基于人工智能的視頻異常識別處理方法及系統與流程
本發明涉及視頻異常識別,具體涉及基于人工智能的視頻異常識別處理方法及系統。
背景技術:
1、傳統方法通常依賴于對整個視頻幀的逐幀處理,而不對視頻中的關鍵幀或重點區域進行選擇性分析,這種做法導致計算量非常大,尤其是在處理長時間的視頻或高分辨率視頻時,計算資源消耗極為嚴重;且傳統方法往往依賴于基于規則的檢測算法或簡單的統計方法,這些方法可能無法處理非常復雜的場景,容易產生較多的誤報或漏報,例如,普通的運動檢測算法可能無法區分正常的背景運動和異常事件,導致大量的誤報;并且傳統方法往往處理時空信息較為單一,無法同時考慮到時間和空間維度的關聯,例如,傳統的運動檢測通常依賴于簡單的光流法來分析物體的運動,但沒有能力像現代深度學習方法那樣,從時序的角度理解運動的模式和變化;以及傳統方法的異常檢測往往依賴于固定的背景建模方法,如背景減除法或差異圖法,這些方法在背景復雜或動態變化的環境中表現不佳,例如,在多物體背景下,背景減除法可能誤判正常物體的運動為異常。
技術實現思路
1、本發明所要解決的技術問題在于克服上述現有技術的缺點,提供基于人工智能的視頻異常識別處理方法及系統。
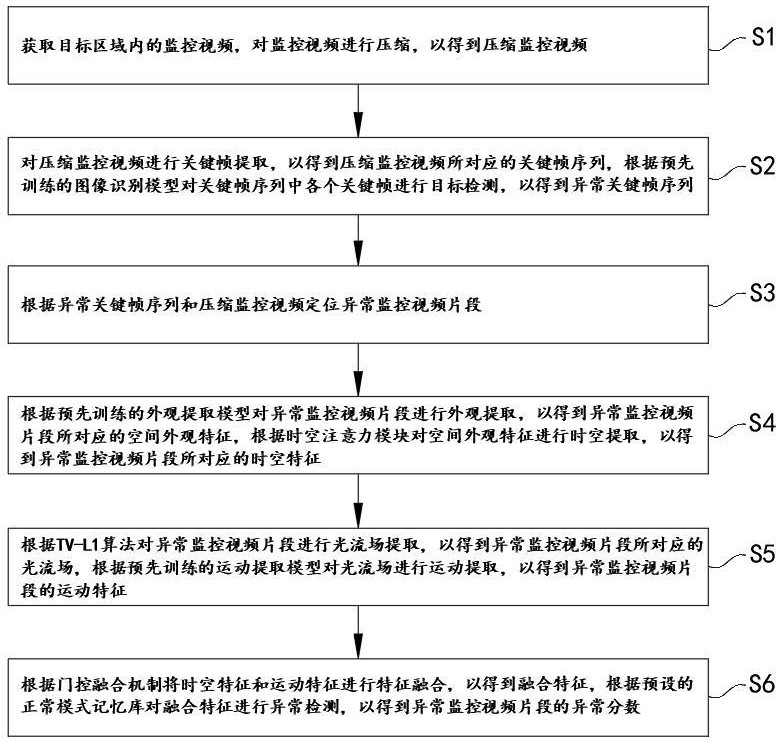
2、解決上述技術問題所采用的技術方案是:基于人工智能的視頻異常識別處理方法,包括:
3、獲取目標區域內的監控視頻,對所述監控視頻進行壓縮,以得到壓縮監控視頻;
4、對所述壓縮監控視頻進行關鍵幀提取,以得到所述壓縮監控視頻所對應的關鍵幀序列,根據預先訓練的圖像識別模型對所述關鍵幀序列中各個關鍵幀進行目標檢測,以得到異常關鍵幀序列;
5、根據所述異常關鍵幀序列和所述壓縮監控視頻定位異常監控視頻片段;
6、根據預先訓練的外觀提取模型對所述異常監控視頻片段進行外觀提取,以得到所述異常監控視頻片段所對應的空間外觀特征,根據時空注意力模塊對所述空間外觀特征進行時空提取,以得到所述異常監控視頻片段所對應的時空特征;
7、根據tv-l1算法對所述異常監控視頻片段進行光流場提取,以得到所述異常監控視頻片段所對應的光流場,根據預先訓練的運動提取模型對所述光流場進行運動提取,以得到所述異常監控視頻片段的運動特征;
8、根據門控融合機制將所述時空特征和所述運動特征進行特征融合,以得到融合特征,根據預設的正常模式記憶庫對所述融合特征進行異常檢測,以得到所述異常監控視頻片段的異常分數。
9、優選的,對所述監控視頻進行壓縮,以得到壓縮監控視頻,包括:
10、將所述監控視頻劃分為多個gop,其中,所述gop中的第1幀為關鍵幀,所述gop中的其余幀為非關鍵幀;
11、根據非關鍵幀自身測量值先驗對所述非關鍵幀進行二次重構,以得到所述非關鍵幀的殘差;
12、根據所述非關鍵幀的殘差經過去噪得到輸出特征;
13、對參考幀特征與非關鍵幀特征進行逐級下采樣,以得到多尺度特征空間,根據時域空間內積注意力融合前一層級的對齊特征,利用動態域先驗知識自適應的細化非關鍵幀特征,以得到非關鍵幀細化特征;
14、對所述非關鍵幀細化特征進行重構,以得到壓縮非關鍵幀,將所述壓縮非關鍵幀和關鍵幀組合,以得到壓縮監控視頻。
15、優選的,重構過程的表達式如下:;其中,表示非關鍵幀的二次重構,表示非關鍵幀的一次重構,表示非關鍵幀測量矩陣,表示參考幀測量矩陣,表示參考幀測量值,表示非關鍵幀測量值,表示在上下文信息的引導下提取靜態域殘差;
16、所述輸出特征的表達式如下:;其中,表示第次提取的重構特征,表示去噪網絡,和表示測量算子,和表示測量算子的轉置,表示特征變換,表示特征逆變換,和表示由關鍵幀與非關鍵幀測量值重復拓展得到,表示第次提取在上下文信息的引導下提取靜態域殘差,表示第次提取由卷積網絡實現的去噪函數。
17、優選的,所述非關鍵幀細化特征的表達式如下:;其中,表示非關鍵幀細化特征,表示由兩個殘差塊構成,用以去除過程引入的噪聲,表示非關鍵幀特征,表示由3個帶有relu的卷積層構成,表示對齊特征的上采樣結果,和表示由1×1卷積實現的,表示哈達瑪積運算。
18、優選的,所述圖像識別模型采用卷積神經網絡,所述外觀提取模型采用3d-resnet,所述運動提取模型采用卷積神經網絡。
19、優選的,所述時空注意力模塊的表達式如下:;其中,表示時空注意力權重,表示激活函數,、、表示查詢、鍵、值矩陣,表示鍵向量維度,用于縮放點積,表示空間外觀特征。
20、優選的,所述融合特征的表達式如下:;其中,表示融合特征,表示sigmoid函數,、表示可學習參數,表示運動特征。
21、優選的,所述異常監控視頻片段的異常分數的計算公式如下:;其中,表示異常監控視頻片段的異常分數,表示異常監控視頻片段中視頻幀的總數,表示正常模式記憶庫,表示相似度平滑因子。
22、解決上述技術問題所采用的技術方案是:基于人工智能的視頻異常識別處理系統,其適用于所述的基于人工智能的視頻異常識別處理方法,包括:
23、視頻壓縮單元,所述視頻壓縮單元用于獲取目標區域內的監控視頻,對所述監控視頻進行壓縮,以得到壓縮監控視頻;
24、圖像識別單元,所述圖像識別單元用于對所述壓縮監控視頻進行關鍵幀提取,以得到所述壓縮監控視頻所對應的關鍵幀序列,根據預先訓練的圖像識別模型對所述關鍵幀序列中各個關鍵幀進行目標檢測,以得到異常關鍵幀序列;
25、視頻定位單元,所述視頻定位單元用于根據所述異常關鍵幀序列和所述壓縮監控視頻定位異常監控視頻片段;
26、時空提取單元,所述時空提取單元用于根據預先訓練的外觀提取模型對所述異常監控視頻片段進行外觀提取,以得到所述異常監控視頻片段所對應的空間外觀特征,根據時空注意力模塊對所述空間外觀特征進行時空提取,以得到所述異常監控視頻片段所對應的時空特征;
27、運動提取單元,所述運動提取單元用于根據tv-l1算法對所述異常監控視頻片段進行光流場提取,以得到所述異常監控視頻片段所對應的光流場,根據預先訓練的運動提取模型對所述光流場進行運動提取,以得到所述異常監控視頻片段的運動特征;
28、異常評分單元,所述異常評分單元用于根據門控融合機制將所述時空特征和所述運動特征進行特征融合,以得到融合特征,根據預設的正常模式記憶庫對所述融合特征進行異常檢測,以得到所述異常監控視頻片段的異常分數。
29、本發明的有益效果如下:(1)本發明通過?壓縮監控視頻,可以大大減少視頻數據的存儲和傳輸負擔,壓縮后的視頻不僅節省了存儲空間,還加快了后續處理步驟的速度,尤其是在監控視頻的實時或大規模處理場景中非常重要,且通過關鍵幀提取可以有效減少視頻分析的計算量,因為關鍵幀通常包含了視頻的主要信息,通過提取關鍵幀并進行?目標檢測,該方法能夠在最短時間內識別出異常場景,而不需要處理整個視頻流,減少了計算資源的浪費;(2)本發明通過使用?外觀提取模型,可以從異常監控視頻片段中提取到關鍵的空間特征,這些特征幫助系統識別和理解異常事件的空間結構,結合?時空注意力模塊,不僅可以分析空間信息,還能增強模型對時序信息的理解,能在時空維度上同時考慮物體的外觀變化和運動變化;通過使用?tv-l1算法?提取光流場可以精確捕捉到視頻中物體的運動模式,進一步通過?運動提取模型?獲取運動特征,從而能夠識別出異常事件中的運動變化,無論是物體的突然移動、速度的變化還是其他異常行為的動態表現;(3)本發明通過將時空特征和運動特征進行融合,充分利用兩者的互補性,提高模型的檢測精度,時空特征主要描述場景的變化,而運動特征則強調對象的動態行為,通過融合這兩種特征,可以更加準確地識別出異常事件,且異常檢測利用預設的正常模式記憶庫,對融合特征進行比對,能夠實現基于歷史數據的智能判斷,快速準確地定位異常行為,提高異常檢測的可靠性。
- 還沒有人留言評論。精彩留言會獲得點贊!