基于KNet的鋼支撐和立柱數量識別方法及裝置
本發明涉及目標識別,具體涉及一種基于knet的鋼支撐和立柱數量識別方法及裝置。
背景技術:
1、隨著建筑工程自動化和安全管理的要求逐漸提高,傳統的人工檢查和定期維護的模式逐漸難以滿足實際的施工需求。鋼結構支撐和立柱作為建筑施工中的關鍵承重構件,其穩定性和分布合理性對施工質量和安全有著重要影響。然而,鋼結構的數量識別和分布分析主要依賴于人工統計和監測,效率低、成本高,且容易產生漏查和誤判。為了提升施工效率并確保支撐體系的可靠性,迫切需要開發一種智能化的識別裝置,能夠實時對鋼支撐和立柱的數量及布局進行監測和分析。
2、在此背景下,計算機視覺和機器學習等數據驅動方法逐漸應用于建筑工程的自動化識別領域。通過深度學習模型對圖像數據的分析,可以自動識別鋼支撐和立柱的分布狀態,提高識別效率,減少人力成本。然而,這類方法在應用中依然面臨多個挑戰。一方面,施工現場的光照、噪聲和遮擋等復雜環境影響模型識別的準確性。另一方面,鋼支撐和立柱的形狀和尺寸往往各異,如何有效區分和統計其數量是一個關鍵難點。
3、近年來,基于卷積神經網絡(cnn)的實例分割方法已取得顯著進展,為鋼支撐和立柱的數量識別提供了新的思路。例如,knet(kernel-based?network)模型在圖像分割任務上表現優異,能夠細化圖像中目標的邊緣,并準確定位個體對象,為鋼結構識別和統計提供了技術支持。然而,傳統分割方法多用于目標邊界清晰的場景,難以應對施工現場的復雜環境。尤其是鋼支撐和立柱的密集分布容易導致模型的識別精度降低,且現有模型對掩膜區域的分析缺乏針對性,難以進一步輸出結構特征數據如位置和密度。
技術實現思路
1、為了解決上述問題,本發明提出了基于knet的鋼支撐和立柱數量識別方法及裝置,解決現有技術中施工現場鋼結構識別效率低、準確性差的問題,實現了現代建筑施工對支撐結構實時監測的需求。
2、具體方案如下:
3、一方面,基于knet的鋼支撐和立柱數量識別方法,包括:
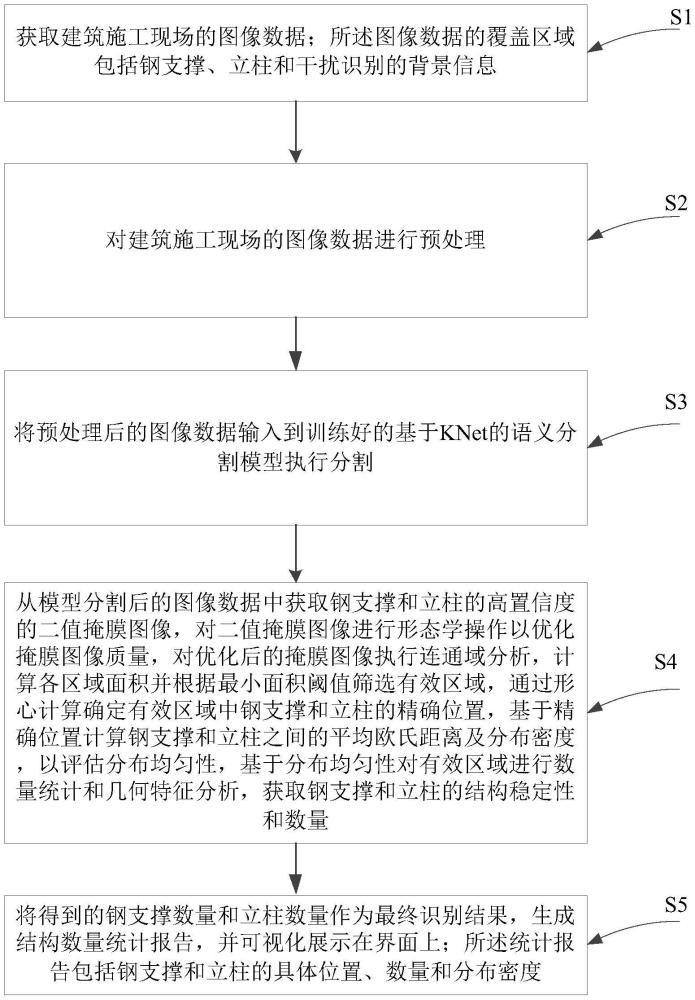
4、s1,獲取建筑施工現場的圖像數據;所述圖像數據的覆蓋區域包括鋼支撐、立柱和干擾識別的背景信息;
5、s2,對建筑施工現場的圖像數據進行預處理;
6、s3,將預處理后的圖像數據輸入到訓練好的基于knet的語義分割模型執行分割;
7、s4,從模型分割后的圖像數據中獲取鋼支撐和立柱的高置信度的二值掩膜圖像,對二值掩膜圖像進行形態學操作以優化掩膜圖像質量,對優化后的掩膜圖像執行連通域分析,計算各區域面積并根據最小面積閾值篩選有效區域,通過形心計算確定有效區域中鋼支撐和立柱的精確位置,基于精確位置計算鋼支撐和立柱之間的平均歐氏距離及分布密度,以評估分布均勻性,基于分布均勻性對有效區域進行數量統計和幾何特征分析,獲取鋼支撐和立柱的結構穩定性和數量;
8、s5,將得到的鋼支撐數量和立柱數量作為最終識別結果,生成結構數量統計報告,并可視化展示在界面上;所述統計報告包括鋼支撐和立柱的具體位置、數量和分布密度。
9、進一步的,s2中,所述預處理包括對建筑施工現場的圖像數據進行尺寸調整、圖像歸一化和數據增強;
10、所述尺寸調整:用于將建筑施工現場的圖像數據調整為符合knet模型輸入要求的標準尺寸以確保輸入圖像尺寸一致性;
11、所述圖像歸一化:用于對尺寸調整后的圖像數據進行歸一化操作,將像素值從[0,255]范圍縮放到[0,1];計算公式如下:
12、
13、其中,x為施工現場的圖像像素值,xmin和xmax分別為圖像像素值的最小和最大值;x′為歸一化后的圖像數據的像素值,其范圍為[0,1];
14、所述數據增強包括隨機裁剪、旋轉、色彩擾動以及模糊與噪聲添加;
15、所述隨機裁剪:用于隨機選擇歸一化后的圖像區域對歸一化后的圖像進行裁剪,以適應不同觀察角度和距離下的目標樣本,裁剪區域通過隨機生成中心點和尺度確定,公式如下:
16、rc=x′[x0:x0+hc,y0:y0+wc];
17、其中,hc和wc分別為裁剪區域的高度和寬度,(x0,y0)為隨機選擇的起始點坐標,rc為隨機裁剪后的歸一化圖像區域;
18、所述旋轉:用于在角度范圍為[-θ,θ]內對尺寸調整后的圖像進行隨機旋轉,選取角度θ∈[-15,15°],以模擬真實施工現場中的多角度觀察效果,公式如下:
19、x′rotated=x′·cos(θ)-y′·sin(θ);
20、其中,x′rotated表示旋轉后的圖像像素位置,θ為旋轉角度,x′和y′分別為圖像的橫坐標和縱坐標;
21、所述色彩擾動:用于對歸一化后的圖像進行隨機擾動,以模擬不同光照條件下的場景,色彩擾動的基本計算公式為:
22、x′adjusted=α·x′+β;
23、其中,x′adjusted為色彩擾動后的圖像,α用于控制歸一化后的圖像的對比度,β用于控制歸一化后的圖像的亮度;
24、所述模糊與噪聲添加:用于在歸一化后的圖像中加入高斯模糊或隨機噪聲,計算公式如下:
25、x′noisy=x′+n(0,σ2);
26、其中,n(0,σ2)為添加的高斯噪聲,σ為標準差,x′noisy為噪聲后的圖像。
27、進一步的,s3中,所述基于knet的語義分割模型,包括主干網絡部分、解碼頭部分、輔助頭部分、損失函數部分、代價敏感學習策略部分和優化器部分:
28、主干網絡部分通過提取輸入圖像的全局特征,獲取基礎特征表示;解碼頭部分在基礎特征上執行采樣與語義細化,生成精確的分割結果;輔助頭部分對主干網絡部分和解碼頭部分提供額外監督,輔助提升特征提取能力和收斂速度;損失函數部分對比分割結果與實際標注,計算誤差并提供優化目標;代價敏感學習策略部分通過加權損失函數改善對鋼支撐和立柱的識別;優化器基于損失更新模型參數,確保網絡的有效訓練;
29、主干網絡部分:采用swin?transformer作為主干網絡,通過分層自注意力機制逐步提取基礎特征,自注意力計算公式為:
30、
31、其中,q、k和v分別為查詢矩陣、鍵矩陣和值矩陣,dk為縮放因子;
32、解碼頭部分:由核更新頭kernel?update?head和統一感知器uperhead組成,核更新頭kernel?update?head用于動態調整分割特征;統一感知器uperhead用于聚合上下文信息;
33、輔助頭部分:通過結合全卷積網絡頭fcnhead以提供額外監督信號,通過全卷積網絡頭fcnhead輸出輔助分割結果實現主干網絡和解碼頭之間的梯度傳遞;
34、損失函數部分:采用交叉熵損失函數優化模型,交叉熵損失函數的定義為:
35、
36、其中,yi表示真實標簽,即樣本中鋼支撐或立柱對應的分類標簽;pi表示模型預測的概率,即模型對鋼支撐或立柱類別的預測概率;n為樣本數量,表示參與模型訓練或測試的樣本總數;
37、代價敏感學習策略部分:引入代價敏感學習策略,對鋼支撐、立柱和背景區域設置不同的權重系數wi,使模型在訓練時更關注鋼支撐和立柱目標區域,權重修正后的損失函數表示為:
38、
39、優化器部分:使用adamw優化器更新模型參數,更新規則為:
40、mt=β1mt-1+(1-β1)gt;
41、
42、其中,mt和vt分別為梯度的一階和二階動量,用于平滑和加速梯度更新;α為學習率,控制模型參數更新的步長;β1和β2為動量衰減系數,用于調節一階和二階動量的更新比例;∈為穩定項,用于避免分母為零,提高數值計算的穩定性;λ為權重衰減因子,通過引入正則化抑制模型過擬合;gt表示當前時刻t的梯度,指示模型優化方向,t表示迭代次數,用于跟蹤優化進程;φt表示模型的參數向量。
43、進一步的,所述kernel?update?head通過權重wdynamic進行卷積操作,計算公式如下:
44、fout=f*wdynamic+bdynamic;
45、其中,f為輸入特征圖,表示經過主干網絡提取的待處理特征數據,用于后續的特征提取與增強;wdynamic和bdynamic為基于輸入特征動態生成的卷積核權重和偏置,用于提升卷積操作的表達能力和靈活性;*表示卷積操作,對輸入特征圖f進行權重和偏置的加權計算,完成特征的提取與更新,以捕獲復雜工況下鋼支撐和立柱的特征分布。
46、進一步的,所述s4,具體包括:-
47、提取鋼支撐和立柱的二值掩膜圖像,篩選出置信度高于第一閾值的二值掩膜圖像區域,過濾置信度低于第一閾值的二值掩膜圖像區域;
48、二值掩膜圖像滿足以下條件:
49、
50、其中,(x,y)為圖像中的像素位置,m(x,y)為提取出的二值掩膜圖像,p(x,y)表示像素點的分割置信度,θ為閾值,用于過濾低置信度區域;
51、采用形態學操作,消除二值掩膜圖像噪聲的并填補小空洞;
52、形態學操作具體為通過閉運算,將閉操作的結果記為mmorph,公式如下:
53、mmorph=morph(m;kernel);
54、其中,kernel為形態學操作中的結構元素;
55、對處理后的二值掩膜圖像執行連通域分析,計算每個區域的面積,并根據最小面積閾值過濾掉小于最小面積閾值的區域,保留有效區域;
56、對閉操作的掩膜mmorph進行連通域分析以識別每一個連通區域ri并計算每個區域的面積a(ri),公式如下:
57、
58、通過設置第一閾值tmin來濾掉面積小于tmin的區域,保留符合條件的目標區域,有效區域集合定義為:
59、
60、通過計算每個有效區域的形心位置,以確定鋼支撐和立柱的精確位置;
61、所述形心位置的計算公式如下:
62、
63、其中,c(ri)=(xc,yc)為區域ri的形心位置;
64、基于精確位置計算鋼支撐和立柱之間的平均歐氏距離,并基于有效區域總面積與二值掩膜圖像的總面積之比得出鋼支撐和立柱在圖像中的分布密度,以評估鋼支撐和立柱的分布均勻性;
65、計算鋼支撐和立柱之間的平均歐氏距離davg,公式如下:
66、
67、其中,||c(ri)-c(ri+1)||為相鄰鋼支撐或立柱的歐氏距離,計算鋼支撐和立柱在圖像中的分布密度ρ:
68、
69、其中,為有效區域的總面積,aimg為二值掩膜圖像的總面積;
70、分析鋼支撐和立柱的幾何特征,以及鋼支撐和立柱對結構穩定性的影響;通過對有效區域的數量統計,并與密度和平均歐氏距離的計算結果相結合,獲取鋼支撐和立柱的總數;
71、通過計算形狀因子κ以衡量目標區域的形狀一致性,分析支撐結構的幾何特征,公式如下:
72、
73、其中,pi為區域ri的周長;
74、分別計算鋼支撐或立柱的數量,公式如下:
75、
76、其中,nsteel為鋼支撐的數量,為鋼支撐對應的有效區域。npillar為立柱的數量,為立柱對應的有效區域。
77、進一步的,s5中,還包括:
78、將結構數量統計結果存儲至數據庫或文件系統,以支持在施工現場管理、施工進度跟蹤和安全監控過程中需要時從數據庫或文件系統提取結構數量統計結果。
79、另一方面,基于knet的鋼支撐和立柱數量識別裝置,包括:
80、圖像數據獲取模塊,用于獲取建筑施工現場的圖像數據;所述圖像覆蓋區域包括鋼支撐、立柱和干擾識別的背景信息;
81、預處理模塊,用于對建筑施工現場的圖像數據進行預處理;
82、模型分割模塊,用于將預處理后的圖像數據輸入到預先訓練的基于knet的語義分割模型執行分割;
83、數量統計模塊,用于從模型分割后的圖像數據中獲取鋼支撐和立柱的高置信度的二值掩膜圖像,對二值掩膜圖像進行形態學操作以優化掩膜圖像質量,對優化后的掩膜圖像執行連通域分析,計算各區域面積并根據最小面積閾值篩選有效區域,通過形心計算確定有效區域中鋼支撐和立柱的精確位置,基于精確位置計算鋼支撐和立柱之間的平均歐氏距離及分布密度,以評估分布均勻性,基于分布均勻性對有效區域進行數量統計和幾何特征分析,獲取鋼支撐和立柱的結構穩定性和數量;
84、報告生成模塊,用于將得到的鋼支撐數量和立柱數量作為最終識別結果,生成結構數量統計報告,并可視化展示在界面上;所述統計報告包括鋼支撐和立柱的具體位置、數量和分布密度。
85、本發明采用如上技術方案,并具有有益效果:
86、(1)本發明通過精細化的區域分割、形態學操作和掩膜區域提取技術,解決了在復雜施工環境下進行鋼支撐和立柱數量識別時的精度和實時性問題;
87、(2)本發明通過掩膜區域提取,對關鍵信息區域進行聚焦處理,減少了背景干擾;采用區域大小過濾步驟,提升了對實際目標結構的識別準確度,減少了誤檢和漏檢情況;
88、(3)本發明通過動態的形心計算和數量統計,對結構位置和密度進行精確分析,并為場景中的支撐分布提供實時監控。
- 還沒有人留言評論。精彩留言會獲得點贊!