基于生成式視覺大模型的行為預(yù)測(cè)方法與系統(tǒng)與流程
本發(fā)明屬于人工智能,具體而言,涉及基于生成式視覺大模型的行為預(yù)測(cè)方法與系統(tǒng)。
背景技術(shù):
1、人員行為預(yù)測(cè)是利用計(jì)算機(jī)視覺和機(jī)器學(xué)習(xí)旨在通過分析人體的動(dòng)態(tài)信息,預(yù)測(cè)其未來的動(dòng)作和行為。這項(xiàng)技術(shù)具有廣泛的應(yīng)用前景,包括智能監(jiān)控、健康監(jiān)測(cè)、人機(jī)交互與體育訓(xùn)練等多個(gè)領(lǐng)域。
2、人員行為預(yù)測(cè)在多個(gè)方面發(fā)揮重要作用。首先,可以利用人體行為預(yù)測(cè)進(jìn)行安全監(jiān)控,在機(jī)場(chǎng)、車站、商場(chǎng)和水站等場(chǎng)所,通過預(yù)測(cè)人員的行為,可以提前識(shí)別潛在的危險(xiǎn)或異常行為,提升公共安全水平。
3、現(xiàn)有人員行為預(yù)測(cè)方法存在以下缺陷:
4、(1)數(shù)據(jù)獲取和處理復(fù)雜:人體動(dòng)作數(shù)據(jù)的獲取需要高精度的傳感器設(shè)備,數(shù)據(jù)量大,處理復(fù)雜,特別是在多攝像頭和多傳感器環(huán)境下,數(shù)據(jù)同步和融合是一個(gè)難點(diǎn);
5、(2)現(xiàn)有的算法的準(zhǔn)確性和實(shí)時(shí)性差,特別是在復(fù)雜的實(shí)際環(huán)境中,算法的魯棒性和適應(yīng)性仍需增強(qiáng);
6、(3)多模態(tài)數(shù)據(jù)融合難度大:人體動(dòng)作行為預(yù)測(cè)往往需要融合視覺和紅外傳感器等多模態(tài)數(shù)據(jù),如何有效地融合這些數(shù)據(jù),以提高預(yù)測(cè)準(zhǔn)確性和穩(wěn)定性,是一個(gè)重要挑戰(zhàn);
7、(4)個(gè)性化預(yù)測(cè)難度大:不同個(gè)體的動(dòng)作行為存在顯著差異,如何進(jìn)行個(gè)性化的行為預(yù)測(cè),以適應(yīng)不同個(gè)體的特點(diǎn),是一個(gè)極待解決的問題。
技術(shù)實(shí)現(xiàn)思路
1、為了解決上述技術(shù)問題,本發(fā)明提供基于生成式視覺大模型的行為預(yù)測(cè)方法與系統(tǒng)。
2、第一方面,本發(fā)明提供了基于生成式視覺大模型的行為預(yù)測(cè)方法,包括:
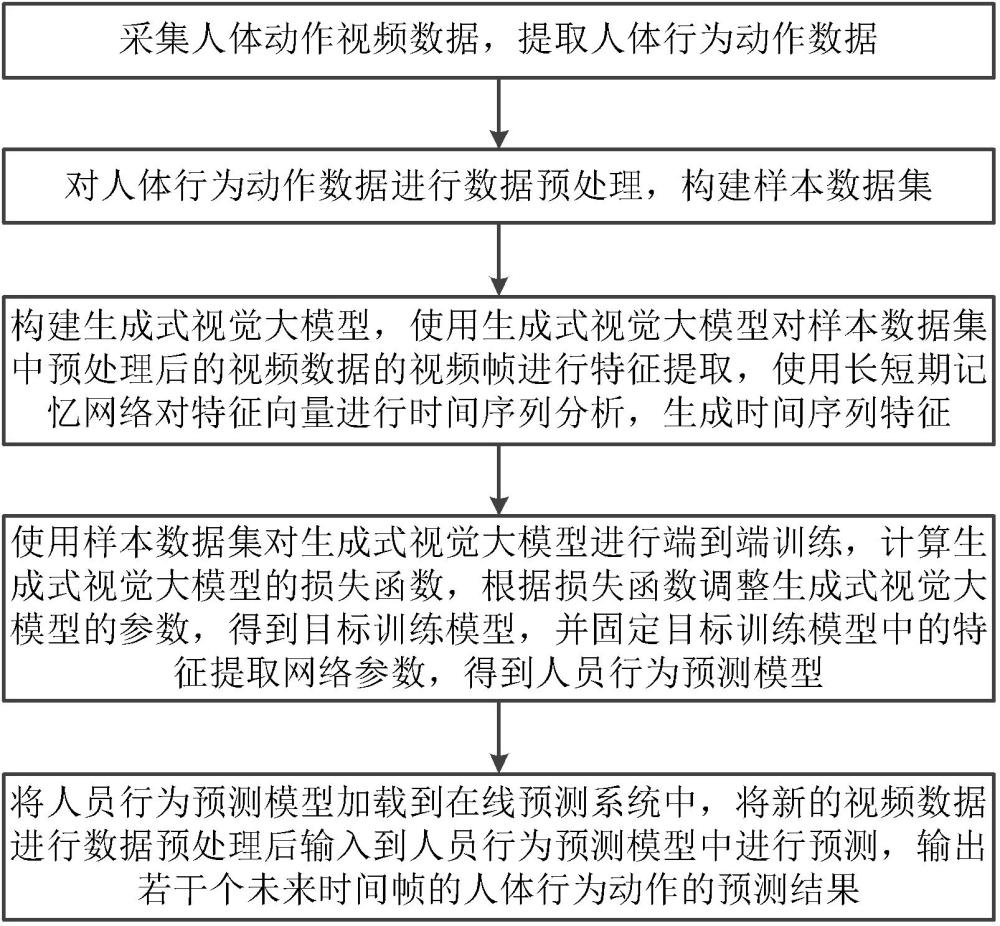
3、采集人體動(dòng)作視頻數(shù)據(jù),提取人體行為動(dòng)作數(shù)據(jù);人體行為動(dòng)作包括人體關(guān)鍵關(guān)節(jié)點(diǎn)位姿、行為動(dòng)作數(shù)據(jù)與交互對(duì)象;行為動(dòng)作數(shù)據(jù)包括運(yùn)動(dòng)數(shù)據(jù)與交互動(dòng)作數(shù)據(jù);
4、對(duì)人體行為動(dòng)作數(shù)據(jù)進(jìn)行數(shù)據(jù)預(yù)處理,構(gòu)建樣本數(shù)據(jù)集;
5、構(gòu)建生成式視覺大模型,使用生成式視覺大模型對(duì)樣本數(shù)據(jù)集中預(yù)處理后的視頻數(shù)據(jù)的視頻幀進(jìn)行特征提取,使用長(zhǎng)短期記憶網(wǎng)絡(luò)對(duì)特征向量進(jìn)行時(shí)間序列分析,生成時(shí)間序列特征;
6、使用樣本數(shù)據(jù)集對(duì)生成式視覺大模型進(jìn)行端到端訓(xùn)練,計(jì)算生成式視覺大模型的損失函數(shù),根據(jù)損失函數(shù)調(diào)整生成式視覺大模型的參數(shù),得到目標(biāo)訓(xùn)練模型,并固定目標(biāo)訓(xùn)練模型中的特征提取網(wǎng)絡(luò)參數(shù),得到人員行為預(yù)測(cè)模型;
7、將人員行為預(yù)測(cè)模型加載到在線預(yù)測(cè)系統(tǒng)中,將新的視頻數(shù)據(jù)進(jìn)行數(shù)據(jù)預(yù)處理后輸入到人員行為預(yù)測(cè)模型中進(jìn)行預(yù)測(cè),輸出若干個(gè)未來時(shí)間幀的人體行為動(dòng)作的預(yù)測(cè)結(jié)果。
8、第二方面,本發(fā)明提供了基于生成式視覺大模型的行為預(yù)測(cè)系統(tǒng),包括采集單元、預(yù)處理單元、模型構(gòu)建單元、模型訓(xùn)練單元與加載單元;
9、采集單元,用于采集人體動(dòng)作視頻數(shù)據(jù),提取人體行為動(dòng)作數(shù)據(jù);人體行為動(dòng)作包括人體關(guān)鍵關(guān)節(jié)點(diǎn)位姿、行為動(dòng)作數(shù)據(jù)與交互對(duì)象;行為動(dòng)作數(shù)據(jù)包括運(yùn)動(dòng)數(shù)據(jù)與交互動(dòng)作數(shù)據(jù);
10、預(yù)處理單元,用于對(duì)人體行為動(dòng)作數(shù)據(jù)進(jìn)行數(shù)據(jù)預(yù)處理,構(gòu)建樣本數(shù)據(jù)集;
11、模型構(gòu)建單元,用于構(gòu)建生成式視覺大模型,使用生成式視覺大模型對(duì)樣本數(shù)據(jù)集中預(yù)處理后的視頻數(shù)據(jù)的視頻幀進(jìn)行特征提取,使用長(zhǎng)短期記憶網(wǎng)絡(luò)對(duì)特征向量進(jìn)行時(shí)間序列分析,生成時(shí)間序列特征;
12、模型訓(xùn)練單元,用于使用樣本數(shù)據(jù)集對(duì)生成式視覺大模型進(jìn)行端到端訓(xùn)練,計(jì)算生成式視覺大模型的損失函數(shù),根據(jù)損失函數(shù)調(diào)整生成式視覺大模型的參數(shù),得到目標(biāo)訓(xùn)練模型,并固定目標(biāo)訓(xùn)練模型中的特征提取網(wǎng)絡(luò)參數(shù),得到人員行為預(yù)測(cè)模型;
13、加載單元,用于將人員行為預(yù)測(cè)模型加載到在線預(yù)測(cè)系統(tǒng)中,將新的視頻數(shù)據(jù)進(jìn)行數(shù)據(jù)預(yù)處理后輸入到人員行為預(yù)測(cè)模型中進(jìn)行預(yù)測(cè),輸出若干個(gè)未來時(shí)間幀的人體行為動(dòng)作的預(yù)測(cè)結(jié)果。
14、在上述技術(shù)方案的基礎(chǔ)上,本發(fā)明還可以做如下改進(jìn)。
15、進(jìn)一步,對(duì)人體行為動(dòng)作數(shù)據(jù)進(jìn)行數(shù)據(jù)預(yù)處理,構(gòu)建樣本數(shù)據(jù)集包括:
16、使用濾波算法對(duì)視頻數(shù)據(jù)進(jìn)行去噪處理,去除視頻中的噪聲;
17、根據(jù)動(dòng)作變化的關(guān)鍵時(shí)刻從視頻中抽取關(guān)鍵幀;
18、利用姿態(tài)估計(jì)算法檢測(cè)人體的關(guān)鍵關(guān)節(jié)點(diǎn),利用檢測(cè)分割算法檢測(cè)環(huán)境物體信息,得到關(guān)鍵關(guān)節(jié)點(diǎn)坐標(biāo)信息和環(huán)境中物體坐標(biāo)信息;
19、根據(jù)關(guān)節(jié)點(diǎn)坐標(biāo)信息和環(huán)境中物體坐標(biāo)信息,計(jì)算人體和物體交互動(dòng)作的概率。
20、進(jìn)一步,交互對(duì)象為人體或環(huán)境物體;運(yùn)動(dòng)數(shù)據(jù)包括走路、跑步與跳躍;交互動(dòng)作數(shù)據(jù)包括抓取、提取與放下。
21、進(jìn)一步,生成式視覺大模型將輸入幀進(jìn)行圖像編碼然后分批圖像嵌入至卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行特征提取,掩膜解碼后的掩膜輸出若干個(gè)未來時(shí)間幀的人體行為動(dòng)作的預(yù)測(cè)結(jié)果。
22、進(jìn)一步,生成式視覺大模型包括圖像標(biāo)記器、視頻標(biāo)記器、文本標(biāo)記器、圖像編碼器、視頻編碼器、文本編碼器、transformer網(wǎng)絡(luò)解碼器、生成器與輸出單元;圖像標(biāo)記器通過圖像編碼器連接transformer網(wǎng)絡(luò)解碼器;視頻標(biāo)記器通過視頻編碼器連接transformer網(wǎng)絡(luò)解碼器;文本標(biāo)記器通過文本編碼器連接transformer網(wǎng)絡(luò)解碼器;轉(zhuǎn)換器解碼器通過生成器連接輸出單元;生成式視覺大模型通過對(duì)圖像、視頻流和文本描述信息進(jìn)行編碼,然后進(jìn)行多模態(tài)信息融合,接著通過transformer網(wǎng)絡(luò)解碼器進(jìn)行解碼,最后通過生成器生成下一時(shí)刻的人體行為動(dòng)作以及對(duì)應(yīng)的文本描述。
23、進(jìn)一步,長(zhǎng)短期記憶網(wǎng)絡(luò)包括輸入門、遺忘門與輸出門;輸入門用于將存儲(chǔ)當(dāng)前信息至細(xì)胞狀態(tài)中;遺忘門用于從上一個(gè)時(shí)間步的隱藏狀態(tài)和當(dāng)前輸入中遺忘信息;輸出門用于決定將信息從當(dāng)前的細(xì)胞狀態(tài)中輸出到下一個(gè)隱藏狀態(tài);細(xì)胞狀態(tài)通過遺忘門與輸入門進(jìn)行更新,通過雙曲正切激活函數(shù)調(diào)節(jié)細(xì)胞狀態(tài)的值。
24、進(jìn)一步,計(jì)算交叉熵?fù)p失函數(shù)值,當(dāng)交叉熵?fù)p失函數(shù)值小于設(shè)定閾值,得到目標(biāo)訓(xùn)練模型。
25、本發(fā)明的有益效果是:
26、(1)本發(fā)明采用生成式視覺模型在大規(guī)模數(shù)據(jù)集上訓(xùn)練,具備強(qiáng)大的特征提取能力,能夠自動(dòng)從原始視頻數(shù)據(jù)中提取高層次的特征,避免了復(fù)雜的手工特征設(shè)計(jì)過程,提高了特征提取的效率和準(zhǔn)確性;
27、(2)采用長(zhǎng)短期記憶網(wǎng)絡(luò)對(duì)特征向量進(jìn)行時(shí)間序列分析,捕捉動(dòng)作的時(shí)間依賴性,處理復(fù)雜的時(shí)間序列數(shù)據(jù),提升了動(dòng)作預(yù)測(cè)的準(zhǔn)確性和穩(wěn)定性,并且通過對(duì)多個(gè)視頻幀的特征向量進(jìn)行時(shí)間序列建模,能夠捕捉動(dòng)作的動(dòng)態(tài)變化,預(yù)測(cè)未來的動(dòng)作趨勢(shì);
28、(3)本發(fā)明通過生成式視覺模型訓(xùn)練,提高對(duì)不同個(gè)體動(dòng)作行為的預(yù)測(cè)精度,通過對(duì)個(gè)體數(shù)據(jù)的專門訓(xùn)練,生成式視覺模型可以提供個(gè)性化的預(yù)測(cè)和建議;
29、(4)采用端到端的訓(xùn)練方法能夠優(yōu)化整個(gè)模型的性能,提高了效率和魯棒性,適應(yīng)多變的實(shí)際應(yīng)用環(huán)境。
技術(shù)特征:
1.基于生成式視覺大模型的行為預(yù)測(cè)方法,其特征在于,包括:
2.根據(jù)權(quán)利要求1所述基于生成式視覺大模型的行為預(yù)測(cè)方法,其特征在于,對(duì)人體行為動(dòng)作數(shù)據(jù)進(jìn)行數(shù)據(jù)預(yù)處理,構(gòu)建樣本數(shù)據(jù)集包括:
3.根據(jù)權(quán)利要求1所述基于生成式視覺大模型的行為預(yù)測(cè)方法,其特征在于,交互對(duì)象為人體或環(huán)境物體;運(yùn)動(dòng)數(shù)據(jù)包括走路、跑步與跳躍;交互動(dòng)作數(shù)據(jù)包括抓取、提取與放下。
4.根據(jù)權(quán)利要求1所述基于生成式視覺大模型的行為預(yù)測(cè)方法,其特征在于,生成式視覺大模型將輸入幀進(jìn)行圖像編碼然后分批圖像嵌入至卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行特征提取,掩膜解碼后的掩膜輸出若干個(gè)未來時(shí)間幀的人體行為動(dòng)作的預(yù)測(cè)結(jié)果。
5.根據(jù)權(quán)利要求1所述基于生成式視覺大模型的行為預(yù)測(cè)方法,其特征在于,生成式視覺大模型包括圖像標(biāo)記器、視頻標(biāo)記器、文本標(biāo)記器、圖像編碼器、視頻編碼器、文本編碼器、transformer網(wǎng)絡(luò)解碼器、生成器與輸出單元;圖像標(biāo)記器通過圖像編碼器連接transformer網(wǎng)絡(luò)解碼器;視頻標(biāo)記器通過視頻編碼器連接transformer網(wǎng)絡(luò)解碼器;文本標(biāo)記器通過文本編碼器連接transformer網(wǎng)絡(luò)解碼器;轉(zhuǎn)換器解碼器通過生成器連接輸出單元;生成式視覺大模型通過對(duì)圖像、視頻流和文本描述信息進(jìn)行編碼,然后進(jìn)行多模態(tài)信息融合,接著通過transformer網(wǎng)絡(luò)解碼器進(jìn)行解碼,最后通過生成器生成下一時(shí)刻的人體行為動(dòng)作以及對(duì)應(yīng)的文本描述。
6.根據(jù)權(quán)利要求1所述基于生成式視覺大模型的行為預(yù)測(cè)方法,其特征在于,長(zhǎng)短期記憶網(wǎng)絡(luò)包括輸入門、遺忘門與輸出門;輸入門用于將存儲(chǔ)當(dāng)前信息至細(xì)胞狀態(tài)中;遺忘門用于從上一個(gè)時(shí)間步的隱藏狀態(tài)和當(dāng)前輸入中遺忘信息;輸出門用于決定將信息從當(dāng)前的細(xì)胞狀態(tài)中輸出到下一個(gè)隱藏狀態(tài);細(xì)胞狀態(tài)通過遺忘門與輸入門進(jìn)行更新,通過雙曲正切激活函數(shù)調(diào)節(jié)細(xì)胞狀態(tài)的值。
7.根據(jù)權(quán)利要求1所述基于生成式視覺大模型的行為預(yù)測(cè)方法,其特征在于,計(jì)算交叉熵?fù)p失函數(shù)值,當(dāng)交叉熵?fù)p失函數(shù)值小于設(shè)定閾值,得到目標(biāo)訓(xùn)練模型。
8.基于生成式視覺大模型的行為預(yù)測(cè)系統(tǒng),其特征在于,包括采集單元、預(yù)處理單元、模型構(gòu)建單元、模型訓(xùn)練單元與加載單元;
技術(shù)總結(jié)
本發(fā)明屬于人工智能技術(shù)領(lǐng)域,涉及基于生成式視覺大模型的行為預(yù)測(cè)方法與系統(tǒng)。該方法包括采集人體動(dòng)作視頻數(shù)據(jù),提取人體行為動(dòng)作數(shù)據(jù);數(shù)據(jù)預(yù)處理;構(gòu)建生成式視覺大模型,特征提取,使用長(zhǎng)短期記憶網(wǎng)絡(luò)進(jìn)行時(shí)間序列分析;端到端訓(xùn)練,計(jì)算損失函數(shù),得到人員行為預(yù)測(cè)模型;輸出若干個(gè)未來時(shí)間幀的人體行為動(dòng)作的預(yù)測(cè)結(jié)果。本發(fā)明采用生成式視覺模型能夠提取高層次的特征,提高了特征提取的效率和準(zhǔn)確性;采用長(zhǎng)短期記憶網(wǎng)絡(luò)對(duì)特征向量進(jìn)行時(shí)間序列分析,提升了動(dòng)作預(yù)測(cè)的準(zhǔn)確性和穩(wěn)定性,能夠捕捉動(dòng)作的動(dòng)態(tài)變化,預(yù)測(cè)未來的動(dòng)作趨勢(shì);采用端到端的訓(xùn)練方法能夠優(yōu)化整個(gè)模型的性能,提高了效率和魯棒性,適應(yīng)多變的實(shí)際應(yīng)用環(huán)境。
技術(shù)研發(fā)人員:張岱,張新,李蘆峰,吳霞
受保護(hù)的技術(shù)使用者:中國鐵塔股份有限公司四川省分公司
技術(shù)研發(fā)日:
技術(shù)公布日:2025/4/24
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!