針對高動態決策場景智能體探索的強化學習系統及方法
本發明屬于深度強化學習的,尤其涉及基于演員-評論家框架的在線強化學習算法,主要涉及了一種針對高動態決策場景智能體探索的強化學習系統及方法。
背景技術:
1、在無人智能體控制場景中,無人智能體往往需要在復雜且動態變化的環境中運行,環境中的不確定因素增加了感知和決策的難度。在高動態決策場景中,無人智能體需要面對復雜的地形、氣象條件以及動態的戰場態勢,同時應對敵方的電子干擾與網絡攻擊。在此情況下,無人智能體需要自主完成移動、懸停、干擾等基礎動作,進而實現偵查、巡邏、補給、支援等復雜任務。
2、具體來說,在特殊環境中,無人智能體可能需要在山區、森林、沙漠等多樣地形中穿梭,這些地形特點使得感知和導航變得極具挑戰性。同時,天氣條件的快速變化,如風暴、雨雪等,也會對無人智能體的穩定飛行和傳感器的準確性產生重大影響。此外,敵方的電子干擾與網絡攻擊,如信號屏蔽、偽裝信號、網絡攻擊等,進一步增加了無人智能體在任務執行過程中的不確定性和風險。
3、面對這些挑戰,無人智能體不僅需要具備強大的感知能力和環境適應能力,還需要在瞬息萬變的特殊場景環境中進行高效決策。這包括自主選擇最佳的行動路徑,動態調整任務優先級,以及在通信中斷或敵方干擾的情況下,依然能夠獨立完成任務。無人智能體需要具備高度的靈活性和魯棒性,以應對戰場上的各種突發情況。
4、此外,特殊場景任務下的復雜性和多樣性也對無人智能體提出了更高的要求。例如,在偵查任務中,無人智能體需要在敵方火力覆蓋區進行隱蔽行動,同時收集高價值情報;在巡邏任務中,無人智能體需要覆蓋廣泛區域,識別和應對潛在威脅;在補給任務中,無人智能體需要精準導航,確保物資準確送達;在支援任務中,無人智能體需要與地面部隊協同作戰,提供實時情報和火力支援。
5、在此情景下,如何對復雜戰場環境進行高效探索以及開發快速收斂的算法,
6、成為高動態決策場景中無人智能體自主控制的核心挑戰。探索算法需要能夠快30速適應環境變化,迅速找到最優路徑和決策;收斂算法需要在有限的時間內達到
7、最佳狀態,確保無人智能體在執行任務時的高效和準確。總體而言,無人智能體在高動態決策場景中的自主控制,需要綜合運用智能決策算法和強大的環境探索能力,以應對復雜多變的戰場環境和任務需求。
8、深度強化學習是近年來人工智能領域的一個重要研究方向,它通過將深度35學習與強化學習相結合,使智能體能夠在復雜和高維的環境中自主學習決策策
9、略。傳統的強化學習方法在面對高維度狀態和動作空間時往往效率低下,難以處理大規模數據。而深度學習擅長從高維數據中提取特征和進行模式識別,能夠有效解決這一問題。因此,深度強化學習被廣泛應用于游戲、機器人控制、無人機控制等領域。
10、40基于演員-評論家的在線強化學習方法是一類重要的深度強化學習算法。該
11、方法將策略函數和值函數的學習過程分開進行,其中“演員”負責選擇動作,而
12、“評論家”負責評估演員選擇的動作并給出反饋。演員網絡根據狀態生成動作概率分布,評論家網絡則評估當前策略的價值,并利用時序差分誤差來更新值函數。
13、這種方法的優勢在于,它能夠更穩定地進行策略更新,并能有效地處理連續動作45空間。
14、基于演員-評論家架構的算法中,td3算法采用雙重網絡的設計,使用兩個獨立的目標q網絡中最小值來對q值進行估計,有效緩解了策略梯度方法中q
15、值高估問題;同時使用延遲更新策略以穩定網絡更新過程。td3算法在連續控制
16、任務中表現出色,顯著提升了訓練的穩定性和性能。然而,其訓練過程仍然較慢,50需要大量的環境交互數據。sac算法引入最大熵框架旨在同時優化策略的期望回
17、報和策略的熵值,以鼓勵智能體探索;同時使用溫度參數自動調節機制,平衡探索與利用過程。sac算法在需要大量探索的任務中表現出色,然而,復雜的計算和調參過程大大增加了算法收斂的難度。
18、基于演員-評論家的在線強化學習方法收斂的一個重要前提是智能體需要55探索足夠多的環境狀態,即策略不僅僅需要讓智能體獲得更高的環境獎勵,同時
19、需要探索盡可能多樣化的環境,以便于智能體跳出局部最優,取得更好的整體表現。
20、基于內在動機探索的i?cm算法通過獎勵智能體在環境中的探索行為來促進
21、學習過程,其利用環境動力學模型的估計,使用模型預測誤差來定義內在獎勵,60鼓勵智能體探索未知狀態。i?cm算法在稀疏獎勵環境中表現出色,顯著提高了智
22、能體的探索能力。然而,在復雜的環境中,環境動力學模型的訓練可能會帶來額外的計算負擔。rnd算法提出了一種基于隨機網絡的探索方法,通過比較兩個神經網絡的輸出差異來定義內在獎勵。相比于i?cm算法,rnd算法實現簡單,易于
23、訓練,但其內在獎勵的定義依賴于隨機網絡的初始化,導致了探索過程的不穩定。65因此,亟需一種有效的環境探索設計,幫助智能體更穩定、高效地探索環境,取
24、得更好的性能,提高算法的泛用性。
技術實現思路
1、本發明正是為了克服現有基于演員-評論家的在線強化學習方法環境探索70能力的不足,提出了一種針對高動態決策場景智能體探索的強化學習系統及方
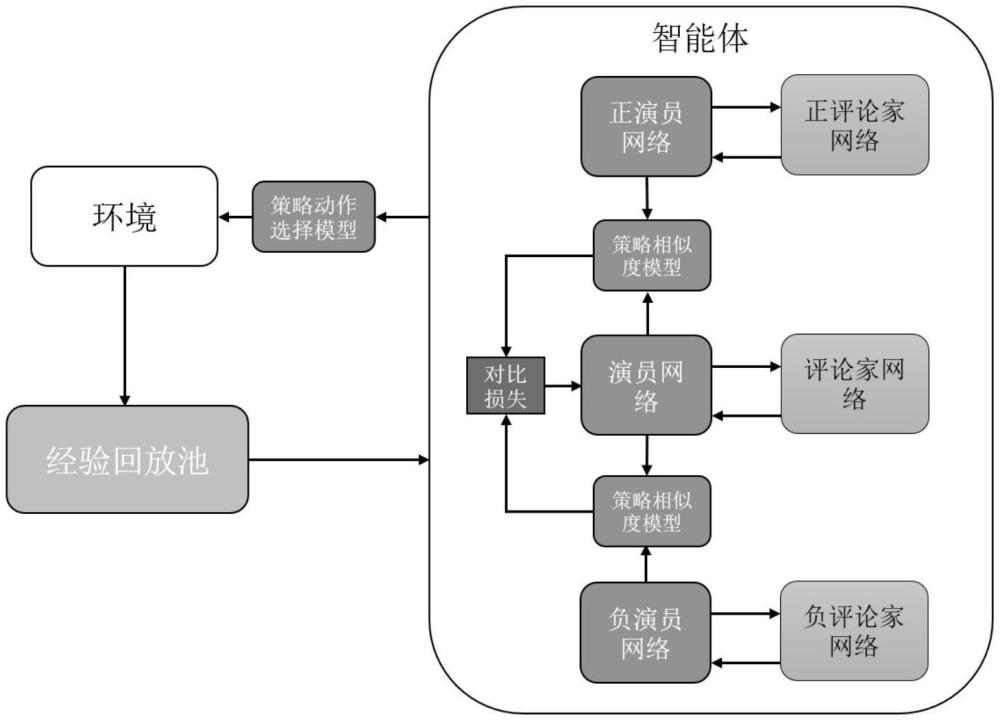
2、法,包括正演員-評論家模型、負演員-評論家模型、演員-評論家模型、策略相似度模型和策略動作選擇模型,通過使用正向策略和負向策略指導主策略的學習,同時最小化主策略與正向策略的接近程度和最大化主策略與負向策略的接
3、近程度,讓主策略以高概率產生高價值動作,低概率產生低價值動作,提升方法75的整體性能;同時,在訓練過程中通過策略動作選擇模型以概率形式選擇執行主
4、策略動作、正向策略動作、負向策略動作,增加動作選擇的多樣性,間接提高探索環境的多樣性,最終實現性能提升。
5、為了實現上述目的,本發明采取的技術方案是:針對高動態決策場景智能體探索的強化學習系統,至少包括正演員-評論家模型、負演員-評論家模型、演員80-評論家模型、策略相似度模型和策略動作選擇模型,
6、所述正演員-評論家模型:包括正演員網絡與正評論家網絡,所述正演員網絡作為正向策略,通過最大化q值,生成正向動作;所述正評論家網絡以最小化生成q值與目標q值的時序差分誤差為目標,用于給出當前狀態下,正演員網絡生成動作的價值;
7、85所述負演員-評論家模型:包括負演員網絡與負評論家網絡,所述負演員網絡作為負向策略,通過最小化q值,生成負向動作;所述負評論家網絡以最小化生成q值與目標q值的時序差分誤差作為目標,用于給出當前狀態下,負演員網絡生成動作的價值;
8、所述演員-評論家模型:包括演員網絡與評論家網絡,所述演員網絡作為主90策略用于生成接近正向策略且遠離負向策略的動作;所述評論家網絡用于給出當前狀態下,演員網絡生成動作的價值;
9、所述策略相似度模型:由自編碼器實現,輸入兩個策略產生的動作,輸出兩個動作的相似度;
10、所述策略動作選擇模型:根據主策略、正向策略、負向策略得到的動作對應95的價值,概率化地選擇動作執行與環境的交互。
11、作為本發明的一種改進,所述演員-評論家模型、正演員-評論家模型、負演員-評論家模型均為深度神經網絡,所述深度神經網絡通過3層全連接層處理向量信號,通過3層卷積層加2層全連接層處理圖像信號。
12、為了實現上述目的,本發明還采取的技術方案是:針對高動態決策場景智能100體探索的正負網絡對比強化學習方法,至少包括訓練和執行兩個階段,
13、針對連續動作場景:所述訓練階段中,智能體動作由策略動作選擇模型從主策略、正向策略和負向策略得到的動作中選擇得到,所述主策略、正向策略、負向策略均由對應演員網絡生成的高斯分布確定,動作通過對高斯分布進行重采樣操作得到;
14、所述執行階段,使用主策略對應高斯分布的均值作為智能體動作;
15、針對離散動作場景:所述訓練階段中,智能體動作由策略動作選擇模型從主策略、正向策略和負向策略得到的動作中選擇得到,所述主策略、正向策略、負向策略均由對應的演員網絡直接生成所有動作被選擇的概率,動作通過對應類別分布進行采樣得到;
16、所述執行階段,使用主策略對應類別分布概率最高的動作作為智能體動作。
17、作為本發明的一種改進,所述正演員網絡的訓練目標為最大化期望q值:
18、
19、其中為正演員網絡的參數,st為t時刻的環境狀態信息,d為經驗回放池,為根據正演員網絡策略得到的動作,表示第j個正評論家網絡,表示第j個正評論家網絡的參數;
20、所述正評論家網絡的訓練目標為最小化價值估計與目標價值的差距:
21、
22、其中表示所有正評論家網絡,φ+表示所有正評論家網絡的參數,st,rt,dt分別表示t時刻的環境狀態信息、智能體采取的動作、環境給予的獎勵、環境的完成情況,st+1表示t+1時刻的環境狀態信息,y+表示由即時獎勵和目標正評論家網絡對于未來價值估計組合而成的目標價值;
23、所述負演員網絡的訓練目標為最小化期望q值:
24、
25、其中為負演員網絡的參數,st為t時刻的環境狀態信息,d為經驗回放池,為根據負演員網絡策略得到的動作,表示第j個負評論家網絡,表示第j個負評論家網絡的參數;
26、所述負評論家網絡的訓練目標為最小化價值估計與目標價值的差距:
27、
28、其中表示所有負評論家網絡,φ-表示所有負評論家網絡的參數,st,rt,dt分別表示t時刻的環境狀態信息、智能體采取的動作、環境給予的獎勵、環境的完成情況,st+1表示t+1時刻的環境狀態信息,y-表示由即時獎勵和目標負評論家網絡對于未來價值估計組合而成的目標價值;
29、所述演員網絡的訓練目標為最小化如下公式:
30、
31、其中為第j個評論家網絡,φj為第j個目標負評論家網絡的參數,at為根據演員網絡策略得到的動作,其中:
32、
33、其中sim為所述策略相似度模型,τ為溫度平衡系數,n為負演員網絡策略產生的負動作樣本總數量,根據st由正演員網絡對應的策略得到,所有根據st由負演員網絡對應的策略得到;
34、所述評論家網絡的訓練目標為最小化價值估計與目標價值的差距:
35、
36、其中qφ表示所有評論家網絡,φ表示所有評論家網絡的參數,st,rt,dt分別表示t時刻的環境狀態信息、智能體采取的動作、環境給予的獎勵、環境的完成情況,st+1表示t+1時刻的環境狀態信息,y表示由即時獎勵和目標評論家網絡對于未來價值估計組合而成的目標價值;
37、作為本發明的另一種改進,所述目標價值y+的計算方式具體為:
38、
39、其中γ為折扣因子,將未來的獎勵做折扣處理,為第j個目標正評論家網絡,為第j個目標正評論家網絡的參數,根據st+1由正演員網絡對應的策略得到;
40、所述目標價值y-的計算方式如下:
41、
42、其中為第j個目標負評論家網絡,為第j個目標負評論家網絡的參數,根據st+1由負演員網絡對應的策略得到;
43、所述目標價值y的計算方式如下:
44、
45、其中為第j個目標評論家網絡,為第j個目標評論家網絡的參數,at+1根據st+1由演員網絡對應的策略得到。
46、作為本發明的又一種改進,所述策略相似度模型的自編碼器的訓練目標為最小化下一步環境狀態預測與實際下一步環境的差距:
47、
48、其中,ae為自編碼器模型,β為自編碼器模型的參數,st為當前時間步環境狀態,動作at來自于主策略,mse為均方誤差函數,st+1為下一時間步的環境狀態,為自編碼器得到的對于下一時間步環境狀態的預測;
49、所述策略相似度計算方法如下:
50、
51、其中表示在環境狀態st下,來自不同策略的動作之間的相似度,d為歐幾里得距離函數,cos為余弦相似度函數,的計算方式如下:
52、
53、其中encoder為所述編碼器模型,st為當前時間步環境狀態,為一策略得到動作。
54、作為本發明的更進一步改進,所述策略動作選擇模型中,動作被選擇的概率以softmax歸一化形式得到,其中主策略對應動作被選擇概率計算方式如下:
55、
56、其中st為當前環境狀態,動作at為通過主策略得到的動作,為通過正向策略得到的動作,為通過負向策略得到的動作;
57、正向策略對應動作被選擇概率計算方式如下:
58、
59、負向策略對應動作被選擇概率計算方式如下:
60、
61、與現有技術相比,本發明具有的有益效果:
62、(1)本發明使用了正向策略、負向策略的設置,并使用動作選擇模型隨機化、概率化動作的選擇,增加了無人智能體動作選擇的多樣性,提高了對于復雜環境,尤其高動態決策環境的探索能力。
63、(2)本發明使用正向策略、負向策略與主策略之間的相似度作為主策略學習的指導,優化了主策略的學習過程,協助主策略跳出局部最優的情況,達到全局最優解,提高了主策略的實際性能。
64、(3)本發明使用正向策略、負向策略對主策略的學習進行指導,增強了策略學習的方向性,協助主策略更快地收斂到全局最優解,提高方法面對復雜環境和多樣化動作空間的收斂速度。
- 還沒有人留言評論。精彩留言會獲得點贊!