一種基于Flink的流式數據處理方法、系統、設備及介質與流程
本發明屬于數據處理,具體涉及一種基于flink的流式數據處理方法、系統、設備及介質。
背景技術:
1、隨著互聯網和物聯網的發展,實時數據流的處理需求日益增長。例如某類型企業的數據處理平臺需要處理來自傳感器、用戶行為日志、金融交易等場景下的海量數據流,從而進行實時的分析和決策。傳統的批處理方式處理延遲高、實時性差,難以應對海量數據流的實時處理需求,更不能滿足現代應用場景的業務需求。
2、flink是apache?flink的簡稱,它是一個分布式數據處理引擎,可以處理實時流數據和批量數據,能夠處理無界數據流,處理具有低延遲、高吞吐量和容錯性等優點,能夠提供一定程度上的狀態管理和容錯,然而,在大規模的實時數據流的處理中,flink仍然存在數據分區失衡、狀態管理復雜、故障恢復瓶頸,不能滿足大規模實時數據流的處理需求。首先,如果某些分區的數據量遠大于其他分區,則會導致這些分區所在的處理節點過載,而其他節點則處于空閑狀態,不僅降低了數據處理平臺整體吞吐量,還可能導致處理延遲增加。其次,在flink的流處理框架中,通常使用全量狀態存儲,不僅占用了大量的存儲空間,還增加了狀態恢復時的網絡傳輸開銷。再次,傳統的故障恢復方案通常依賴于全量快照或日志重放,在回復時間、資源消耗和一致性保證等方面都存在不足,尤其對大規模實時數據流的處理中,故障恢復時間過長導致數據丟失或處理延遲增加。
技術實現思路
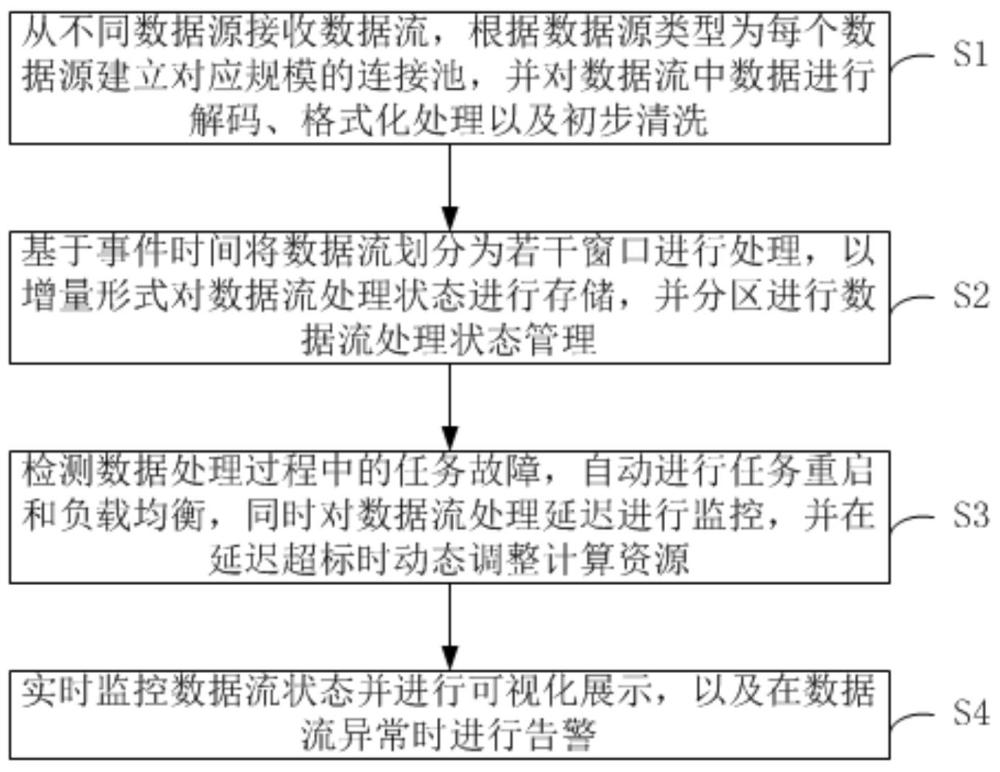
1、第一方面,本技術實施例提供一種基于flink的流式數據處理方法,包括如下步驟:
2、s1.從不同數據源接收數據流,根據數據源類型為每個數據源建立對應規模的連接池,并對數據流中數據進行解碼、格式化處理以及初步清洗;
3、s2.基于事件時間將數據流劃分為若干窗口進行處理,以增量形式對數據流處理狀態進行存儲,并分區進行數據流處理狀態管理;
4、s3.檢測數據處理過程中的任務故障,自動進行任務重啟和負載均衡,同時對數據流處理延遲進行監控,并在延遲超標時動態調整計算資源;
5、s4.實時監控數據流狀態并進行可視化展示,以及在數據流異常時進行告警。
6、進一步地,步驟s1具體步驟如下:
7、s11.確定數據處理平臺的數據源類型,并根據處理需求為每種類型數據源分別創建連接池,創建所需數量的處理線程;
8、s12.識別各類型數據源的數據格式,并為每種數據給是選擇適配的編碼器進行格式轉換,將給類型數據源轉換為數據處理平臺統一的標準數據格式;
9、s13.將完成格式轉換的數據流進行清洗,根據數據源類型識別并過濾空值、異常值以及格式不符的數據。
10、進一步地,步驟s2具體步驟如下:
11、s21.判定當前時間段;
12、若當前時間段為高峰時段,進入步驟s22;
13、若當前時間段為低谷時段,進入步驟s23;
14、若當前時間段為正常時段,進入步驟s24;
15、s22.將預設的窗口大小按照預設的增大幅度進行調整,進入步驟s24;
16、s23.將預設的窗口大小按照預設的減小幅度進行調整,進入步驟s24;
17、s24.根據各類型數據源的觸發事件時間對數據流按照預設的窗口大小進行窗口切分,并根據各類型數據源的最大延遲時間設置窗口水印;
18、s25.為數據流中位于各類型窗口內數據分配對應連接池中處理線程進行處理,并按照窗口水印等待數據事件;
19、s26.對數據流處理的窗口滑動過程中事件次數的差異狀態進行記錄,并且按流進行分區存儲。
20、進一步地,步驟s3具體步驟如下:
21、s31.對各類型數據源的處理線程所在計算節點的執行任務進行監測,當監測到某個計算節點故障時,查找可用的計算節點進行故障恢復;
22、s32.對類型數據源的處理延遲進行監測,并在處理延遲超過設定延遲閾值上限時,進行動態資源調整。
23、進一步地,步驟s31具體步驟如下:
24、s311.對各類型數據源的處理線程執行成功的事件時間進行記錄;
25、s312.對各類數據源的處理線程所在計算節點進行心跳監測;
26、若心跳監測正常,進入步驟s313;
27、若心跳監測異常,進入步驟s313;
28、s313.對各類數據源的處理線程所在計算節點的異常日志進行分析,判斷是否識別到資源不足;
29、若是,進入步驟s314;
30、若否,進入步驟s32;
31、s314.將當前計算節點判定為故障計算節點,并從負載率高于閾值的計算節點中選擇一個作為目標計算節點;
32、s315.將故障計算節點的處理線程遷移至目標計算節點,并按照最后一次保存的執行成功的事件時間進行數據流處理恢復。
33、進一步地,步驟s32具體步驟如下:
34、s321.統計數據流中各類型數據源的事件延遲,并計算平均延遲時間,所述事件延遲包括流轉延遲和處理延遲;
35、s322.對數據流中各類型數據源的事件的實時處理時間進行監控,判斷是否大于平均延遲時間,且持續時間大于設定時間閾值;
36、若是,進入步驟s323;
37、若否,進入步驟s4;
38、s323.對事件對應處理線程所在的計算節點的數量進行增加。
39、進一步地,步驟s4具體如下:
40、s41.對各類型數據源的處理狀態進行統計,所述處理狀態包括延遲、速率、事件數據;
41、s42.將數據流中各類型數據源的處理狀態生成圖表,并在圖形化界面進行展示;
42、s43.對數據流處理過程中的異常情況生成告警信息,并按照預設的方式通知運維人員。
43、第二方面,本技術實施例還提供一種基于flink的流式數據處理系統,包括:
44、數據源管理模塊,用于從不同數據源接收數據流,根據數據源類型為每個數據源建立對應規模的連接池,并對數據流中數據進行解碼、格式化處理以及初步清洗;
45、數據窗口及處理狀態管理模塊,用于基于事件時間將數據流劃分為若干窗口進行處理,以增量形式對數據流處理狀態進行存儲,并分區進行數據流處理狀態管理;
46、故障恢復及延遲監測模塊,用于檢測數據處理過程中的任務故障,自動進行任務重啟和負載均衡,同時對數據流處理延遲進行監控,并在延遲超標時動態調整計算資源;
47、實時監控模塊,用于實時監控數據流狀態并進行可視化展示,以及在數據流異常時進行告警。
48、第三方面,本技術實施例還提供一種電子設備,包括存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的計算機程序,所述處理器執行所述程序時實現如第一方面所述基于flink的流式數據處理方法的步驟。
49、第四方面,本技術實施例還提供一種存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現如第一方面所述基于flink的流式數據處理方法的步驟。
50、從以上技術方案可以看出,本發明具有以下優點:
51、本技術提供的基于flink的流式數據處理方法、系統、設備及介質中,通過接收不同數據源的數據流,并進行解碼、格式化、清洗等預處理,基于事件時間進行窗口劃分和增量狀態存儲,實現了對海量實時數據流的高效、穩定、可靠處理;同時,通過故障檢測、自動重啟、負載均衡和動態資源調整確保了系統的穩定性和實時性;通過實時監控和可視化展示則提高了系統的可維護性和可靠性。
- 還沒有人留言評論。精彩留言會獲得點贊!