基于強化學習的城市污染源動態分布調控方法與流程
本發明涉及環境污染治理領域,尤其涉及一種基于強化學習的城市污染源動態分布調控方法。
背景技術:
1、空氣污染的來源復雜多樣,包括工業排放、機動車尾氣、建筑揚塵以及居民生活排放等,而不同污染源的排放特性和擴散模式存在顯著差異,因此,如何有效監測、預測并智能調控城市污染源的排放,成為當前環境治理領域的核心問題之一。
2、現有的污染源調控方法主要基于大氣物理擴散模型,如高斯煙羽模型、拉格朗日粒子模型和歐拉網格模型,這些方法依賴于對污染物擴散規律的數學建模,雖然能夠在一定程度上模擬污染物在大氣中的傳播過程,但其適用性受限于模型的假設條件,例如,高斯煙羽模型假設污染物擴散為均勻連續過程,難以應對復雜地形、非穩態氣象條件以及多源污染交互影響,此外,傳統的空氣污染預測方法依賴于統計學分析和機器學習模型,如自回歸移動平均模型、支持向量機以及隨機森林,雖然這些方法在短期預測中具有一定的準確性,但在長期預測、非線性污染演化過程建模以及多污染物協同預測方面仍然存在較大局限性。
3、近年來,深度學習技術在時間序列預測任務中展現出了優越的性能,其中長短期記憶網絡和transformer結構被廣泛應用于污染物濃度預測,然而,標準transformer在處理長時間序列數據時計算開銷巨大,informer網絡通過稀疏自注意力機制減少了計算復雜度,提高了長序列數據的預測能力,已被應用于流量預測、氣象預測等領域,但其在空氣污染預測中的應用仍存在改進空間,例如針對稀疏數據優化模型訓練、提升污染物空間插值精度等問題。
4、在污染源調控方面,傳統的污染物治理措施主要依賴固定調控策略,例如設定行業排放標準、劃定低排放區域、實施單雙號限行等,這些方法雖然能夠在一定程度上降低污染物排放量,但缺乏動態適應能力,無法根據實時污染狀況和氣象條件靈活調整治理方案,此外,單一污染源的優化控制往往無法兼顧多個污染源之間的協同治理,例如工業污染源與機動車排放之間的交互影響未被充分考慮。因此,現有方法難以實現污染源的全局最優控制。
5、近年來,多智能體強化學習在分布式決策優化任務中取得了廣泛應用。例如,在智能交通控制、無人機協作、智能電網調度等領域,多智能體系統通過協同學習優化整體收益,提升決策效率,然而,在污染源調控領域,基于多智能體強化學習的研究仍處于初步階段,主要面臨以下挑戰:(1)污染物擴散的非線性動態特性導致智能體決策的狀態空間復雜;(2)污染源之間的相互作用使得收益函數的優化存在非凸性,難以求解最優解;(3)如何設計合理的獎勵機制,使得智能體在優化自身收益的同時兼顧整體污染治理目標。現有研究大多采用單一強化學習方法,如深度q網絡、近端策略優化等,而未充分考慮污染治理的博弈特性,導致智能體學習的策略可能收斂于局部最優解,無法實現全局污染調控的最優策略。
技術實現思路
1、本發明的一個目的在于提出一種基于強化學習的城市污染源動態分布調控方法,本發明改進的informer網絡進行污染物濃度時空預測,并基于博弈論多智能體強化學習優化污染調控策略,通過改進的informer網絡,處理長時間序列數據,提高污染物濃度預測的精度,并結合空間插值方法計算污染物的擴散趨勢,建立博弈論多智能體強化學習環境,利用納什均衡優化污染源智能體的調控策略,并結合污染歷史數據優化獎勵機制,使得各智能體在動態環境中不斷學習優化,最終收斂至全局最優策略,提高污染源調控方案的可執行性和有效性。
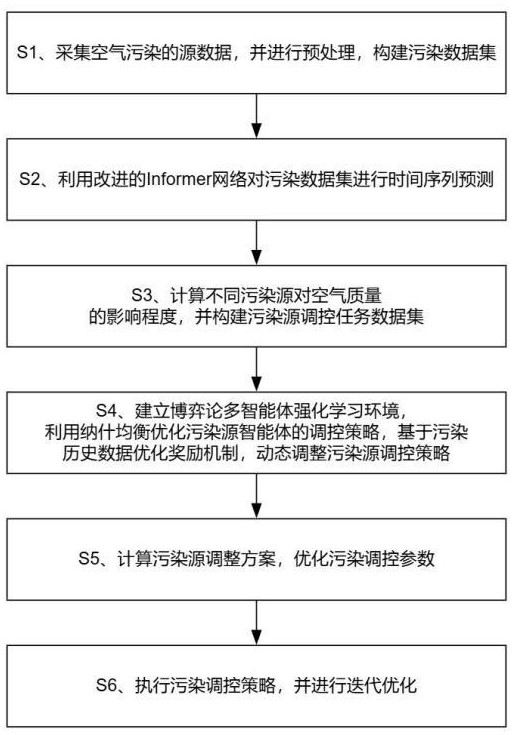
2、根據本發明實施例的一種基于強化學習的城市污染源動態分布調控方法,包括如下步驟:
3、s1、采集空氣污染的源數據,并對所述源數據進行數據清洗、格式轉換和標準化處理,構建污染數據集;
4、s2、利用改進的informer網絡對污染數據集進行時間序列預測,計算不同污染物的未來濃度變化趨勢,并結合空間插值方法計算污染物在不同區域的擴散情況,生成污染物時空分布預測數據;
5、s3、基于污染物時空分布預測數據,構建污染源影響因子矩陣,計算不同污染源對空氣質量的影響程度,并結合污染源排放量和污染擴散特性構建污染源調控任務數據集;
6、s4、基于污染源調控任務數據集,建立博弈論多智能體強化學習環境,設定污染源智能體的狀態空間、動作空間和收益函數,利用納什均衡優化污染源智能體的調控策略,基于污染歷史數據優化獎勵機制,并結合污染治理資源約束條件,動態調整污染源調控策略,生成全局最優調控策略;
7、s5、結合全局最優調控策略,計算污染源調整方案,優化污染調控參數;
8、s6、執行污染調控策略,并對污染調控策略進行迭代優化。
9、可選的,所述源數據包括空氣污染物濃度數據和氣象數據。
10、可選的,所述s2具體包括:
11、s21、構建污染物時間序列數據矩陣,對時間序列數據進行處理,計算污染物濃度的變化速率和加速度:
12、;
13、;
14、其中,表示污染物時間序列數據矩陣,表示時間位置處的污染物濃度,表示總的時間步數,表示地理位置索引,表示時間位置處的污染物濃度變化速率,表示時間位置處的污染物濃度的加速度,表示時間位置處的污染物濃度,表示時間位置處的污染物濃度,表示相鄰時間步的時間間隔,表示時間位置處的污染物濃度變化速率;
15、s22、設定輸入序列長度為,定義輸入矩陣:
16、;
17、其中,表示輸入矩陣,描述輸入的污染物時間序列數據,表示輸入向量,表示時間位置處的污染物濃度,表示時間位置處的污染物濃度變化速率,表示時間位置處的污染物濃度的加速度,表示時間處的氣象數據矩陣;
18、s23、采用改進的informer網絡進行污染物時序預測,對輸入矩陣進行線性變換,映射到高維嵌入向量,所述改進的informer網絡包括數據嵌入層、稀疏自注意力機制和解碼器:
19、;
20、其中,表示高維嵌入向量,表示輸入矩陣,表示嵌入層權重矩陣,表示嵌入層偏置項;
21、s24、采用稀疏自注意力機制對高維嵌入向量進行計算,得到查詢、鍵、值向量,并計算注意力分數:
22、;
23、其中,表示注意力分數,表示查詢向量,表示鍵向量,表示鍵向量的維度,表示指示函數,只有當注意力分數大于閾值時才保留,表示閾值;
24、s25、采用采樣策略,僅保留影響最大的個注意力分數,計算注意力加權后的高維嵌入向量:
25、;
26、其中,表示注意力加權后的高維嵌入向量,表示篩選后的注意力分數,僅保留前個重要時間步對應的注意力分數,表示殘差連接系數,表示值向量,表示采樣策略,僅保留影響最大的個注意力分數;
27、s26、基于改進的informer網絡的解碼器,對注意力加權后的高維嵌入向量通過反向計算進行解碼,生成污染物濃度預測,所述解碼器包括多頭注意力機制、前饋網絡、殘差連接和歸一化層,所述前饋網絡是一個多層感知機:
28、;
29、其中,表示預測的污染物濃度序列,表示時間位置處的污染物濃度預測值,表示預測步長;
30、s27、結合預測污染物濃度預測和空間插值方法計算污染物的空間擴散趨勢,定義污染物空間擴散方程:
31、;
32、其中,表示污染物濃度的時間變化,表示風速影響下的污染物對流擴散項,表示擴散系數,表示風速,表示污染物濃度的拉普拉斯擴散項,表示污染物濃度;
33、s28、基于預測污染物濃度和污染物空間擴散方程,計算未來污染物在不同區域的濃度分布,得到污染物時空分布預測值,生成污染物時空分布預測數據:
34、;
35、其中,表示時間位置處的污染物濃度預測值,表示時間位置處的污染物濃度,表示時間位置處的污染物濃度變化速率,表示時間步長,表示污染物的空間擴散梯度,表示空間步長,表示擴散系數,表示擴散項,表示污染物濃度的拉普拉斯擴散項。
36、可選的,所述s4具體包括:
37、s41、基于污染源調控任務數據集,建立強化學習環境,構建馬爾可夫決策過程:
38、;
39、其中,表示污染源調控任務的馬爾可夫決策過程,表示污染源智能體集合,表示狀態空間,包括污染物濃度、污染變化速率和環境承載能力,表示污染源智能體的動作空間,為污染調整策略,表示狀態轉移概率,描述污染源智能體采取不同調整策略后對污染物濃度的影響,表示收益函數,衡量污染治理的效果,表示折扣因子,控制未來收益的權重;
40、s42、設定污染源智能體的狀態空間和動作空間,所述狀態空間包括污染物濃度、污染物時間變化速率、污染物加速度、環境承載能力和污染源調控權重,所述動作空間選擇調整排放量;
41、s43、構建污染源智能體的收益函數,所述收益函數考慮污染物濃度、污染物時間變化速率和污染源調控權重:
42、;
43、其中,表示污染源智能體的收益函數,、和分別表示污染物濃度、污染物時間變化速率和污染源調控權重的影響權重,表示污染物濃度,表示污染物時間變化速率,表示污染源調控權重;
44、s44、基于強化學習生成污染源調控策略,利用策略梯度方法優化污染源智能體調控策略,計算調控策略梯度:
45、;
46、其中,表示污染源智能體的策略目標函數的調控策略梯度,表示污染源智能體的策略目標函數,表示數學期望,表示污染源智能體的收益函數,表示策略函數,表示策略函數的參數,表示梯度計算,表示污染源智能體的動作空間,表示污染源智能體的狀態空間,表示時間步長;
47、s45、采用納什均衡優化污染源智能體調控策略,在其他智能體策略固定的情況下,計算每個污染源智能體的最優策略:
48、;
49、其中,表示污染源智能體的最優策略,表示策略函數,表示所有其他智能體的最優策略,表示污染源智能體的收益函數,表示折扣因子;
50、s46、基于污染歷史數據優化獎勵機制,構建時間加權獎勵函數:
51、;
52、其中,表示時間加權獎勵函數,表示歷史獎勵影響因子,表示時間衰減因子,控制歷史污染數據的權重,表示累加操作的變量,表示自然指數函數;
53、s47、結合污染治理資源約束條件,動態調整污染源調控策略,利用基于梯度下降方法優化污染源調控策略:
54、;
55、其中,表示調整后的污染源的調控策略,表示污染源的調控策略,表示學習率,控制調控策略調整的步長,表示時間加權獎勵函數對調控策略的梯度;
56、s48、基于強化學習訓練后的智能體策略,生成污染源全局最優調控策略:
57、;
58、其中,表示所有污染源智能體的全局最優調控策略集合,表示污染源智能體的個數。
59、可選的,所述s5具體包括:
60、s51、基于全局最優調控策略中各污染源智能體的最優策略,生成污染源調整向量,所述污染源調整向量包括排放調整幅度、調控起止時間和區域執行權重;
61、s52、構建污染源調控參數優化目標函數,所述目標函數以最小化污染物濃度預測誤差、降低污染擴散強度和提高資源利用效率為優化目標;
62、s53、采用拉格朗日乘子法計算污染源調控參數的最優解;
63、s54、根據計算得到的最優解,生成污染源調整方案,確定各污染源的排放限制值、執行時間段和區域控制優先級。
64、本發明的有益效果是:
65、首先,本發明提出的改進informer?網絡能夠有效克服傳統時間序列預測方法的局限性,利用稀疏自注意力機制降低計算復雜度,使其在處理長時間序列污染物濃度預測任務時具備更強的建模能力,此外,通過構建污染物時間序列數據矩陣并計算污染物濃度變化速率和加速度,本發明在預測未來污染物濃度趨勢時能夠更全面地考慮污染物的時間動態特性,結合空間插值方法,本發明進一步彌補了現有模型在污染物空間擴散建模方面的不足,使得污染物在不同區域的擴散趨勢預測更加精準,為后續污染源調控提供了可靠的數據支持。
66、其次,在污染源調控方面,本發明采用博弈論多智能體強化學習方法,相較于傳統的基于規則的污染控制策略,具備更強的自適應性和全局優化能力,通過構建污染源智能體的狀態空間、動作空間和收益函數,本發明能夠使智能體在復雜污染環境中進行自主學習,并利用納什均衡優化污染源調控策略,使各智能體在不損害整體環境利益的情況下優化自身收益,與現有的單智能體強化學習方法不同,本發明基于博弈論框架,使得不同污染源智能體能夠協同優化調控策略,避免了局部最優問題,提高了污染源調控的整體效果,此外,本發明結合污染歷史數據優化獎勵機制,使得智能體能夠更好地適應不同的污染演化模式,提高了污染調控策略的穩定性和泛化能力。
67、最后,本發明在污染源調控過程中還引入了污染治理資源約束條件,使得最終生成的污染調控策略具備理論最優性,同時,本發明的調控策略能夠動態適應環境變化,例如在不利氣象條件(如高濕度、低風速)下加強污染源控制,在空氣自凈能力較強時適當放寬限制,從而最大化污染治理的經濟效益和環境效益。
68、綜上,本發明通過引入改進的informer網絡提高了污染物濃度預測的準確性,并利用博弈論多智能體強化學習優化污染源調控策略,克服了現有技術中污染預測精度不足、污染調控自適應能力弱的問題,本發明提高了污染物濃度預測的時空分辨率,還通過強化學習策略的不斷優化,使得污染源調控方案能夠動態適應環境變化,實現污染治理的智能化、自主化和全局最優化。
- 還沒有人留言評論。精彩留言會獲得點贊!