導線的電連接、便攜式計算機磁盤、硬盤、隨機存取存儲器(ram),只讀存儲器(rom)、可擦式可編程只讀存儲器(eprom或閃存)、光纖、便攜式緊湊磁盤只讀存儲器(cd-rom)、光存儲器件、磁存儲器件、或者上述的任意合適的組合。在本文件中,計算機可讀存儲介質可以是任何包含或存儲程序的有形介質,該程序可以被指令執行系統、裝置或者器件使用或者與其結合使用。盡管上面已經示出和描述了本發明的實施例,可以理解的是,上述實施例是示例性的,不能理解為對本發明的限制,本領域的普通技術人員在本發明的范圍內可以對上述實施例進行變化、修改、替換和變型。
背景技術:
1、檢索增強生成(retrievalaugmented?generation)是一種應用于知識內容檢索領域的技術,結合了向量數據庫和大語言模型,旨在通過檢索技術增強大模型的生成能力。其中向量數據庫的構建過程為:文檔準備→文檔切分→切片向量化→存儲。文檔切分是為了優化向量數據庫的構建和提升大語言模型的生成質量。在這個技術中,大模型會基于檢索排序后的文檔切分內容進行參考回答,所以文檔切分對于大模型的回答質量尤為重要。
2、在檢索增強生成中的文檔切分技術方面,以往的方法主要包括基于固定字數切塊和基于指定的標點符號切塊兩種方式。
3、基于固定字數切塊的方法往往無法很好地適應不同文檔內容和結構的變化。由于不同文檔的段落長度和內容差異較大,固定字數切塊可能導致切分結果不夠精準,影響后續的文檔處理和分析。
4、鑒于傳統的文檔切分技術存在的局限性,需要進一步優化和改進以滿足對文檔切分技術更高要求的需求。
技術實現思路
1、本發明所要解決的技術問題是針對現有技術的不足,具體提供了一種大模型檢索增強生成的自適應切片的文檔切分方法,具體如下:
2、1)第一方面,本發明提供一種大模型檢索增強生成的自適應切片的文檔切分方法,具體技術方案如下:
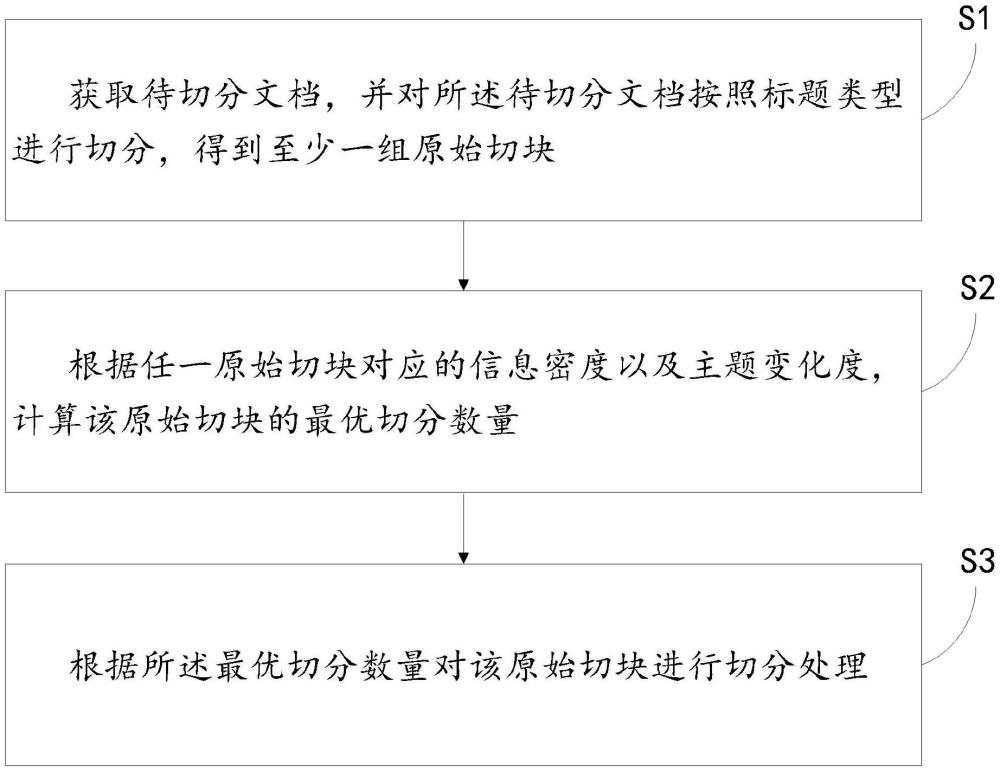
3、獲取待切分文檔,并對所述待切分文檔按照標題類型進行切分,得到至少一組原始切塊;
4、根據任一原始切塊對應的信息密度以及主題變化度,計算該原始切塊的最優切分數量;
5、根據所述最優切分數量對該原始切塊進行切分處理。
6、本發明提供的一種大模型檢索增強生成的自適應切片的文檔切分方法的有益效果如下:
7、先將文檔按照層次標題進行切分,然后計算層次標題下的信息密度和主題變化度,以層級標題為單位,自動計算該層級標題下的最優切分大小,來指導文檔的自適應切分,以提高后續檢索和生成任務的效果。
8、在上述方案的基礎上,本發明還可以做如下改進。
9、進一步,所述信息密度的計算方式為:
10、
11、其中,ti表示第i個原始切塊對應的信息密度,nd為第i個原始切塊中對文字去重后的文字總個數,ti表示nd個去重后的文字中的第i個字通過tf-idf算法得到的權重,ni代表nd個去重后的文字中的第i個字出現的頻次,nall表示第i個原始切塊中所有字的個數。
12、進一步,所述主題變化度的計算方式為:
13、di=djs(vi-1,vi);
14、其中,di為第i個原始切塊對應的主題變化度,djs是jensen-shannon散度,vi-1表示第i-1個原始切塊對應的向量分布,vi代表當前第i個原始切塊的向量分布。
15、進一步,所述最優切分數量的計算方式為:
16、
17、其中,si為第i個原始切塊對應的最優切分數量,c表示第i個原始切塊對應的總字符數,α、β以及γ為調節參數。
18、2)第二方面,本發明還提供一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分系統,具體技術方案如下:
19、獲取模塊用于:獲取待切分文檔,并對所述待切分文檔按照標題類型進行切分,得到至少一組原始切塊;
20、計算模塊用于:根據任一原始切塊對應的信息密度以及主題變化度,計算該原始切塊的最優切分數量;
21、切分模塊用于:根據所述最優切分數量對該原始切塊進行切分處理。
22、在上述方案的基礎上,本發明還可以做如下改進。
23、進一步,所述信息密度的計算方式為:
24、
25、其中,ti表示第i個原始切塊對應的信息密度,nd為第i個原始切塊中對文字去重后的文字總個數,ti表示nd個去重后的文字中的第i個字通過tf-idf算法得到的權重,ni代表nd個去重后的文字中的第i個字出現的頻次,nall表示第i個原始切塊中所有字的個數。
26、進一步,所述主題變化度的計算方式為:
27、di=djs(vi-1,vi);
28、其中,di為第i個原始切塊對應的主題變化度,djs是jensen-shannon散度,vi-1表示第i-1個原始切塊對應的向量分布,vi代表當前第i個原始切塊的向量分布。
29、進一步,所述最優切分數量的計算方式為:
30、
31、其中,si為第i個原始切塊對應的最優切分數量,c表示第i個原始切塊對應的總字符數,α、β以及γ為調節參數。
32、3)第三方面,本發明還提供一種電子設備,所述電子設備包括處理器,所述處理器與存儲器耦合,所述存儲器中存儲有至少一條計算機程序,所述至少一條計算機程序由所述處理器加載并執行,以使所述電子設備實現如上任一項方法。
33、4)第四方面,本發明還提供一種計算機可讀存儲介質,所述計算機可讀存儲介質中存儲有至少一條計算機程序,所述至少一條計算機程序由處理器加載并執行,以使計算機實現如上任一項方法。
34、需要說明的是,本發明的第二方面至第四方面的技術方案及對應的可能的實現方式所取得的有益效果,可以參見上述對第一方面及其對應的可能的實現方式的技術效果,此處不再贅述。
技術特征:
1.一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分方法,其特征在于,包括:
2.根據權利要求1所述的一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分方法,其特征在于,所述信息密度的計算方式為:
3.根據權利要求2所述的一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分方法,其特征在于,所述主題變化度的計算方式為:
4.根據權利要求3所述的一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分方法,其特征在于,所述最優切分數量的計算方式為:
5.一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分系統,其特征在于,包括:
6.根據權利要求5所述的一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分系統,其特征在于,所述信息密度的計算方式為:
7.根據權利要求6所述的一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分系統,其特征在于,所述主題變化度的計算方式為:
8.根據權利要求7所述的一種大模型檢索增強生成中基于層級標題的自適應切片的文檔切分系統,其特征在于,所述最優切分數量的計算方式為:
9.一種電子設備,其特征在于,所述電子設備包括處理器,所述處理器與存儲器耦合,所述存儲器中存儲有至少一條計算機程序,所述至少一條計算機程序由所述處理器加載并執行,以使所述電子設備實現如權利要求1至4任一項權利要求所述的方法。
10.一種計算機可讀存儲介質,其特征在于,所述計算機可讀存儲介質中存儲有至少一條計算機程序,所述至少一條計算機程序由處理器加載并執行,以使計算機實現如權利要求1至4任一項權利要求所述的方法。
技術總結
本發明公開了一種大模型檢索增強生成的自適應切片的文檔切分方法,涉及大模型檢索增強生成技術領域,方法包括:獲取待切分文檔,并對所述待切分文檔按照標題類型進行切分,得到至少一組原始切塊;根據任一原始切塊對應的信息密度以及主題變化度,計算該原始切塊的最優切分數量;根據所述最優切分數量對該原始切塊進行切分處理。本發明先將文檔按照層次標題進行切分,然后計算層次標題下的信息密度和主題變化度,以層級標題為單位,自動計算該層級標題下的最優切分大小,來指導文檔的自適應切分,以提高后續檢索和生成任務的效果。
技術研發人員:白焜太,王蕾,周文仲,楊雅婷,許娟,史文釗
受保護的技術使用者:神州醫療科技股份有限公司
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!